机器学习笔记: 时间序列 分解 STL
Posted UQI-LIUWJ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习笔记: 时间序列 分解 STL相关的知识,希望对你有一定的参考价值。
1 前言
STL(’Seasonal and Trend decomposition using Loess‘ ) 是以LOSS 作为平滑方式的时间序列分解
LOSS可以参考机器学习笔记:局部加权回归 LOESS_UQI-LIUWJ的博客-CSDN博客
2 STL分解大致流程和思路
2.1 主体流程
时间序列分解-STL分解法 - 钮甲跳 - 博客园 (cnblogs.com) 中展示了一张STL方法内循环的流程图,我觉得说得蛮好的,附上方便理解
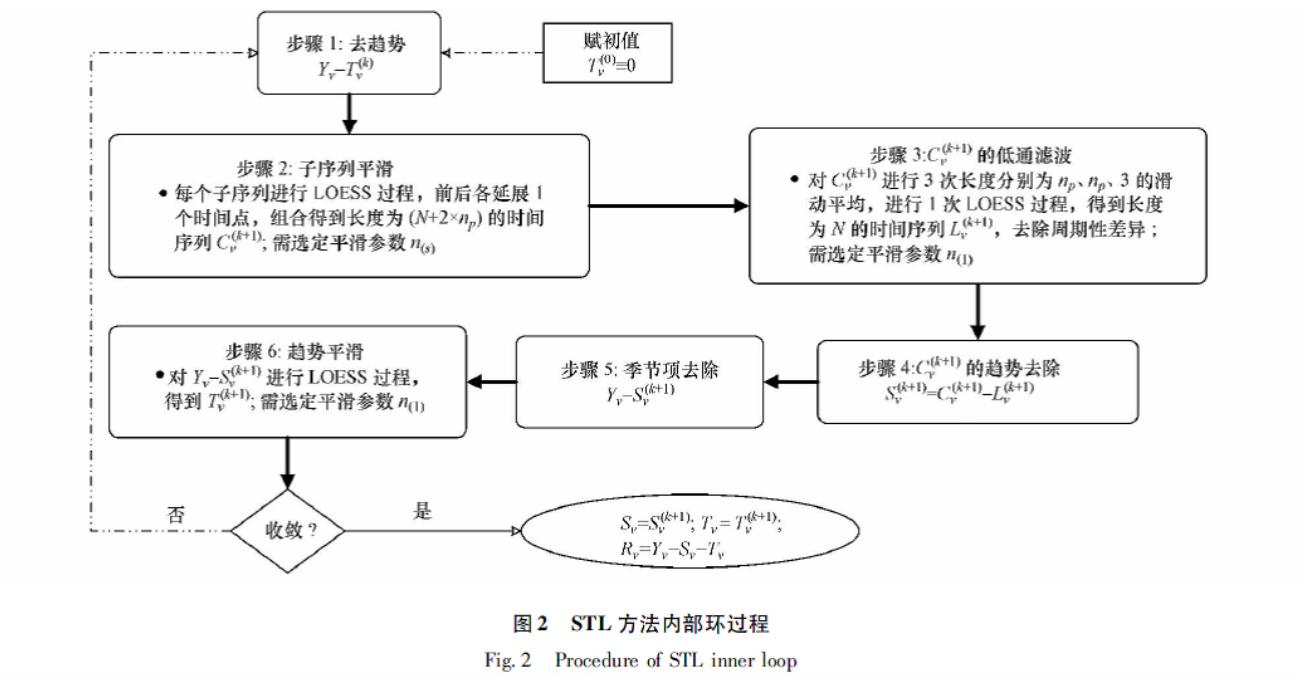
STL分为内循环(inner loop)与外循环(outer loop),其中内循环主要做了趋势拟合与周期分量的计算;外层循环主要用于调节robustness weight。这些在之后会详细提到。
2.2 记号说明
为了方便后文阐述,这里给定几个需要用到的符号:
| Yv | v时刻的时间序列数据(v∈[1,n]) |
| Tv | v时刻的 趋势分量 |
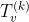 | 内循环第k-1次结束时的趋势分量(初始的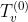 为0) 为0) |
| Sv | v时刻的 周期分量 |
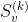 | 内循环第k-1次结束时的周期性分量 |
| Rv | v时刻的 余项 |
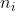 | 内层循环数 |
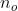 | 外层循环数 |
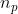 | 时间序列的周期 (一个周期内有几个样本) |
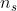 | 内循环第二步中的LOESS平滑参数 (截取多长的步骤来进行加权滑动平均) |
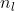 | 内循环第三步中的LOESS平滑参数(周期) |
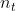 | 内循环第六步中的LOESS平滑参数(趋势) |
-
2.3 内循环
2.3.1 第一步 去趋势
减去上一轮结果的趋势分量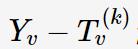
2.3.2 周期子序列平滑
将一个周期内不同时刻的数据汇聚到一块,形成一个子序列(每个周期相同位置的样本点)
比如 1,1+T,1+2T,....这些形成一个子序列;2,2+T,2+2T,....这些形成一个子序列。。。
那么这里我们时间序列周期为,所以一共有个时间序列
我们用平滑参数为的LOSSES,对每个子序列进行局部加权回归,同时每个子序列向前向后各延展一个数值。
然后把这各回归后的时间序列按照时间顺序排列,我们记为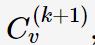 (这是一个从1-
(这是一个从1-
到N+ 的时间序列)
2.3.3 周期子序列的低通量过滤
这里的低通过滤,个人理解是只考虑就近的一些时刻数据的影响
对上一个步骤(2.3.2)的结果序列依次做长度为,,3的滑动平均。
然后做平滑参数为的LOESS,得到一个从1到N的序列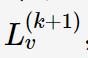
相当于把中的周期特征给过滤掉了。或者说是的趋势分量
2.3.4 求得周期分量
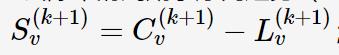
2.3.5 去周期分量
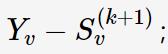
2.3.6 趋势平滑
对于去除周期之后的序列做平滑参数为的LOESS回归,得到趋势分量
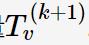
2.4 外循环
主要用于调节robustness weight。如果数据序列中有outlier,则余项会较大
于是我们定义: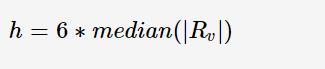
对于位置为v的数据点,其robustness weight为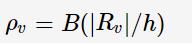
其中B函数为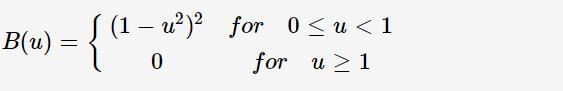
然后每一次迭代的内循环中,在Step 2与Step 6中做LOESS回归时,邻域权重(neighborhood weight)需要乘以ρv,以减少outlier对回归的影响
2.5 流程总结
outer loop:
计算robustness weight;
inner loop:
Step 1 去趋势;
Step 2 周期子序列平滑; (一次LOSSES)
Step 3 周期子序列的低通量过滤; (三次滑动平均,一次LOSSES)
Step 4 去除平滑周期子序列趋势; (计算周期分量)
Step 5 去周期;
Step 6 趋势平滑; (计算趋势分量)
为了使得算法具有足够的鲁棒性,所以设计了内循环与外循环。
特别地,当内循环次数n(i)足够大时,内循环结束时趋势分量与周期分量已收敛;若时序数据中没有明显的outlier,可以将外循环次数n(o)设为0。
论文中给出的一种收敛条件为:
设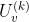 和
和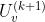 是连续的趋势项或者季节项的迭代,那么如果U满足
是连续的趋势项或者季节项的迭代,那么如果U满足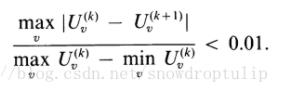 ,则可认为已经收敛
,则可认为已经收敛
3 STL的优缺点
与经典的 SEATS 和 X11 分解方法相比,STL 有几个优点:
- 与 SEATS 和 X11 不同,STL 将处理任何类型的季节性数据,而不仅仅是月度和季度数据。
- 季节性成分允许随时间变化,变化的速度可以由用户控制。
- 趋势周期的平滑度也可以由用户控制。
- 它对异常值具有鲁棒性(即,用户可以指定鲁棒分解),因此偶尔的异常观察不会影响趋势周期和季节性分量的估计。( 但是,它们可能会影响其余部分。 )
另一方面,STL 也有一些缺点:
- 它不会自动处理交易日或日历变化
- 它只提供时间序列加法分解。
4 R语言实现
library(forecast)
y<-ts(c(5,3,3.1,3.2,3.3,3.4,3.5,3.3,3.2,4,4.1,4.2,
6,4,4.1,4.2,4.3,4.4,4.5,4.6,4.7,4.8,4.9,5,
10,9,8,8.5,8.4,8.5,8.6,8.7,8.8,8.9,9,9.5),
start = 2020,
frequency = 12)
stl(y,t.window=13,s.window='periodic',robust=TRUE)
# Call:
# stl(x = y, s.window = "periodic", t.window = 13, robust = TRUE)
#Components
seasonal trend remainder
#Jan 2020 1.71219724 3.281861 5.941485e-03
#Feb 2020 -0.36509768 3.360281 4.816495e-03
#Mar 2020 -0.34451579 3.438701 5.814699e-03
#Apr 2020 -0.31611143 3.518979 -2.867522e-03
#May 2020 -0.28997941 3.599257 -9.277401e-03
#.....
#Dec 2022 0.37439646 9.123976 1.627939e-03
library(ggplot2)
autoplot(stl(y,t.window=13,s.window='periodic',robust=TRUE))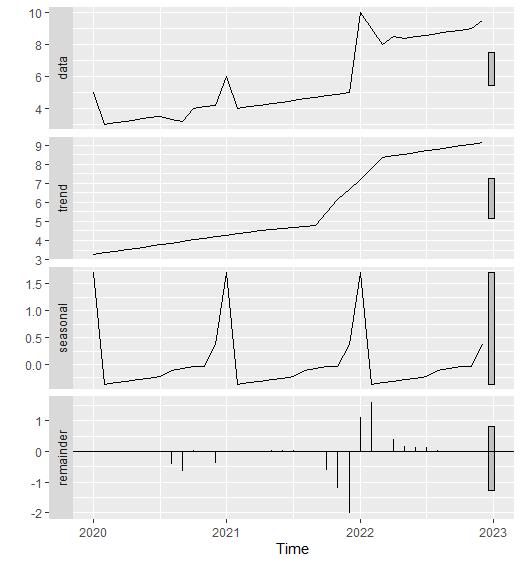
使用 R语言的STL 时要选择的两个主要参数是趋势周期窗口 (t.window) 和季节性窗口 (s.window)。 这些控制趋势周期和季节性成分的变化速度。
较小的值允许更快速的变化。
t.window 和 s.window 都应该是奇数;
t.window 是估计趋势周期时要使用的连续观测数; s.window 是用于估计季节性分量中每个值的连续年数。(LOSSES的平滑参数)
用户必须指定 s.window,因为没有默认值。 将其设置为无限等效于强制季节性分量是periodic的(即,每年都是相同的)。
指定 t.window 是可选的,如果省略,将使用默认值。
4.1 获得某个分量
应该说所有R语言中的时间序列分解都可以这么做
dec=stl(y,t.window=13,s.window='periodic',robust=TRUE)
trendcycle(dec)
#趋势分量
seasonal(dec)
#周期分量
remainder(dec)
#其他分量
seasadj(dec)
#去掉周期分量之后的部分参考文献
时间序列分解-STL分解法 - 钮甲跳 - 博客园 (cnblogs.code
时间序列分解算法:STL - Treant - 博客园 (cnblogs.com)
STL——以鲁棒局部加权回归作为平滑方法的时间序列分解方法_snowdroptulip的博客-CSDN博客_stl分解
以上是关于机器学习笔记: 时间序列 分解 STL的主要内容,如果未能解决你的问题,请参考以下文章