flink kakfa 数据读写到hudi
Posted wudl5566
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了flink kakfa 数据读写到hudi相关的知识,希望对你有一定的参考价值。
1. 运行环境
1.1 版本
| 组件 | 版本 |
|---|---|
| hudi | 10.0 |
| flink | 13.5 |
1.2.flink lib 需要的jar 包
hudi-flink-bundle_2.12-0.10.0.jar
flink-sql-connector-kafka_2.12-1.13.5.jar
flink-shaded-hadoop-2-uber-2.8.3-10.0.jar
下面是所有的jar 包
-rw-r--r-- 1 root root 7802399 1月 1 08:27 doris-flink-1.0-SNAPSHOT.jar
-rw-r--r-- 1 root root 249571 12月 27 23:32 flink-connector-jdbc_2.12-1.13.5.jar
-rw-r--r-- 1 root root 359138 1月 1 10:17 flink-connector-kafka_2.12-1.13.5.jar
-rw-r--r-- 1 hive 1007 92315 12月 15 08:23 flink-csv-1.13.5.jar
-rw-r--r-- 1 hive 1007 106535830 12月 15 08:29 flink-dist_2.12-1.13.5.jar
-rw-r--r-- 1 hive 1007 148127 12月 15 08:23 flink-json-1.13.5.jar
-rw-r--r-- 1 root root 43317025 2月 6 20:51 flink-shaded-hadoop-2-uber-2.8.3-10.0.jar
-rw-r--r-- 1 hive 1007 7709740 12月 15 06:57 flink-shaded-zookeeper-3.4.14.jar
-rw-r--r-- 1 root root 3674116 2月 13 14:08 flink-sql-connector-kafka_2.12-1.13.5.jar
-rw-r--r-- 1 hive 1007 35051557 12月 15 08:28 flink-table_2.12-1.13.5.jar
-rw-r--r-- 1 hive 1007 38613344 12月 15 08:28 flink-table-blink_2.12-1.13.5.jar
-rw-r--r-- 1 root root 62447468 2月 6 20:44 hudi-flink-bundle_2.12-0.10.0.jar
-rw-r--r-- 1 root root 17276348 2月 6 20:51 hudi-hadoop-mr-bundle-0.10.0.jar
-rw-r--r-- 1 root root 1893564 1月 1 10:17 kafka-clients-2.0.0.jar
-rw-r--r-- 1 hive 1007 207909 12月 15 06:56 log4j-1.2-api-2.16.0.jar
-rw-r--r-- 1 hive 1007 301892 12月 15 06:56 log4j-api-2.16.0.jar
-rw-r--r-- 1 hive 1007 1789565 12月 15 06:56 log4j-core-2.16.0.jar
-rw-r--r-- 1 hive 1007 24258 12月 15 06:56 log4j-slf4j-impl-2.16.0.jar
-rw-r--r-- 1 root root 724213 12月 27 23:23 mysql-connector-java-5.1.9.jar
1.3 flink-conf.yaml 的 checkpoints 配置
参数说明
| 参数 | 值 | 说明 |
|---|---|---|
| state.backend | rocksdb | State backend的配置 |
| state.backend.incremental | true | 检查点中保存的数据是否采用增量的方式 |
| state.checkpoints.dir | hdfs://node01.com:8020/flink/flink-checkpoints | 用于指定checkpoint的data files和meta data存储的目录 |
| state.savepoints.dir | hdfs://node01.com:8020/flink-savepoints | SavePoint 存储的位置 |
| classloader.check-leaked-classloader | false | 如果一个作业的用户类加载器在作业终止后使用,则装入类的尝试将失败。这通常是由滞留线程或行为不当的库泄漏类加载器造成的,这也可能导致其他作业使用类加载器。只有当泄漏阻止了进一步的作业运行时,才应该禁用此检查. |
| classloader.resolve-order | parent-first | 定义从用户代码加载类时的类解析策略,即首先检查用户代码jar(“child-first”)还是应用程序类路径【application classpath】(“parent-first”)。默认设置指示首先从用户代码jar加载类,这意味着用户代码jar可以包含和加载不同于Flink使用的依赖项(传递) |
| execution.checkpointing.interval | 3000 | Checkpoint间隔时间,单位为毫秒。 |
#参数
state.backend: rocksdb
state.backend.incremental: true
state.checkpoints.dir: hdfs://node01.com:8020/flink/flink-checkpoints
state.savepoints.dir: hdfs://node01.com:8020/flink-savepoints
classloader.check-leaked-classloader: false
classloader.resolve-order: parent-first
execution.checkpointing.interval: 3000
2.场景
kafka ----> flink sql ----> hudi —> flink sql read hudi

3. flink sql client 客户端模式
3.1 进入客户端
[root@node01 bin]# ./sql-client.sh embedded -j /opt/module/flink/flink-1.13.5/lib/hudi-flink-bundle_2.12-0.10.0.jar
Setting HBASE_CONF_DIR=/etc/hbase/conf because no HBASE_CONF_DIR was set.
3.2创建kafka 表
Flink SQL> CREATE TABLE order_kafka_source (
> orderId STRING,
> userId STRING,
> orderTime STRING,
> ip STRING,
> orderMoney DOUBLE,
> orderStatus INT
> ) WITH (
> 'connector' = 'kafka',
> 'topic' = 'hudiflink',
> 'properties.bootstrap.servers' = '192.168.1.161:6667',
> 'properties.group.id' = 'hudi-1001',
> 'scan.startup.mode' = 'latest-offset',
> 'format' = 'json',
> 'json.fail-on-missing-field' = 'false',
> 'json.ignore-parse-errors' = 'true'
> );
[INFO] Execute statement succeed.
3.3 创建hudi 写入表
Flink SQL> CREATE TABLE order_hudi_sink (
> orderId STRING PRIMARY KEY NOT ENFORCED,
> userId STRING,
> orderTime STRING,
> ip STRING,
> orderMoney DOUBLE,
> orderStatus INT,
> ts STRING,
> partition_day STRING
> )
> PARTITIONED BY (partition_day)
> WITH (
> 'connector' = 'hudi',
> 'path' = 'hdfs://192.168.1.161:8020/hudi-warehouse/order_hudi_sink',
> 'table.type' = 'MERGE_ON_READ',
> 'write.operation' = 'upsert',
> 'hoodie.datasource.write.recordkey.field'= 'orderId',
> 'write.precombine.field' = 'ts',
> 'write.tasks'= '1',
> 'compaction.tasks' = '1',
> 'compaction.async.enabled' = 'true',
> 'compaction.trigger.strategy' = 'num_commits',
> 'compaction.delta_commits' = '1'
> );
[INFO] Execute statement succeed.
3.4 flink 实时读取表
Flink SQL> CREATE TABLE read_hudi2(
> orderId STRING PRIMARY KEY NOT ENFORCED,
> userId STRING,
> orderTime STRING,
> ip STRING,
> orderMoney DOUBLE,
> orderStatus INT,
> ts STRING,
> partition_day STRING
> )
> PARTITIONED BY (partition_day)
> WITH (
> 'connector' = 'hudi',
> 'path' = 'hdfs://192.168.1.161:8020/hudi-warehouse/order_hudi_sink',
> 'table.type' = 'MERGE_ON_READ',
> 'read.streaming.enabled' = 'true',
> 'read.streaming.check-interval' = '4'
> );
[INFO] Execute statement succeed.
3.5 实时流式 插入
Flink SQL> INSERT INTO order_hudi_sink
> SELECT
> orderId, userId, orderTime, ip, orderMoney, orderStatus,
> substring(orderId, 0, 17) AS ts, substring(orderTime, 0, 10) AS partition_day
> FROM order_kafka_source ;
[INFO] Submitting SQL update statement to the cluster...
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: ea29591aeb04310b88999888226c04b2
如:
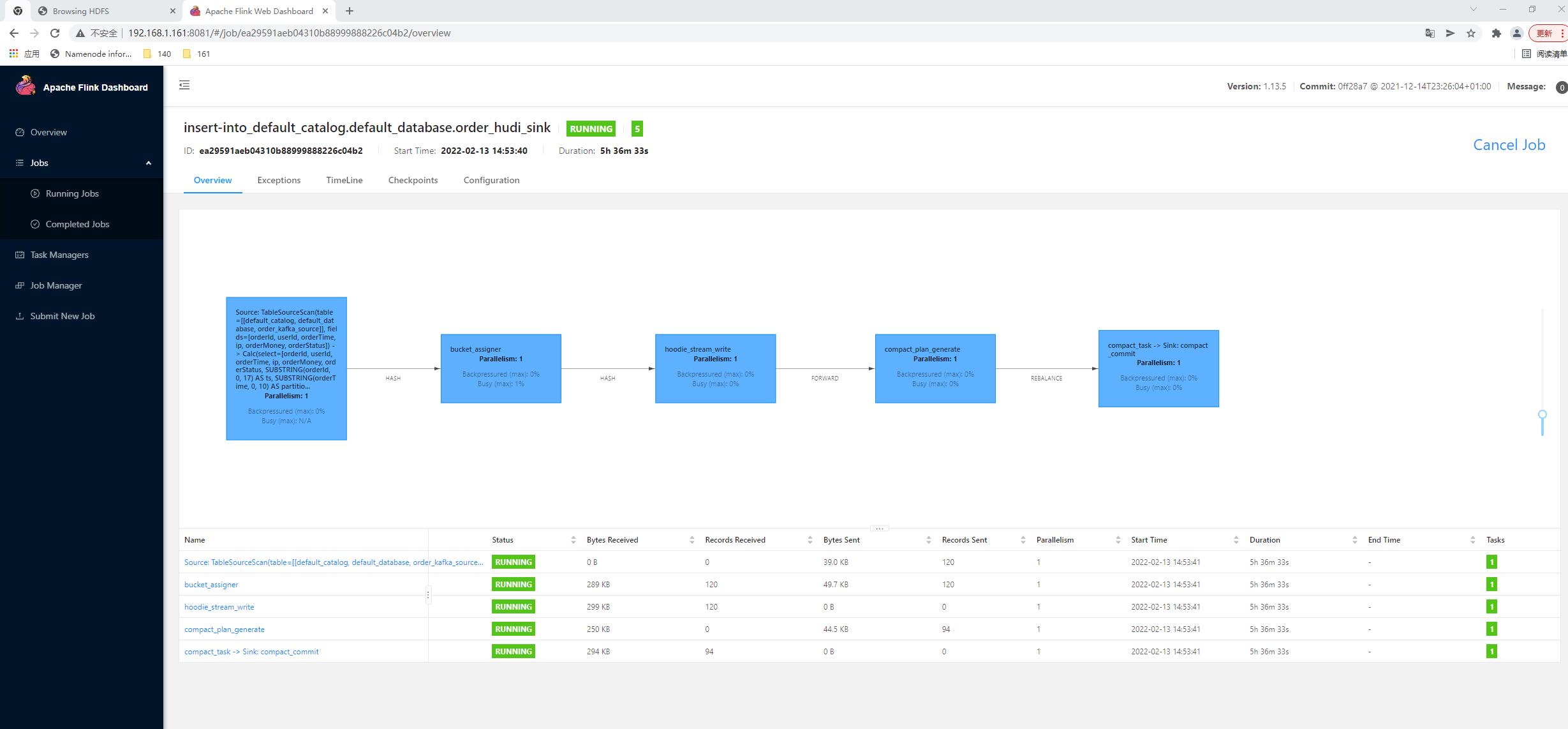
4.结果

5.代码实现
package com.wudl.hudi.sink;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import static org.apache.flink.table.api.Expressions.$;
/**
* @author :wudl
* @date :Created in 2022-02-07 22:56
* @description:
* @modified By:
* @version: 1.0
*/
public class FlinkKafkaWriteHudi
public static void main(String[] args) throws Exception
// 1-获取表执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// TODO: 由于增量将数据写入到Hudi表,所以需要启动Flink Checkpoint检查点
env.setParallelism(1);
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.inStreamingMode() // 设置流式模式
.build();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, settings);
// 1.1 开启CK
env.enableCheckpointing(5000L);
env.getCheckpointConfig().setCheckpointTimeout(10000L);
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//正常Cancel任务时,保留最后一次CK
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//重启策略
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 5000L));
//状态后端
env.setStateBackend(new FsStateBackend("hdfs://192.168.1.161:8020/flink-hudi/ck"));
//设置访问HDFS的用户名
System.setProperty("HADOOP_USER_NAME", "root");
// 2-创建输入表,TODO:从Kafka消费数据
tableEnv.executeSql(
"CREATE TABLE order_kafka_source (\\n" +
" orderId STRING,\\n" +
" userId STRING,\\n" +
" orderTime STRING,\\n" +
" ip STRING,\\n" +
" orderMoney DOUBLE,\\n" +
" orderStatus INT\\n" +
") WITH (\\n" +
" 'connector' = 'kafka',\\n" +
" 'topic' = 'hudiflink',\\n" +
" 'properties.bootstrap.servers' = '192.168.1.161:6667',\\n" +
" 'properties.group.id' = 'gid-1002',\\n" +
" 'scan.startup.mode' = 'latest-offset',\\n" +
" 'format' = 'json',\\n" +
" 'json.fail-on-missing-field' = 'false',\\n" +
" 'json.ignore-parse-errors' = 'true'\\n" +
")"
);
// 3-转换数据:可以使用SQL,也可以时Table API
Table etlTable = tableEnv
.from("order_kafka_source")
// 添加字段:Hudi表数据合并字段,时间戳, "orderId": "20211122103434136000001" -> 20211122103434136
.addColumns(
$("orderId").substring(0, 17).as("ts")
)
// 添加字段:Hudi表分区字段, "orderTime": "2021-11-22 10:34:34.136" -> 021-11-22
.addColumns(
$("orderTime").substring(0, 10).as("partition_day")
);
tableEnv.createTemporaryView("view_order", etlTable);
// 4-创建输出表,TODO: 关联到Hudi表,指定Hudi表名称,存储路径,字段名称等等信息
tableEnv.executeSql(
"CREATE TABLE order_hudi_sink (\\n" +
" orderId STRING PRIMARY KEY NOT ENFORCED,\\n" +
" userId STRING,\\n" +
" orderTime STRING,\\n" +
" ip STRING,\\n" +
" orderMoney DOUBLE,\\n" +
" orderStatus INT,\\n" +
" ts STRING,\\n" +
" partition_day STRING\\n" +
")\\n" +
"PARTITIONED BY (partition_day)\\n" +
"WITH (\\n" +
" 'connector' = 'hudi',\\n" +
// " 'path' = 'file:///D:/flink_hudi_order',\\n" +
" 'path' = 'hdfs://192.168.1.161:8020/hudi-warehouse/order_hudi_sink' ,\\n" +
" 'table.type' = 'MERGE_ON_READ',\\n" +
" 'write.operation' = 'upsert',\\n" +
" 'hoodie.datasource.write.recordkey.field'= 'orderId',\\n" +
" 'write.precombine.field' = 'ts',\\n" +
" 'write.tasks'= '1'\\n" +
")"
);
tableEnv.executeSql("select *from order_hudi_sink").print();
// 5-通过子查询方式,将数据写入输出表
tableEnv.executeSql(
"INSERT INTO order_hudi_sink " +
"SELECT orderId, userId, orderTime, ip, orderMoney, orderStatus, ts, partition_day FROM view_order"
);
以上是关于flink kakfa 数据读写到hudi的主要内容,如果未能解决你的问题,请参考以下文章