Dask核心功能介绍及与Spark的比较
Posted 咬定青松
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Dask核心功能介绍及与Spark的比较相关的知识,希望对你有一定的参考价值。
从谷爱凌身上,我们看到了支撑她走上神坛的4个因素:
优良的基因
衣食无忧的生活
兴趣自由
智力向导
其中基因是基础,也可以说是最重要的。不要小看基因的一点儿优化,哪怕一丁点的改良就可能超越当前地球在世人类,更别说石头缝中蹦出来的孙悟空几天就能学会翻筋斗,再看看比他多学了多少年的师兄的水平如何?再看看日本的羽生结弦,因为受制于身体极限,一直受困于4A,终究无法突破,也许他缺的就是那么一点儿基因改良。衣食无忧意味着财务自由,可以随心所欲选择自己感兴趣的事情,而无心理包袱,就像羽生结弦已经有了几次卫冕冠军的成就,再多一次,再说一次都无所谓,可以放纵去挑战4A。谷爱凌的生活环境加上精英父母及其生活圈子,相信她可以接触到全世界最优秀的教练、教育和培训,这可以让她避免很多弯路。
一、Dask组成部分
Dask是一款用Python开发的轻量级并行计算库,Dask由两部分组成:
并行数据集合:比如array、dataframes和lists等。它们扩展了NumPy, Pandas 或者 Python iterators接口,能够支持超过内存的数据集处理。
动态任务调度:同Airflow、Luigi和Celery类似,但是专门为计算优化过了,用于交互式计算场景。上述并行数据集合就运行在调度系统之上。
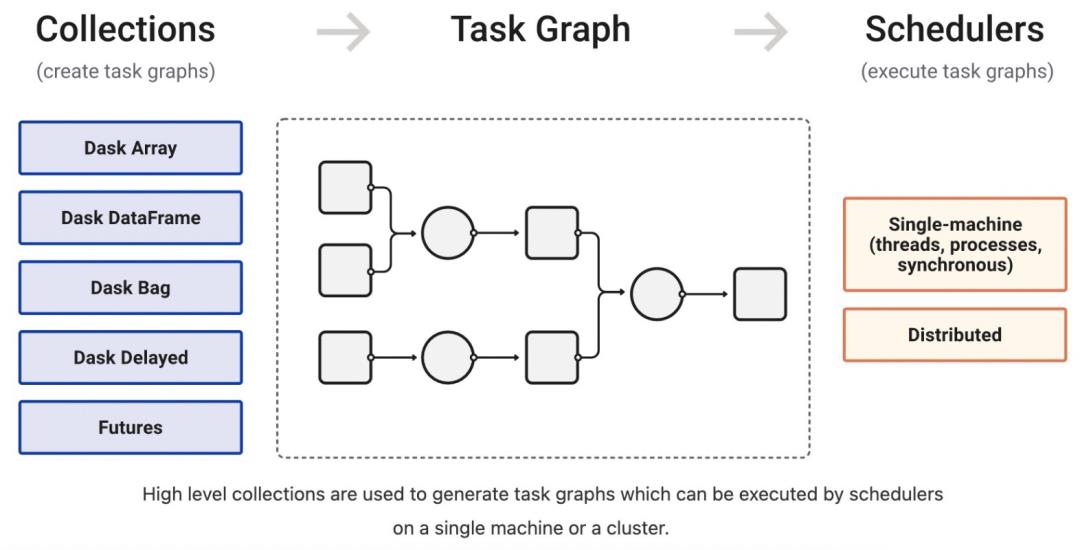
就Dask本身,并行数据集合和动态任务调度构成了其高层和低层视角。Dask 的高层数据集合可以看做 NumPy和Pandas在大数据集下的替代品。Dask低层调度系统提供基于Task Graph的并行动态任务调度,可以看做在复杂计算场景下Python线程或多进程库( threading or multiprocessing )的替代品。总体上,Dask具备以下优点:
熟悉(Familiar):Dask高层提供了并行化版本的NumPy array 和 Pandas DataFrame,但使用方式跟NumPy和Pandas几乎保持不变,开发者使用起来更容易接受
灵活(Flexible):Dask地层提供了任务调度系统接口,方便自定义类型的计算负载和跟其他项目集成
原生(Native):分布式计算使用纯粹的Python实现,能够容易地访问Python数据对象
快速(Fast):数值计算操作低开销、低延迟、低序列化
伸缩(Scalable):支持小到单机单核运算模式,多到上千核的集群运算模式
响应(Responsive):为交互式计算而设计,提供快速反馈和诊断
Task Graph可以看做是高层数据集合跟底层调度的衔接部分,高层数据集合对象 Array、DataFrame和Bag以及delay和future自动将大任务拆分成更小的子任务,并提交到调度系统去执行。不同于Array、DataFrame和Bag,利用delay和future能够实现更复杂的算法。
二、Dask 并行数据集合
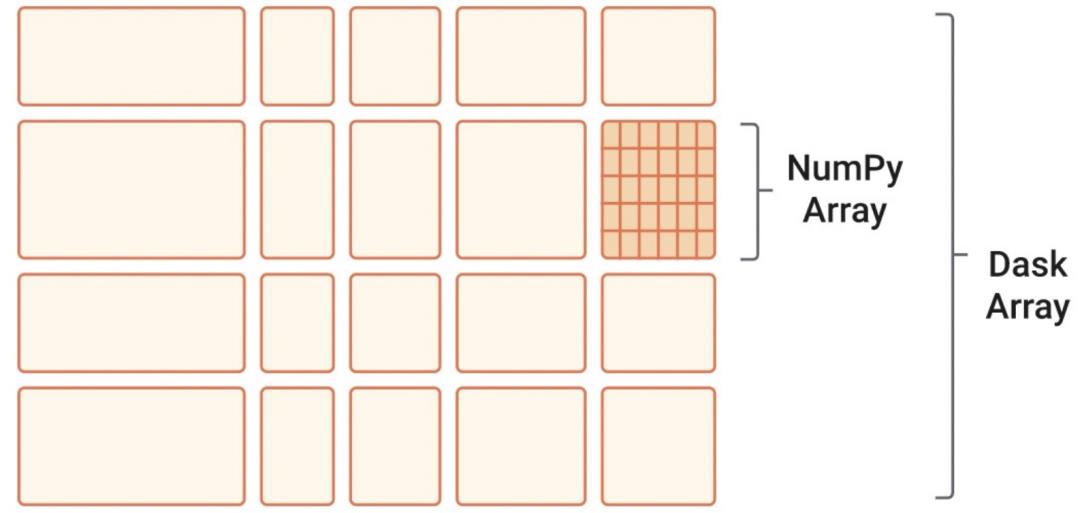
1. Array
Array是一个使用分块算法实现了NumPy ndarray的接口子集。
import dask.array as da
x = da.random.random((10000, 10000), chunks=(1000, 1000))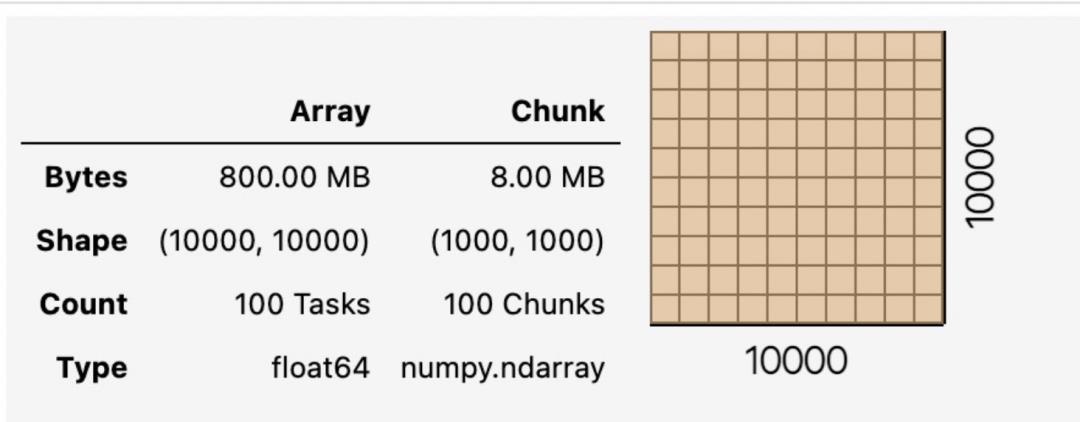
2. Bag
Bag是允许重复的无序集合的数学名称,是multiset的友好代名词。bag或者multiset是set 集合概念的泛化,不像集合set,bag允许重复,作为对比,看几个例子:
list: ordered collection with repeats, [1, 2, 3, 2]
set: unordered collection without repeats, 1, 2, 3
bag: unordered collection with repeats, 1, 2, 2, 3
可见,bag跟list很像,但不保证顺序。举个创建bag的简单例子:
import dask.bag as db
>>> b = db.from_sequence([1, 2, 3, 4, 5, 6], npartitions=2)
>>> b
dask.bag<from_sequence, npartitions=2>Dask Bag在普通Python 对象集合上实现类似map, filter, fold 和groupby这样的操作,就像PySpark RDD那样,使用Bag能够在少量内存上实现并行操作。Dask Bags 常被用于日志文件、JSON格式的记录或其他用户定义的Python对象上的简单预处理,比如下例中处理JSON文件:
import dask.bag as db
import json
b0 = db.read_text('data/*.json').map(json.loads)
b0.count().compute() # Count total number of records
b=b0.filter(lambda record: record['age'] > 30).take(2) # Select only people over 30
b=b.map(json.dumps) # Convert Python objects to text
b.to_textfiles('data/processed.*.json')) # Write to local disk3. DataFrame
Dask DataFrame是Pandas DataFrame的分布式版本,它将沿着index索引分区的多个Pandas DataFrame整合起来,如下图示例所示:

import dask
import dask.dataframe as dd
df = dask.datasets.timeseries()timeseries创建了一个2000年1月份、每秒1条的时序数据,每条记录4个字段(id,name,x,y):

f = df[df.y > 0].groupby('name').x.std().compute()

Array、DataFrame和Bag都能够支持在超过内存的数据集上并行执行,为此,它们被实现为延后执行模式,像上面示例中那样,只有当明确调用compute方法才真正触发计算。
三、任务依赖图
通常人类写完程序,然后再用编译器或解释器(如javac、python等)编译或解释执行,但有时人类不希望按照机器自动编排的执行方式,而希望按照自己的方式来分析、优化和执行程序,这样,原来属于编译器或解释器的职责就转移到人类开发者身上。进而,程序的结构也被明确地表示为程序本身的一部分。在用户空间进行并行化的一种常见方式就是借助任务调度(task scheduling)。在任务调度中,我们把计算任务分解为大小适中的子任务或计算单元(一般是函数调用),这些子任务往往存在一种依赖关系,表现为有向无环图(DAG),Dask在内部通过一种编码规范将这个图用普通的字典(dict)、元组(tuple)和函数(function)来表示。图中的每个节点就是子任务或计算单元,节点的边表示节点的数据产出和消费关系。然后通过任务调度在满足节点依赖关系的前提下,尽可能提升独立节点的并发性来最有效率地执行整个DAG。举个例子:
def inc(i):
return i + 1
def add(a, b):
return a + b
x = 1
y = inc(x)
z = add(y, 10)上述计算逻辑的任务依赖图在 Dask 内部表示为这样一个字典结构:
d = 'x': 1,
'y': (inc, 'x'),
'z': (add, 'y', 10)其中key为任意可哈希的非Task类型的标识值,value为Task类型的元组,如:
(add, 'x', 'y')其中元组第一个元素是可调用的函数,后续元素是函数参数,参数既可以是key、常量值、Task类型的实例或以上的参数列表。
用可视化图表示为:

Dask的所有调度的入口函数是get,通过get函数能够直接跟调度器交互,获取任意节点的计算结果值,比如通过依赖图的key,调用get方法可以触发结果计算:

虽然可以将任务依赖图格式编码为普通的Python dict,tuple,function基本对象,能够将其跟其他集合隔离开来,但是在开发值很少直接操作依赖图,除非想实现自定义Module。实际上,使用dask.delay是更好的选择:
import dask
@dask.delayed
def inc(x):
return x + 1
@dask.delayed
def add(x, y):
return x + y
x=1
y = inc(x)
z=add(y,10)
z.visualize()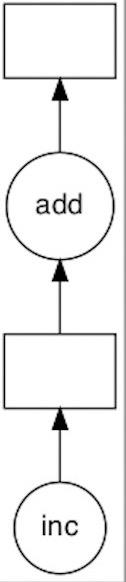
通过可视化可以清楚地看到跟上面的依赖图类似,不同于上例中同步调用,这里使用了delay方法注解,将任务执行变为延后执行:当明确调用z.compute()才会触发DAG调度,这带来的好处是并行化。跟delay相对应的是future,它扩展了 Python concurrent.futures 接口,立即返回一个指向远程结果的引用,但是当请求该结果时,远程结果可能还没有完成,但最终任务会结束,执行结果存放在远程的thread/process/worker 之中,可以通过result方法获取:
from dask.distributed import Client
client = Client() # start local workers as processes
# or
client = Client(processes=False) # start local workers as threads
def inc(x):
return x + 1
def add(x, y):
return x + y
a = client.submit(inc, 10) # calls inc(10) in background thread or process
a.result() # blocks until task completes and data arrives四、 动态任务调度
上面介绍的高层数据集合:Dask Array、Dask DataFrame、Dask Bag以及delay和future接口都会自动创建任务依赖图,任务依赖图最终被提交到任务调度执行。
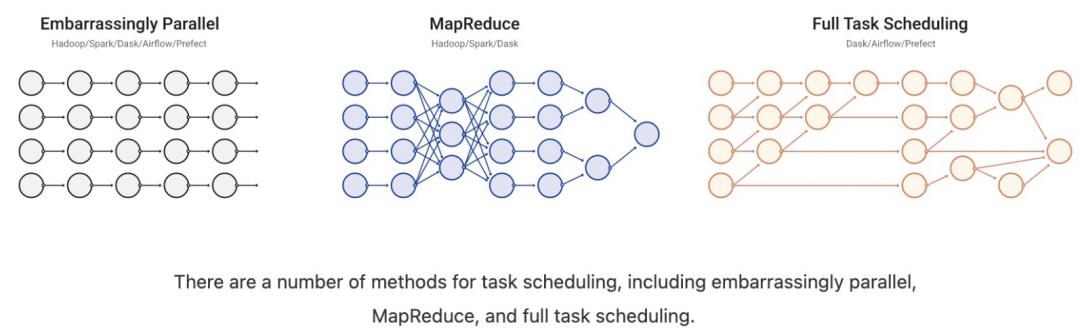
有很多种任务调度方法,比如embarrassingly parallel、MapReduce和full task scheduling。full task scheduling就完全依赖任务调度了,虽然有很多方式来实现调度,比如Spark、Airflow、Storm等,但是这些调度逻辑内嵌到大的计算框架内部,因此,如果单独去用这些调度功能,还是需要重新开发。Dask提供了多种调度器可供选择,差别是性能不一样。Dask 有两个任务调度家族:单机调度和分布式调度,它们都可以通过全局配置。
单机调度:这类调度器在本机上利用单进程或者线程池,提供基本调度功能。作为调度器的默认选项,简单易用,不支持扩展。
#Local Threads(using ThreadPoolExecutor)
import dask
dask.config.set(scheduler='threads') # overwrite default with threaded scheduler
#Local Processes( using ProcessPoolExecutor)
import dask
dask.config.set(scheduler='processes') # overwrite default with multiprocessing scheduler
#Single Thread
import dask
dask.config.set(scheduler='synchronous')分布式调度:分布式利用多节点,实现更复杂的功能,支持扩展,但分布式模式也可以基于单机实现。分布式集群有很多种,比如:
#Dask Distributed (local)
from dask.distributed import Client, LocalCluster
cluster = LocalCluster() # Launches a scheduler and workers locally
client = Client(cluster) # Connect to distributed cluster and override default
#Dask Distributed (Cluster)
from dask.distributed import Client
from dask_yarn import YarnCluster
cluster = YarnCluster(**cluster_specific_kwargs)
client = Client(cluster)
from dask.distributed import SSHCluster
cluster = SSHCluster(["MachineA", "MachineB", "MachineC"])
client = Client(cluster)
from dask_kubernetes import KubeCluster
cluster = KubeCluster(**cluster_specific_kwargs)
client = Client(cluster)分布式集群除了上述类型外,还有其他很多,比如可以基于科学计算或者工业研究使用的高性能超算,使用Job调度系统如SLURM, SGE, TORQUE, LSF, DRMAA, PBS等来部署集群:
from dask_jobqueue import PBSCluster
cluster = PBSCluster(cores=36,
memory="100GB",
project='P48500028',
queue='premium',
interface='ib0',
walltime='02:00:00')
cluster.scale(100) # Start 100 workers in 100 jobs that match the description above
from dask.distributed import Client
client = Client(cluster) # Connect to that cluster
还可以通过MPI来部署:
mpirun --np 4 dask-mpi --scheduler-file /home/$USER/scheduler.json
from dask.distributed import Client
client = Client(scheduler_file='/path/to/scheduler.json')还可以部署到其他公有云AWS、Azure和 GCP。当然,也可以自己独立部署:
dask-scheduler
dask-worker tcp://host1:8786
dask-worker tcp://host2:8786
。。。所有部署方式都是基于几条简单的命令就可以完成,相当简单,这种方式也提供了一令人激动的集群运行模式:临时集群-一旦计算完成,集群自动停止。
分布式调度采用集中式架构:dask-scheduler作为核心调度器协调分布在多台机器上的多个dask-worker,同时处理来自多个client的并发请求。scheduler基于异步事件机制实现,这意味着能够并发接受客户端请求,多个worker之间通过TCP传输数据,scheduler内部通过依赖图来跟踪任务,每个任务就是一个Python函数,一个任务可能是另一个任务的输出结果,任务依赖图随着用户交互动态变更。从前文的介绍可知,任务提交调度主要有两种途径:调用数据集合的compute方法和client.submit方法。下面通过描述一个Task从被提交到调度到执行结果返回的完整路径,来演示说明调度工作逻辑。示例代码如下:
client = Client('host:port')
x = client.submit(...)
y = client.submit(...)
z = client.submit(add, x, y) # we follow z
print(z.result())假设client已经提交了两个计算任务,分别用变量x和y引用标识。现在client又提交了一个计算x和y的add任务,最后再获取计算结果,用变量z来引用标识。由计算逻辑可知,z依赖x和y。下面分步骤来说明客户端与调度系统的交互过程:
Step 1. 客户端调用submit提交add计算任务,该函数将向scheduler发送如下消息:
'op': 'update-graph',
'tasks': 'z': (add, x, y),
'keys': ['z']该消息是个dict结构,op字段标识操作类型,tasks字段标识任务,keys标识任务的key。submit立即返回(可能在scheduler接收到消息之前)一个future对象,记录当前任务的状态为pending。
Step 2. scheduler接收到消息,并且更新相应状态:
scheduler.update_graph(tasks=msg['tasks'], keys=msg['keys'])此时scheduler注意到x和y本身也是变量,就会去查找x和y,然后更新它们的状态。
Step 3. 选择worker
一旦依赖x和y都已经执行完成,x和y的相应信息就被保留到worker的本地内存中,此时需要选择合适的worker来执行z。如何选择worker,Dask大致按照如下几个标准:
1. 首先,快速选择那些内存中有x或者y的worker;
2. 然后,选择为计算z而传输x和y,消耗更少传输数据的worker。比如,如果有两个不同的worker持有x和y,但是y本身比x占用更多的数据,就选择持有y的的机器,来减少网络传输数据量。
3. 如果有多个worker的数据传输量都比较少,那就选择负载最小的机器。
Step 4. scheder向woker发送调度信息
当被选择的worker因为有计算任务退出,有了空余的计算资源,而且计算任务z也满足了调度条件,调度器就会将其从相应的任务队列中取出,将执行的函数信息(包括函数名称、key和参数)、worker位置打包成消息,通过TCP发送给worker。
'op': 'compute',
'function': execute_task,
'args': ((add, 'x', 'y'),),
'who_has': 'x': (worker_host, port),
'y': (worker_host, port), (worker_host, port),
'key': 'z'Step 5. worker执行任务
worker解压收到的消息,并且注意到计算z依赖x和y,如果本机没有x和y的数据,然后就从who_has指定的机器列表中随机选择一个,当获取到依赖的数据,就通过ThreadPoolExecutor 启动计算(add, 'x', 'y')。同时worker仍然可以计算其他任务,并不阻塞在当前计算任务上。最终,任务计算完成,worker将计算结果存在本地内存:
data['z'] = ...然后向scheduler传回计算成功和结果数据大小的消息,形如下面的消息:
Worker: Hey Scheduler, 'z' worked great.
I'm holding onto it.
It takes up 64 bytes.Step 6. 响应客户端
scheduler接收到worker关于z就绪的消息后,再向所有持有z的future对象的客户端发消息,唤醒阻塞在z.result上的方法调用。同时检查哪些worker持有z的结果,并将其结果转发给client。
Step 7. 垃圾回收
当x和y不再被使用的时候,scheduler向相关worker发消息,通知x和y可以从其本地内存中删除了。同样,假如局部变量z失去作用范围,并且引用计数为0,也将被Python垃圾回收器清理掉,此时scheduler也将收到释放z的消息,在scheduler将z从本地调度状态中删除之后,也周期性地通知相关worker释放相应的key。
上述步骤走完,通常经历几个毫秒的时间。通过上述任务提交、执行和获得响应的过程,我们大致了解了Dask 调度的工作机制,但是里面比较复杂的地方大概在于worker的选取和task的选取,这就是任务的调度策略问题。示例中,介绍了几个选取worker的标准,没有过多介绍task的选取,实际使用中,大量符合调度条件的的并发任务还需要遵从一系列启发式规则,比如先到先服务、后到先服务、处于关键路径且被依赖的任务数量越多的先执行、优先级高的优先等。
五、Dask与Spark的比较
Apache Spark 是一个流行的,用于表格式数据集(tabular datasets)上的分布式计算工具,在今天的大数据分析时代,Spark正成为该领域一个响亮的名字,而Dask作为扩展了现存的Python生态的并行计算库,同样能够在超过内存大小的数据集上提供并行分布式计算能力。那如何比较Spark和Dask,以及如何进行技术选型呢?以一种客观、公正的角度来回答这个问题确实困难,尤其当两者的差异表现在技术实现上。尽管如此,本文仍尝试来这样做,但也欢迎有效的批评指正。
总体来讲,相对Spark,Dask 小巧,轻量。这意味着,Dask有较少的特性,如果提供高级功能,就需要跟其他库协作,尤其涉及到Python生态中的数值计算,比如Pandas、Scikit-Learn等。下文从以下几个方面来详细说明。
1. 语言
Spark用Scala语言编写,同时也支持Python、R、Java。它跟其他JVM代码互操作较好。
Dask用Python语言编写,不支持其他语言。它跟C/C++/Fortran/LLVM或其他通过Python链接的本地编译代码的互操作性结合较好。
2. 生态
Spark是一个all-in-one项目,整合了SQL分析、流式处理、机器学习和图处理等,并且跟其他很多Apache项目的集成度较好。
Dask 是Python生态的一个组成部分,它耦合,同时也加强了其他库的能力,比如NumPy, Pandas, and Scikit-Learn等。
3. 年龄和信誉度
Spark于2010年问世,存在时间较长,在企业大数据领域信誉度较高。
Dask于2014年问世,稍显年轻,它是广受信任的NumPy/Pandas/Scikit-learn/Jupyter等技术栈的扩展。
4. 应用领域
Spark主要集中在像SQL处理的商业智能和轻量的机器学习方面。
Dask主要应用在商业智能和一些科学计算以及自定义应用场景。
5. 内部设计
Spark的内部模型是高层的( higher level),在计算上,从高层提供一致的优化,但是在复杂算法和临时应用系统上缺乏灵活性,从根本上说,Spark是Map-Shuffle-Reduce 范式的扩展。
Dask的内部模型是低层的(lower level),缺乏从高层的优化,但是能够实现复杂算法和定制应用系统,从根本上说,Dask是建立在通用任务调度上的。
总之,如果用户习惯Scala或者SQL 开发、经常进行ETL和商业分析应用、以及倾向于用更可靠、单一技术栈的计算,那Spark是优先选择;如果用户习惯Python开发、在ETL+SQL能力之外,还希望添加额外的并发控制、经常进行的复杂计算明显不适合Spark的内部模型、希望轻量地从本地开发模式转移到集群开发模式、愿意集成三方技术且不介意安装工具包,那Dask是其优先选择。当然两者也可以同时使用,特别是Dask支持的多种集群部署方式,支持用户在现有基于YARN、Kuberbetes的资源管理框架下使用Dask,而且二者都支持 CSV, JSON, ORC和 Parque文件格式的读写。但是如果只是处理在T级别大小的CSV或JSON格式的数据,那Postgres或者MongoDB是其首选。
参考链接
https://docs.dask.org/en/stable/
https://docs.dask.org/en/stable/graphs.html
https://docs.dask.org/en/stable/custom-graphs.html
https://blog.dask.org/2020/07/30/beginners-config
https://blog.dask.org/2020/07/23/current-state-of-distributed-dask-clusters
https://docs.dask.org/en/stable/deploying.html
http://distributed.dask.org/en/stable/journey.html
https://docs.dask.org/en/latest/spark.html?comparison-to-spark
以上是关于Dask核心功能介绍及与Spark的比较的主要内容,如果未能解决你的问题,请参考以下文章