[云原生专题-36]:K8S - 核心概念 - 存储抽象- Pod之间的数据共享与数据持久化 - 网络文件系统网络分布式数据库
Posted 文火冰糖的硅基工坊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[云原生专题-36]:K8S - 核心概念 - 存储抽象- Pod之间的数据共享与数据持久化 - 网络文件系统网络分布式数据库相关的知识,希望对你有一定的参考价值。
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/122820381
目录
第1章 如何给pod传递数据或参数
(1)参数文件:将配置文件直接静态打包到镜像中,因为修改配置不够灵活。
(2)启动命令行:通过定义Pod清单时,指定自定义命令行参数,即设定 args:["命令参数"],这种也可在启动Pod时,传参来修改Pod的应用程序的配置文件.
(3)环境变量:使用环境变量来给Pod中应用传参修改配置
但要使用此种方式,必须符合以下前提之一:
- Pod中的应用程序必须是Cloud Native的应用程序,即支持直接通过环境变量来加载配置信息。
- 通过定义Entrypoint脚本的预处理变量来修改Pod中应用程序的配置文件,这些Entrypoint脚本
- 可以使用set,sed,grep等工具来实现修改,但也要确保容器中有这些工具。
(4)NFS:通过NFS共享NFS目录,并把数据或配置存放在共享目录中
(5)持久化存储卷: 我们可将配置信息直接放到存储卷中,如PV中,Pod启动时,自动挂载存储卷到配置文件目录,
来实现给Pod中应用提供不同的配置。
(6)configMap:把非安全要求的配置问暴露到pod外部
(7)secret:把安全要求的文件问暴露到pod外部
第2章 数据的存储抽象概述
2.1 数据共享与数据持久化基本概念
(1)数据
数据就是数值,也就是我们通过观察、实验或计算得出的结果。
程序 = 数据(结构) + 逻辑(算法)
数据是程序操作的对象
逻辑(算法)是程序操作的过程和步骤。
在单机时代,业务逻辑和算法比数据更加重要,业务逻辑和算法决定了业务应用的运作方式。
在互联网大数据时代,数据比业务逻辑和算法更加重要,数据是一种及其重要的资源与资产。
(2)数据存储地
- 内存:用于临时保存数据,机器或进程或线程重启后,数据就会丢失。
- 数据库:用于永久性保存数据,机器或进程或线程重启后,数据就不会丢失,能够恢复。数据库,可以是简单的单机文件系统中的文件,也可以是网络文件系统中的文件,与可以是数据库系统。
(3)数据共享
数据共享就是让在不同地方使用不同计算机、不同软件的用户能够读取他人数据并进行各种操作、运算和分析。就是不同进程、不同线程、不同机器、不同Pod之间共享相同的数据。
数据共享有多种形式:
- 线程间:不同线程间共享进程的全局变量
- 进程间:不同进程间的共享进程的内存
- 进程间:不同进程共享文件系统的文件
- 进程间:不同进程共享本地数据库
- 主机间:不同主机间共享网络文件NFS => K8S需要的形式
- 主机间:不同机器间共享网络数据库 => K8S需要的形式
(4)数据持久化:
狭义的理解,持久化仅仅是指把内存中的对象数据永久保存到数据库中,这样程序在重启后,数据依然保留。数据持久化的方式有:
- 文件系统
- 网络文件系统
- 网络数据库
2.2 不同Pod之间的数据共享诉求与可能的方案
在K8S中,Pod的内容容器之间,同一个虚拟机的Pod与Pod之间,不同虚拟机的pod与pod之间,都有可能有需要共享的诉求。
(1)线程间和进程间通信的不可行:
在K8S系统中,无论是容器,还是Pod,都是有一个个独立的系统,从逻辑上看,他们之间不可能采用线程间通信和进程间通信。
(2)单机的文件系统通信存在的问题:
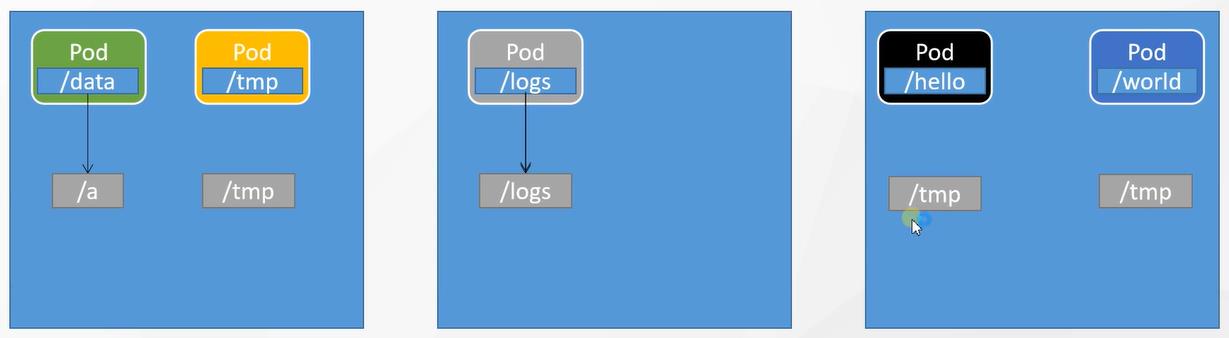
如果使用单机文件系统作为pod的数据持久化会存在两个问题:
- 无法实现不同pod之间的数据共享。
- 某个Node出故障后,K8S会在其他节点进行故障迁移,在其他 节点重建新的Pod,存放在故障节点中的持久化数据无法一起迁移。

(3)K8S可能的通信方式和数据持久化方式
- 主机间的网络通信,业务请求就是通过这种方式完成的。
- 通过网络文件系统NFS进行通信。这种方式主要用于持久化数据共享。
- 通过第三方网络数据库进行通信。这种方式主要用于持久化数据共享。
第3章 网络分布式文件系统
分布式文件系统(Distributed File System)是指文件系统管理的物理存储资源不一定直接连接在本地节点上,而是通过计算机网络与节点项链。
3.1 网络文件系统NFS
NFS:网络文件系统,英文Network File System(NFS),是由SUN公司研制的UNIX表示层协议(presentation layer protocol),能使使用者访问网络上别处的文件就像在使用自己的计算机一样。
NFS是基于UDP/IP协议的应用,其实现主要是采用远程过程调用RPC机制,RPC提供了一组与机器、操作系统以及低层传送协议无关的存取远程文件的操作。
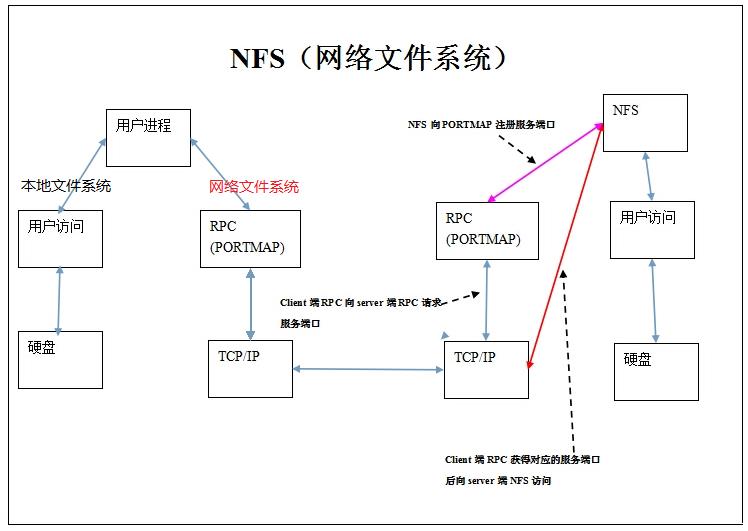
本地的RPC相同于本地的客户端。
3.2 Gluster File System
谷歌的分布式文件系统GFS是一款自由软件,GlusterFS系统是一个可扩展的网络文件系统,相比其他分布式文件系统,GlusterFS具有高扩展性、高可用性、高性能、可横向扩展等特点,并且其没有元数据服务器的设计,让整个服务没有单点故障的隐患。
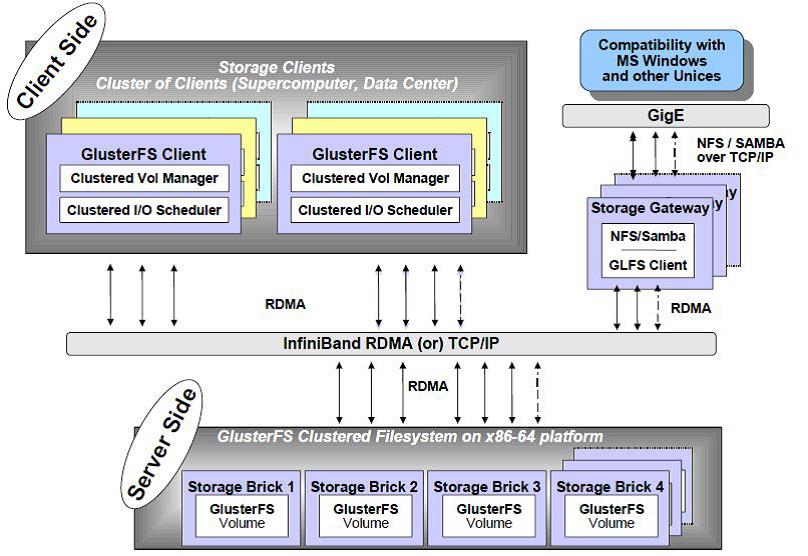
它主要由:客户端、存储服务器(BrickServer)、NFS/Samba 存储网关组成。
GlusterFS 支持TCP/IP 和InfiniBandR DMA 高速网络互联,
客户端可通过原生Glusterfs协议访问数据,其他没有运行GlusterFS客户端的终端可通过NFS/CIFS 标准协议通过存储网关访问数据。
3.3 Ceph
Ceph是一种为优秀的性能、可靠性和可扩展性而设计的统一的、分布式文件系统。它为Linux持续不断进军可扩展计算空间,特别是可扩展存储空间提供了可能。
第4章 网络分布式数据库
4.1 什么是数据库
数据库(Database)是按照数据结构来组织、存储和管理数据的仓库。
每个数据库都有一个或多个不同的 API 用于创建,访问,管理,搜索和复制所保存的数据。
4.2 什么是关系型数据库
我们也可以将数据存储在文件中,但是在文件中读写数据速度相对较慢。
所以,现在我们使用关系型数据库管理系统(RDBMS)来存储和管理大数据量。
所谓的关系型数据库,是建立在关系模型基础上的数据库,借助于集合代数等数学概念和方法来处理数据库中的数据。
RDBMS 即关系数据库管理系统(Relational Database Management System)的特点:
- 1.数据以表格的形式出现
- 2.每行为各种记录名称
- 3.每列为记录名称所对应的数据域
- 4.许多的行和列组成一张表单
- 5.若干的表单组成database

4.3 什么是网络数据库

网络数据库是指把数据库技术引入到计算机网络系统中,借助于网络技术将存储于数据库中的大量信息及时发布出去;而计算机网络借助于成熟的数据库技术对网络中的各种数据进行有效管理,并实现用户与网络中的数据库进行实时动态数据交互。
4.4 什么是分布式数据库
分布式数据库系统通常使用较小的计算机系统,每台计算机可单独放在一个地方,每台计算机中都可能有DBMS的一份完整拷贝副本,或者部分拷贝副本,并具有自己局部的数据库,位于不同地点的许多计算机通过网络互相连接,共同组成一个完整的、全局的逻辑上集中、物理上分布的大型数据库。因此分布式数据库,通常也是网络数据库,称为网络分布式数据库。
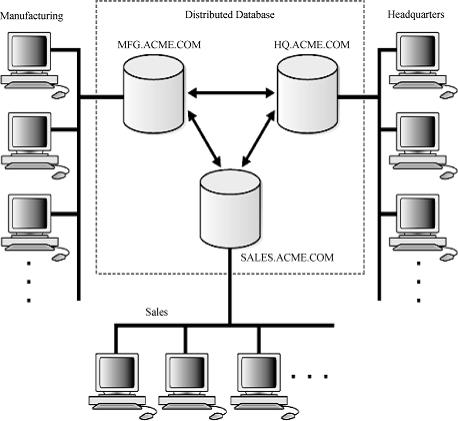
4.5 网络数据库的特点
网络数据库与传统的数据库相比有以下的特点:
(1)扩大了数据资源共享范围。
由于计算机网络的范围可以从局部到全球,因此,网络数据库中的数据资源共享范围也扩大了。
(2)易于进行分布式处理。
在计算机网络中,各用户可根据情况合理地选择网内资源,以便就近快速地处理。对于大型作业及大批量的数据处理,可通过一定的算法将其分解给不同的计算机处理,从而达到均衡使用网络资源,实现分布式处理的目的,大大提高了数据资源的处理速度。
(3)数据资源使用形式灵活。
基于网络的数据库应用系统开发,既可以采用C/S结构(Client/Server,客户机/服务器),也可以采用B/S结构(Browser/Server,浏览器/服务器)方式,开发形式多样,数据使用形式灵活。
(4)便于数据传输交流。
通过计算机网络可以方便地将网络数据库中的数据传送至网络覆盖的任何地区。
(5)降低了系统的使用费用,提高了计算机可用性。
由于网络数据库可供全网用户共享,使用数据资源的用户不一定拥有数据库,这样大大降低丁对计算机系统的要求,同时,也提高了每台计算机的可用性。
(6)数据的保密性、安全性降低。
由于数据库的共享范围扩大,对数据库用户的管理难度加大,网络数据库遭受破坏、窃密的概率加大,降低了数据的保密性和安全性。
从上述的特性来看,网络数据库非常适合作为K8S集群服务的数据持久化工具。
4.6 K8S常用的网络数据库
(1)mysql数据库
mysql 是最流行的关系型数据库管理系统,在 WEB 应用方面 MySQL 是最好的 RDBMS(Relational Database Management System:关系数据库管理系统)应用软件之一。
mysql是关系型数据库,主要用于存放持久化数据,将数据存储在硬盘中,读取速度较慢。
mysql作为持久化存储的关系型数据库,每次请求访问数据库时,都存在着I/O操作,如果反复频繁的访问数据库。会在反复链接数据库上花费大量时间,从而导致运行效率过慢;反复的访问数据库也会导致数据库的负载过高,那么此时缓存的概念就衍生了出来。
mysql用于持久化的存储数据到硬盘,功能强大,速度较慢,基于磁盘,读写速度没有Redis快,但是不受空间容量限制,性价比高。
(2)redis数据库
Redis 全称远程字典服务(REmote DIctionary Server),是完全开源的,遵守 BSD 协议,是一个高性能的 key-value 数据库。可用作数据库、缓存和消息中间件。
Redis数据库就是一款非关系型、缓存性数据库,用于存储使用频繁的数据,这样减少访问数据库的次数,提高运行效率,但是保存时间有限,当数据量超过内存空间时,需扩充内存,但内存价格贵。
Redis 优势:
- 性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。
- 丰富的数据类型 – Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
- 原子 – Redis的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。单个操作是原子性的。多个操作也支持事务,即原子性,通过MULTI和EXEC指令包起来。
- 丰富的特性 – Redis还支持 publish/subscribe, 通知, key 过期等等特性。
(3)mysql + redis联合数据库
mysql和redis因为需求的不同,一般都是配合使用。
需要高实时性要求的地方使用Redis,
不需要高实时性要求的地方使用MySQL。
存储数据在MySQL和Redis之间做同步。
第5章 K8S集群中数据的存储抽象
5.1 K8S的数据存储层
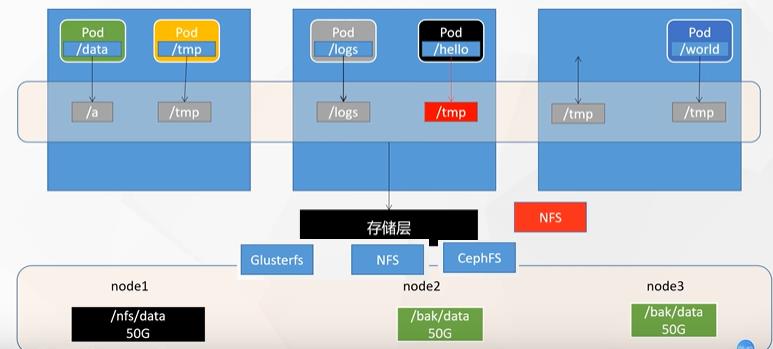
为了能够确保持久化数据不受任意Node节点和任意pod的影响,K8S把存储层从物理节点和物理Pod中剥离出来,形成一个独立的存储层,K8S中的Pod应用程序不直接调用Linux操作系统的接口操作Linux的文件系统,而是嗲用存储层的结果,把需要持久化的数据存放到抽象的存储层中。
至于存储层采用哪种技术来进行持久化数据的存储,K8S并没有规定,可能的技术包括:
(1)网络分布式文件系统: NFS, Gluster File System, Ceph......
(2)网络数据库: mysql, redis.......
k8s支持的存储系统和数据库系统有很多,要求用户全部掌握,显然不现实。
为了能够屏蔽底层存储实现的细节,方便用户使用,k8s引入PV和PVC两种PVC。
5.2 PV与PVC资源的引入
PV(Persistent Volume)是持久化卷的意思,是对底层的共享存储的一种抽象。一般情况下PV由k8s管理员进行创建和配置,它与底层具体的共享存储技术有关,并通过插件完成与共享存储的对接。
PVC(Persistent Volume Claim)是持久卷声明的意思,是用户对于存储需求的一种声明。换句话说,PVC其实就是用户向k8s系统发出的一种资源需求申请。
如下图所示, 用户通过PVC接口实现数据的持久化, 而PV实现了与具体底层文件系统的绑定。
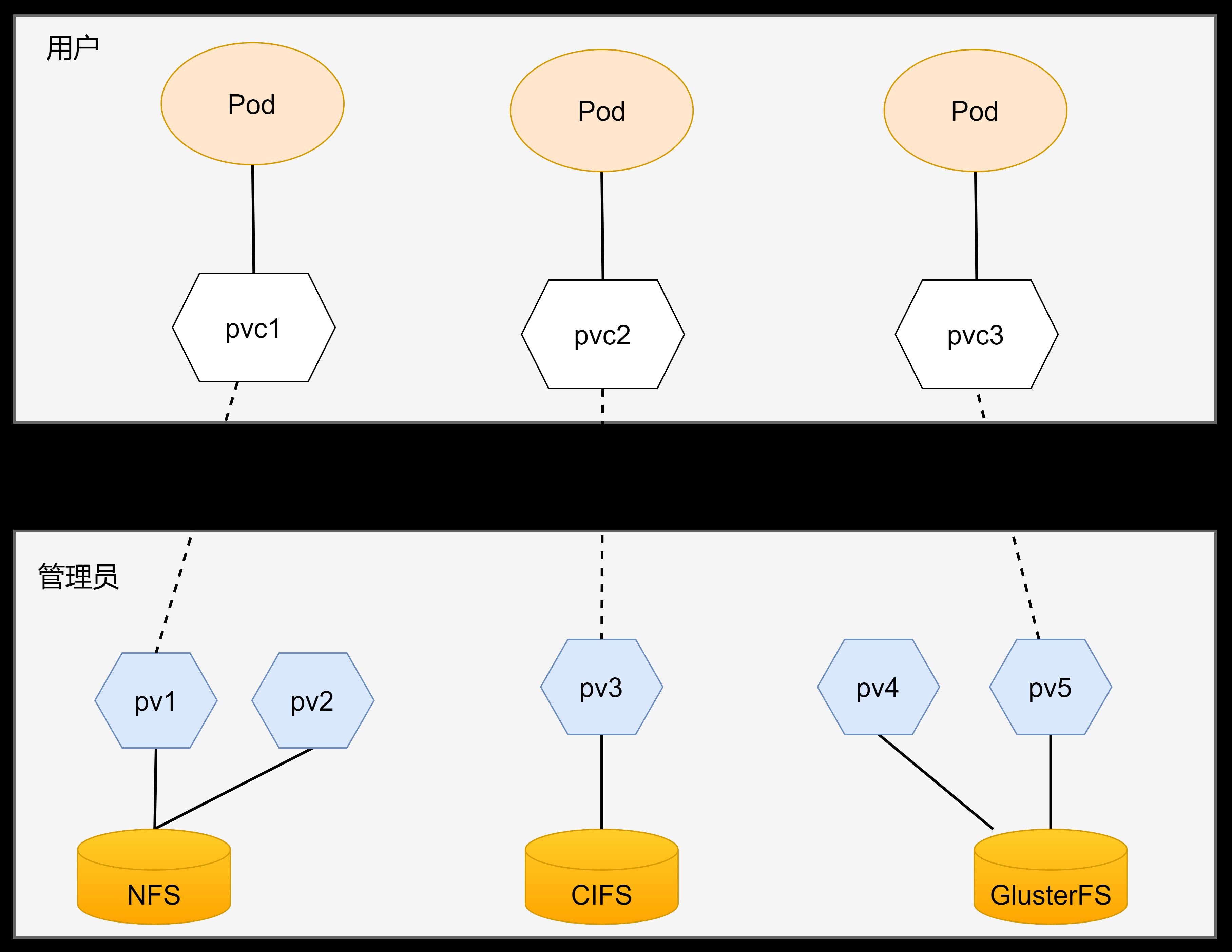
PVC和PV是一一对应的,PV和PVC之间的相互作用遵循以下生命周期,或者说,用户如果需要通过PVC访问底层文件网络文件系统个,需要遵循如下的部署:
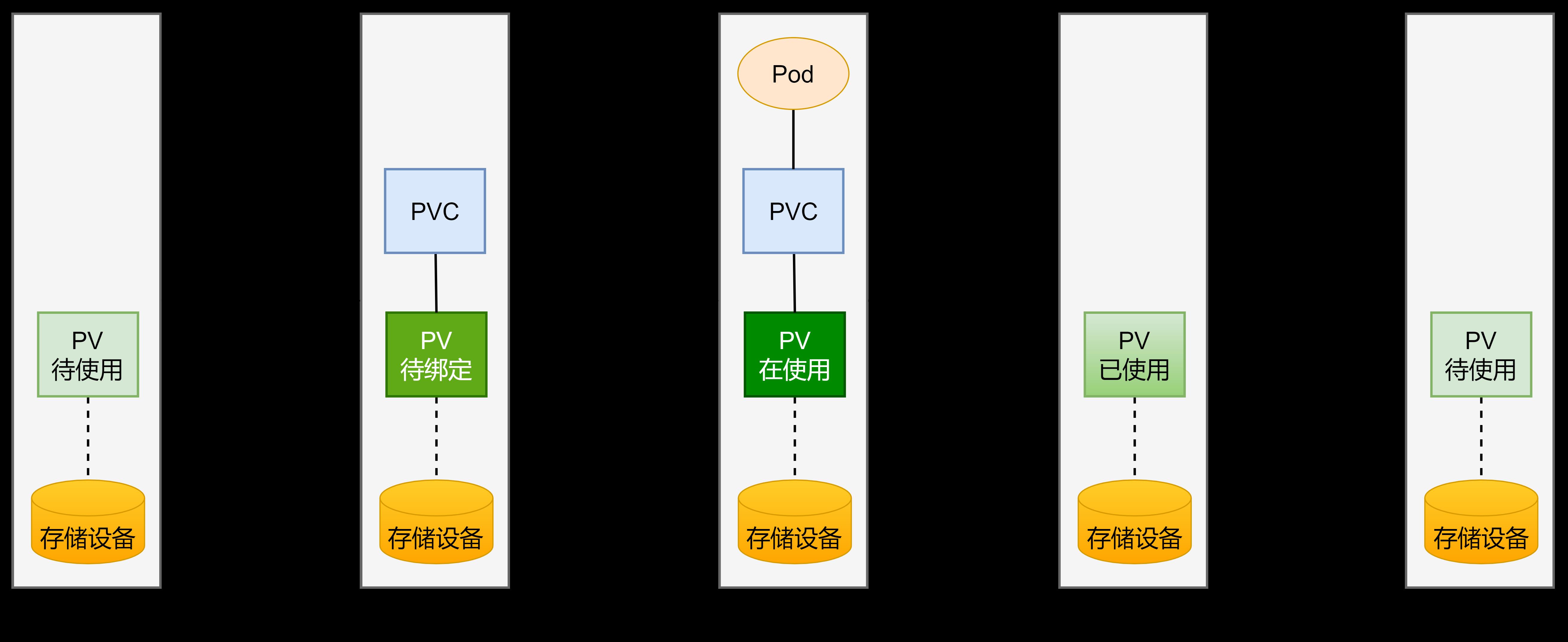
(1)资源供应:管理员手动创建底层存储和PV,这是在创建K8S集群系统是实施的。
(2)资源绑定:用户应用程序创建PVC,k8s负责根据PVC的声明去寻找PV,并绑定。
在用户应用程序定义好PVC之后,K8S系统将根据PVC对存储资源的请求在已存在的PV种选择一个满足条件的。
- 一旦找到,就将该PV与用户定义的PVC进行绑定,用户的应用就可以使用这个PVC了
- 如果找不到,PVC则会无限处于Pending状态,直到等到系统管理员创建了一个符合其要求的PV
- PV一旦绑定到某个PVC上,就会被这个PVC独占,不能再与其他PVC进行绑定了
(3)资源使用:用户服务程序可在pod中像volume一样使用pvc
Pod使用volume的定义,将pvc挂载到容器内的某个路径进行使用
(4)资源释放:用户删除pvc来释放与pv的绑定关系。
当存储资源使用完毕之后,用户可以删除pvc,与该pvc绑定的pv将会被标记为“已释放”,但还不能立刻与其他PVC进行绑定。
通过之前PVC写入的数据可能还被留在存储设备上,只有在清除之后该PV才 能再次使用
(5)资源回收:
k8s根据pv设置的回收策略进行资源的回收。对于pv,管理员可以设定回收策略,用于设置与之绑定的pvc释放资源之后如何处理遗留数据的问题。只有PV的存储空间完成回收,才能供新的PVC绑定和使用。
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/122820381
以上是关于[云原生专题-36]:K8S - 核心概念 - 存储抽象- Pod之间的数据共享与数据持久化 - 网络文件系统网络分布式数据库的主要内容,如果未能解决你的问题,请参考以下文章