走进缓存的世界 - Memcache
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了走进缓存的世界 - Memcache相关的知识,希望对你有一定的参考价值。
系列文章
简介
Memcache是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载。它基于一个存储key/value对的hashmap,通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态、数据库驱动网站的速度。
它的工作机制是在内存中开辟一块空间,然后建立一个HashTable并自己管理,使用非阻塞的网络IO。
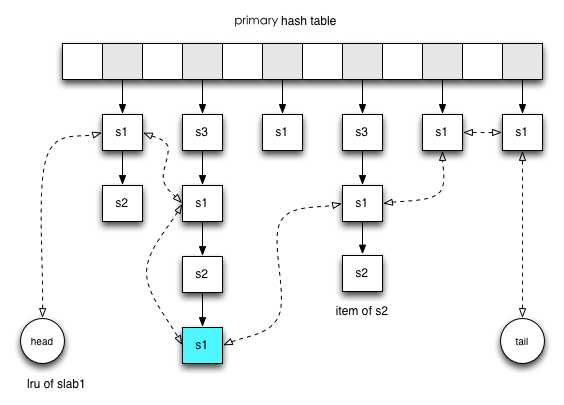
更多详细的信息参阅Memcache官方网站:http://www.danga.com/memcached
MemCache实现原理
MemCache的数据存放在内存中,这就意味着需要考虑以下问题:
- 访问速度比传统的关系型数据库要快,因为传统关系型数据库为了持久化,文件IO操作速度慢
- 数据易丢失,一旦宕机或重启就会丢失所有数据
- 受机器位数的限制,32位机器最多只能使用2GB的内存空间,64位机器可以认为没有上限
对于缓存数据库来说,最重要的莫过于内存分配了,MemCache采用的内存分配方式是固定空间分配。
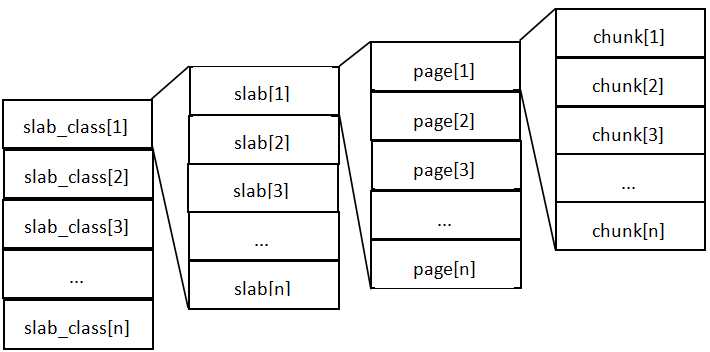
这张图片里面涉及了slab_class、slab、page、chunk四个概念,它们之间的关系是:
- MemCache将内存空间分为一组slab
- 每个slab下又有若干个page,每个page默认是1M,如果一个slab占用100M内存的话,那么这个slab下应该有100个page
- 每个page里面包含一组chunk,chunk是真正存放数据的地方,同一个slab里面的chunk的大小是固定的
- 有相同大小chunk的slab被组织在一起,称为slab_class
MemCache内存分配的方式称为allocator,slab的数量是有限的,几个、十几个或者几十个,这个和启动参数的配置相关。
MemCache中的value存放的地方是由value的大小决定的,value总是会被存放到与chunk大小最接近的一个slab中。比如slab[1]的chunk大小为80字节、slab[2]的chunk大小为100字节、slab[3]的chunk大小为128字节(相邻slab内的chunk基本以1.25为比例进行增长,MemCache启动时可以用-f指定这个比例),那么过来一个88字节的value,这个value将被放到2号slab中。
放入slab时,首先为slab申请内存,申请内存是以page为单位的,所以在放入第一个数据的时候,无论大小为多少,都会有1M大小的page被分配给该slab。申请到page后,slab会将这个page的内存按chunk的大小进行切分,这样就变成了一个chunk数组,最后从这个chunk数组中选择一个用于存储数据。
如果这个slab中没有chunk可以分配了怎么办,如果MemCache启动没有追加-M(禁止LRU,这种情况下内存不够会报Out Of Memory错误),那么MemCache会把这个slab中最近最少使用的chunk中的数据清理掉,然后放上最新的数据。针对MemCache的内存分配及回收算法,总结三点:
- MemCache的内存分配chunk里面会有内存浪费,88字节的value分配在128字节的chunk中损失了30字节,但是这也避免了管理内存碎片的问题
- MemCache的LRU算法不是针对全局的,是针对slab的,即淘汰考核在slab内进行
- MemCache存放的value大小是限制的,因为一个新数据过来,slab会先以page为单位申请一块内存,申请的内存最多就只有1M,所以value大小自然不能大于1M了
Memcache的特性和限制
上文已经提到了一些,此处再做总结:
- Memcache中可以保存的item数量没有限制,只要内存足够
- Memcache单进程在32位机中的最大使用内存为2G,64位机则没有限制
- key最大为250个字节,超过该长度无法存储
- 单个item最大数据是1MB,超过1MB的数据不予存储
- Memcache服务端的数据是不安全的,比如已知某个Memcache记录,可以直接telnet过去,并通过flush_all让已经存在的key/value对立即失效
- 无法遍历Memcache中的所有item,因为这个操作的速度相对缓慢且会阻塞其他操作
- Memcache的高性能源于两个hash结构:第一阶段在客户端,客户端通过hash算法根据key值算出一个服务器节点;第二阶段在服务端,通过一个内部的hash算法,查找真正的item并返回给客户端。
- 从实现的角度看,Memcache是一个非阻塞的、基于事件的服务器程序
Memcached相互不通信的分布式: Memcached 服务器之间不会进行通信,数据都是通过客户端的分布式算法存储到各个服务器。
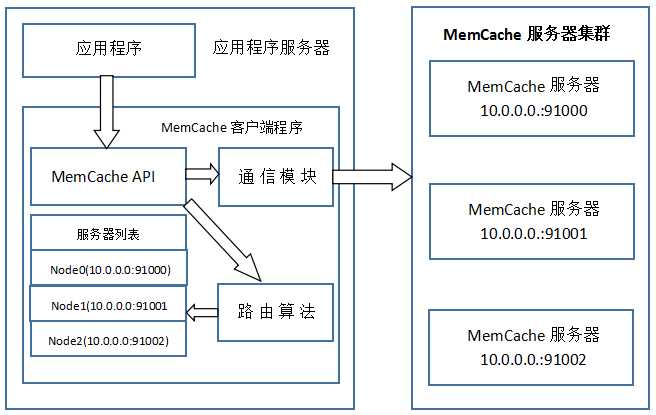
MemCache虽然被称为"分布式缓存",但是MemCache本身完全不具备分布式的功能,MemCache集群之间不会相互通信(与之形成对比的,比如JBoss Cache,某台服务器有缓存数据更新时,会通知集群中其他机器更新缓存或清除缓存数据),所谓的"分布式",完全依赖于客户端程序的实现,就像上面这张图的流程一样。
MemCache一次写缓存的流程:
- 应用程序输入需要写缓存的数据
- API将Key输入路由算法模块,路由算法根据Key和MemCache集群服务器列表得到一台服务器编号
- 由服务器编号得到MemCache及其的ip地址和端口号
- API调用通信模块和指定编号的服务器通信,将数据写入该服务器,完成一次分布式缓存的写操作
读缓存和写缓存一样,只要使用相同的路由算法和服务器列表,且应用程序查询的是相同的Key,MemCache客户端总是访问相同的客户端去读取数据,只要服务器中还缓存着该数据,就能保证缓存命中。
这种MemCache集群的方式也是从分区容错性的方面考虑的,假如Node2宕机了,那么Node2上面存储的数据都不可用了,此时由于集群中Node0和Node1还存在,下一次请求Node2中存储的Key值的时候,肯定是没有命中的,这时先从数据库中拿到要缓存的数据,然后路由算法模块根据Key值在Node0和Node1中选取一个节点,把对应的数据放进去,这样下一次就又可以走缓存了,这种集群的做法很好,但是缺点是成本比较大。
还需要注意的是,Memcache设置添加某个key值的时候,指定expiry为0表示这个key/value永久有效,但这个key/value也会在30天后失效,见memcache.c源代码:


#define REALTIME_MAXDELTA 60*60*24*30 static rel_time_t realtime(const time_t exptime) { if (exptime == 0) return 0; if (exptime > REALTIME_MAXDELTA) { if (exptime <= process_started) return (rel_time_t)1; return (rel_time_t)(exptime - process_started); } else { return (rel_time_t)(exptime + current_time); } }
这个失效的时间是memcache源码里面写死的,开发者没有办法改变。
TTL过期策略
数据过期方式:Lazy Expiration + LRU。这一点和Redis相似,也确实应该这么做,而不是维护红黑树。
1. Lazy Expiration
memcached内部不会监视记录是否过期,而是在get时查看记录的时间戳,检查记录是否过期。这种技术被称为lazy(惰性)expiration。因此,memcached不会在过期监视上耗费CPU时间。
2. LRU
memcached会优先使用已超时的记录的空间,但即使如此,也会发生追加新记录时空间不足的情况,此时就要使用名为 Least Recently Used(LRU)机制来分配空间。当memcached的内存空间不足时(无法从slab class 获取到新的空间时),就从最近未被使用的记录中搜索,并将其空间分配给新的记录。
Memcache的安全
上面的Memcache服务器端都是直接通过客户端连接后操作,没有任何的验证过程,如果服务器是直接暴露在互联网上的话比较危险,轻则数据泄露被其他无关人员查看,重则服务器被入侵,因为Mecache是以root权限运行的,况且里面可能存在一些我们未知的bug或者是缓冲区溢出的情况,这些都是我们未知的,所以危险性是可以预见的。为了安全起见,我做两点建议,能够稍微的防止黑客的入侵或者数据的泄露。
内网访问
最好把两台服务器之间的访问是内网形态的,一般是Web服务器跟Memcache服务器之间。普遍的服务器都是有两块网卡,一块指向互联网,一块指向内网,那么就让Web服务器通过内网的网卡来访问Memcache服务器,我们Memcache的服务器上启动的时候就监听内网的IP地址和端口,内网间的访问能够有效阻止其他非法的访问。
# memcached -d -m 1024 -u root -l 192.168.0.200 -p 11211 -c 1024 -P /tmp/memcached.pid
Memcache服务器端设置监听通过内网的192.168.0.200的ip的11211端口,占用1024MB内存,并且允许最大1024个并发连接
设置防火墙
防火墙是简单有效的方式,如果却是两台服务器都是挂在网的,并且需要通过外网IP来访问Memcache的话,那么可以考虑使用防火墙或者代理程序来过滤非法访问。
一般我们在Linux下可以使用iptables或者FreeBSD下的ipfw来指定一些规则防止一些非法的访问,比如我们可以设置只允许我们的Web服务器来访问我们Memcache服务器,同时阻止其他的访问。
# iptables -F # iptables -P INPUT DROP # iptables -A INPUT -p tcp -s 192.168.0.2 --dport 11211 -j ACCEPT # iptables -A INPUT -p udp -s 192.168.0.2 --dport 11211 -j ACCEPT
上面的iptables规则就是只允许192.168.0.2这台Web服务器对Memcache服务器的访问,能够有效的阻止一些非法访问,相应的也可以增加一些其他的规则来加强安全性,这个可以根据自己的需要来做。
以上是关于走进缓存的世界 - Memcache的主要内容,如果未能解决你的问题,请参考以下文章