恒源云_社区产出大拿的论文小记(Flooding-X)
Posted AI酱油君
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了恒源云_社区产出大拿的论文小记(Flooding-X)相关的知识,希望对你有一定的参考价值。
文章来源 | 恒源云社区
原文地址 | Flooding-X: 超参数无关的 Flooding 方法
原文作者 | Mathor
所谓大佬,就是只要你肯挖,总有你不知道的知识点在某个地方等着你来学习!
往下看,这不就来了吗!
正文开始:
ICML2020的论文《Do We Need Zero Training Loss After Achieving Zero Training Error?》提出了一种Flooding方法,用于缓解模型过拟合,详情可以看我的文章《我们真的需要把训练集的损失降到零吗?》。这里简单过一下,论文提出了一个超参数
b
b
b,并将损失函数改写为

其中, b b b是预先设定的阈值,当 L ( θ ) \\mathcalL(\\boldsymbol\\theta) L(θ) > b b b时 L ~ ( θ ) = L ( θ ) \\tilde\\mathcalL(\\boldsymbol\\theta)=\\mathcalL(\\boldsymbol\\theta) L~(θ)=L(θ),这时就是执行普通的梯度下降;而 L ( θ ) \\mathcalL(\\boldsymbol\\theta) L(θ)< b b b时 L ~ ( θ ) \\tilde\\mathcalL(\\boldsymbol\\theta) L~(θ)=2 b b b- L ( θ ) \\mathcalL(\\boldsymbol\\theta) L(θ),注意到损失函数变号了,所以这时候是梯度上升。因此,总的来说就是以 b b b为阈值,低于阈值时反而希望损失函数变大。论文把这个改动称为Flooding
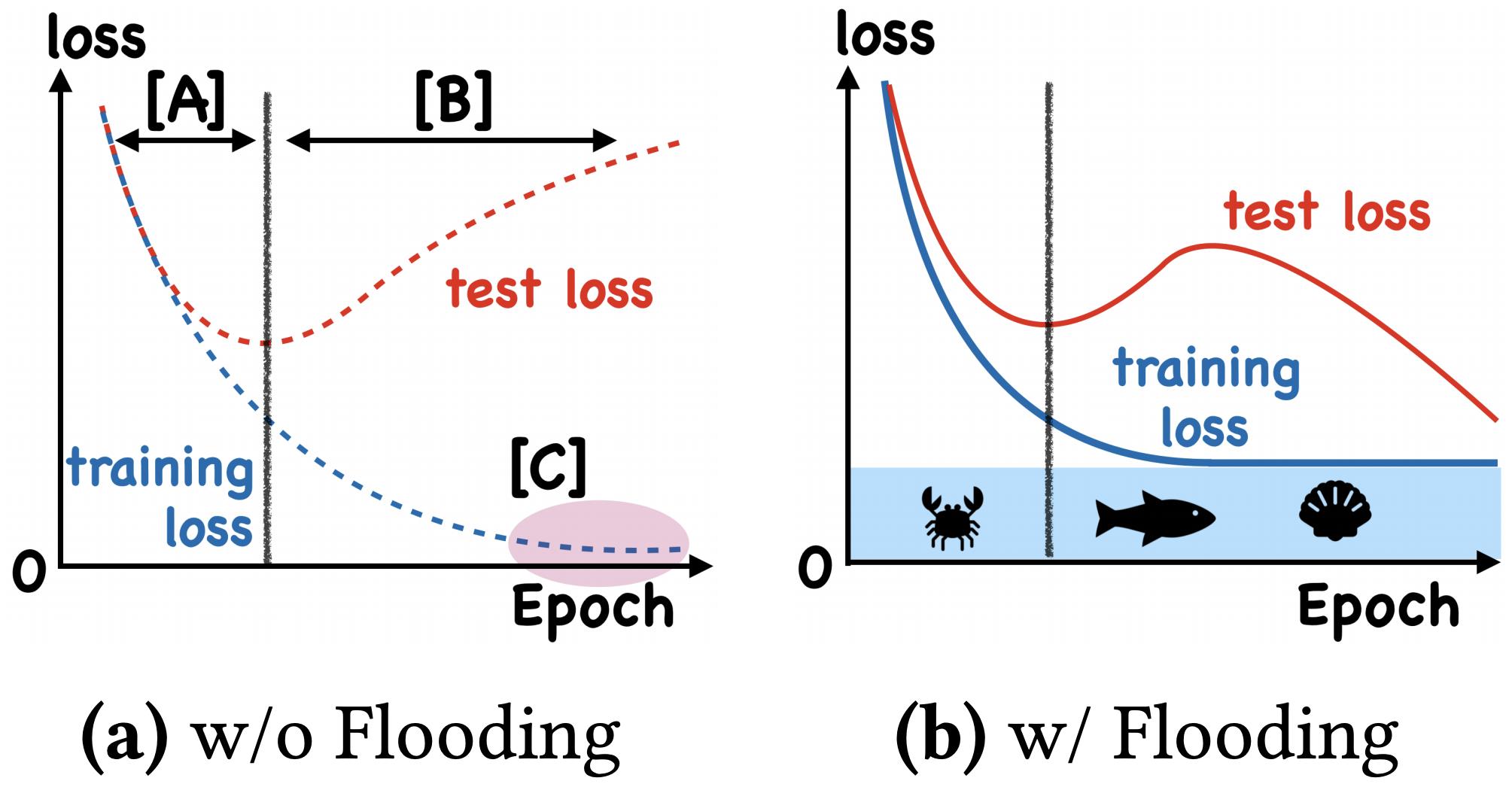
这样做有什么效果呢?论文显示,在某些任务中,训练集的损失函数经过这样处理后,验证集的损失能出现 “二次下降(Double Descent)”,如下图
我们可以假设梯度先下降一步后上升一步,学习率为
ε
\\varepsilon
ε,通过泰勒展开可以得到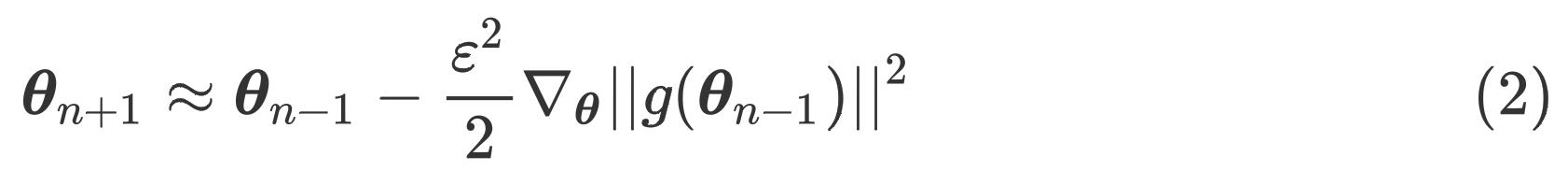
其中, θ n \\boldsymbol\\theta_n θn表示第 n n n次迭代的参数, g ( θ n − 1 ) = ∇ θ L ( θ n − 1 ) g(\\boldsymbol\\theta_n-1)=\\nabla_\\boldsymbol\\theta\\mathcalL(\\boldsymbol\\theta_n-1) g(θn−1)=∇θL(θn−1)表示损失对参数 θ n − 1 \\boldsymbol\\theta_n-1 θn−1的梯度。式(2)的结果相当于以 ε 2 2 \\frac\\varepsilon^22 2ε2为学习率、损失函数为梯度惩罚 ∣ g ( θ ) ∣ ∣ 2 = ∣ ∣ ∇ θ L ( θ ) ∣ ∣ 2 ∣ |g(\\boldsymbol\\theta)||^2=||\\nabla_\\boldsymbol\\theta\\mathcalL(\\boldsymbol\\theta)||^2∣ ∣g(θ)∣∣2=∣∣∇θL(θ)∣∣2∣ 的梯度下降
详细的推导过程见《我们真的需要把训练集的损失降到零吗?》
ACHILLES’ HEEL OF FLOODING
Flooding的阿喀琉斯之踵在于超参数 b b b,我们需要花非常多的时间寻找最佳的阈值 b b b,这并不是一件容易的事
Achilles’ Heel(阿喀琉斯之踵)阿喀琉斯是古希腊神话故事中的英雄人物,刀枪不入,唯一的弱点是脚后跟(踵)。后用于来比喻某东西的致命缺陷
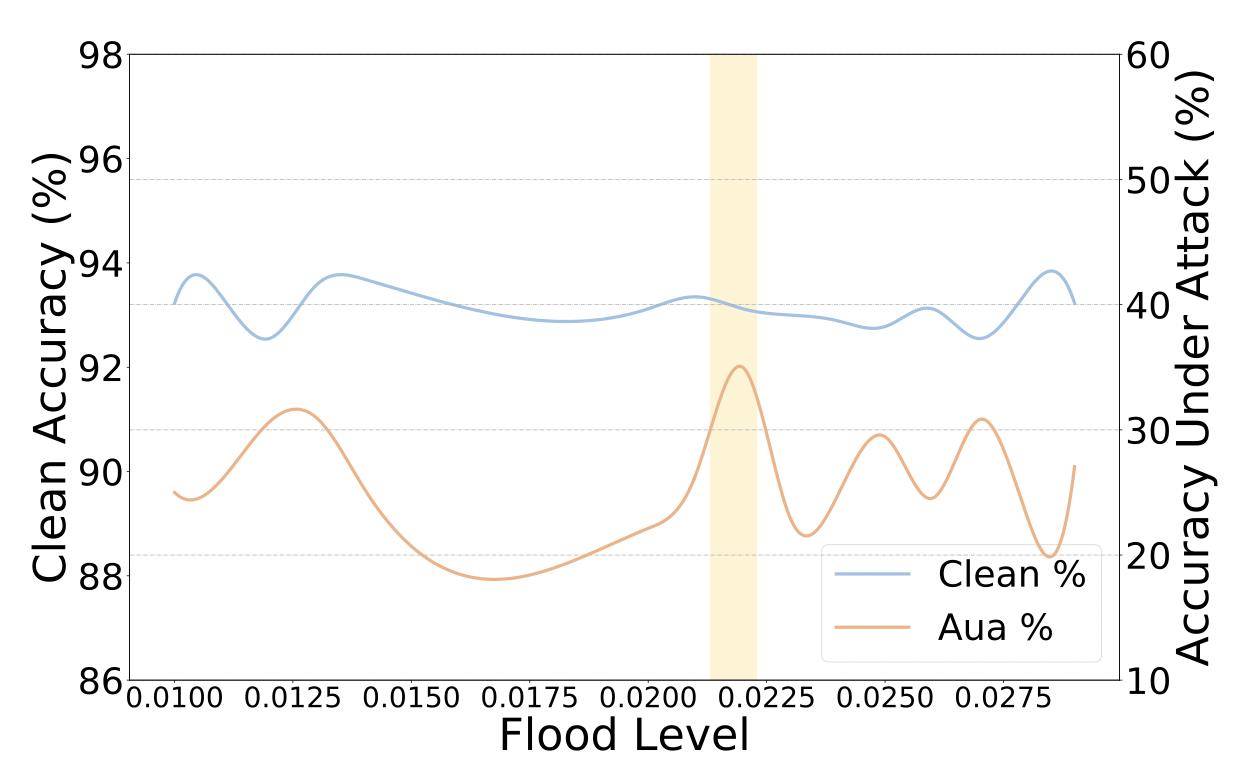
下图展示了使用BERT在SST-2数据集上不同的阈值
b
b
b对结果的影响(黄色区域是最佳结果)。可以看出,
b
b
b的设置对结果的影响非常大
GRADIENT ACCORDANCE
ACL2022的投稿有一篇名为《Flooding-X: Improving BERT’s Resistance to Adversarial Attacks via Loss-Restricted Fine-Tuning》的文章,以"梯度一致性"作为开启Flooding的"阀门",而不再采用超参数
b
b
b。具体来说,我们首先定义包含参数
θ
\\boldsymbol\\theta
θ的模型
f
f
f,考虑一个样本
x
x
x以及真实标签
y
y
y,它们的损失为
L
(
f
(
θ
,
x
)
,
y
)
\\mathcalL(f(\\boldsymbol\\theta, x), y)
L(f(θ,x),y),损失关于参数的梯度为

其中,式(3)的负值就是参数
θ
\\boldsymbol\\theta
θ更新的方向。现在我们考虑两个样本
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
(x_1,y_1), (x_2,y_2)
(x1,y1),(x2,y2)的情况,根据上述定义,样本1的梯度为

对于样本1来说,参数更新所导致的损失变化为
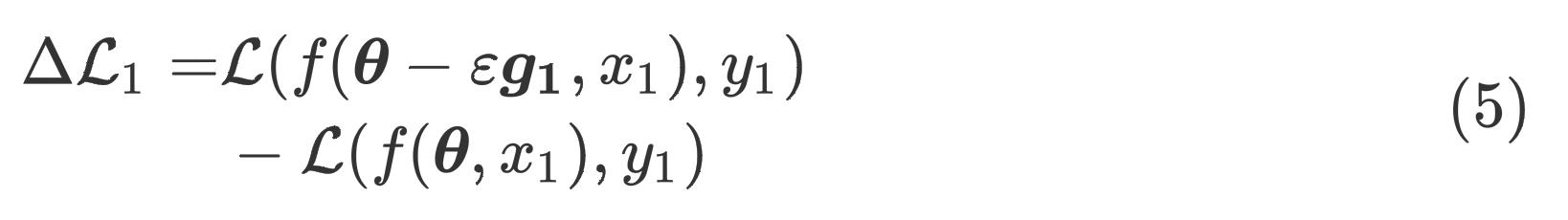
将
f
(
θ
,
x
1
)
f(\\boldsymbol\\theta, x_1)
f(θ,x1)通过泰勒展开变形得
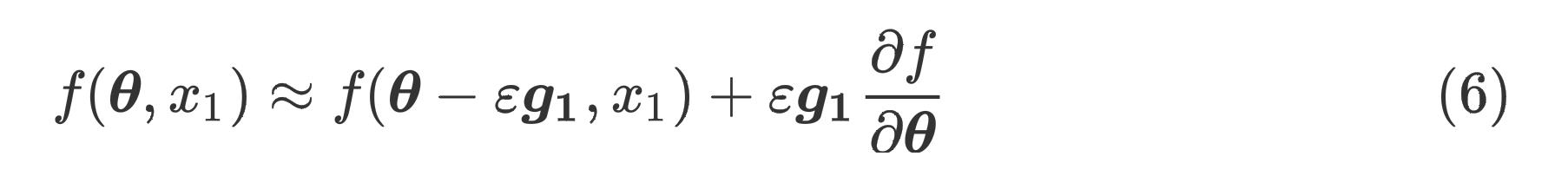
f ( θ − ε g 1 , x 1 ) − f ( θ , x 1 ) ε g 1 = ∂ f ∂ θ \\fracf(θ−εg 1 ,x 1 )−f(θ,x 1 )εg 1 = \\frac∂f∂θ εg1f(θ−εg1,x1)−f(θ,x1)=∂θ∂f
我们将
ε
g
1
∂
f
∂
θ
\\varepsilon \\boldsymbolg_1\\frac\\partial f\\partial \\boldsymbol\\theta
εg1∂θ∂f记作
T
(
x
1
)
T(x_1)
T(x1),并对
L
(
f
(
θ
,
x
1
)
,
y
1
)
\\mathcalL(f(\\boldsymbol\\theta, x_1), y_1)
L(f(θ,x1),y1)做类似的泰勒展开得

根据式(6)可以推出第一个等号,约等于是从泰勒展开推导的,具体来说
L ( A + T ( x 1 ) , y 1 ) − L ( A , y 1 ) T ( x 1 ) = L ′ \\fracL(A+T(x 1 ),y 1 )−L(A,y 1 )T(x 1 ) =L ′ T(x1)L(A+T(x1),y1)−L(A,y1)=L′
将式(7)带入式(5)得
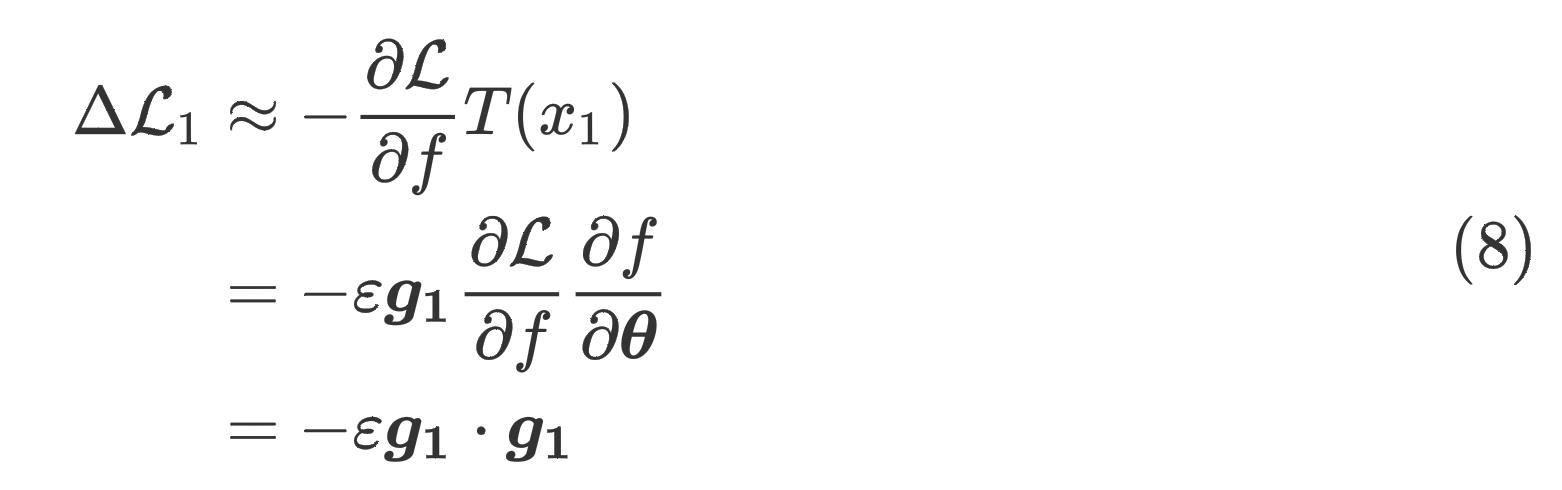
类似的,参数根据样本 ( x 1 , y 1 ) (x_1,y_1) (x1,y1)更新后,在样本 ( x 2 , y 2 ) (x_2, y_2) (x2,y2)上的损失差为 Δ L 2 = − ε g 1 ⋅ g 2 \\Delta\\mathcalL_2 = -\\varepsilon \\boldsymbolg_1\\cdot \\boldsymbolg_2 ΔL2=−εg1⋅g2
值得注意的是,根据定义, Δ L 1 \\Delta \\mathcalL_1 ΔL1是负的,因为模型是对于 ( x 1 , y 1 ) (x_1,y_1) (x1,y1)更新的,自然就会导致其损失的降低。如果 Δ L 2 \\Delta \\mathcalL_2 ΔL2也是负的,那么在 ( x 1 , y 1 ) (x_1, y_1) (x1,y1)上更新的模型被认为对 ( x 2 , y 2 ) (x_2, y_2) (x2,y2)有积极的影响。上面的等式表明,这种共同关系相当于两个样本的梯度 g 1 , g 2 \\boldsymbolg_1,\\boldsymbolg_2 g以上是关于恒源云_社区产出大拿的论文小记(Flooding-X)的主要内容,如果未能解决你的问题,请参考以下文章