Meta AI发布图音文大一统模型Data2vec,4天在GitHub揽1.5万星
Posted QbitAl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Meta AI发布图音文大一统模型Data2vec,4天在GitHub揽1.5万星相关的知识,希望对你有一定的参考价值。
行早 发自 凹非寺
量子位 | 公众号 QbitAI
Meta AI搞了一个大一统的自监督学习模型Data2vec。
怎么个大一统法?
图像、语音、文本都可以处理,效果还都不错,在CV方面甚至超过了包括MAE、MaskFeat在内的一众模型。
这是怎么做到的?我们来看看Data2vec的思路和结构。
Data2vec如何统一图音文
关于这个问题,我们可以从模型名字中看出一些端倪。
和Word2vec把词转化为可计算的向量类似,Data2vec会把不同类型的数据都转化为同一种形式的数据序列。
这样就成功避开了模态不同这个问题。
然后,再用自监督学习的方法遮住这些数据的一部分,通过训练让模型把遮住的部分还原。
而它的结构也是在这个思路上设计的。
Data2vec以Transformer架构为基础,设计了一个教师-学生网络结构:
从上图中可以看出,无论对于任何形式的输入,都先转化为数据序列,并mask一部分信息(或挡住狗头,或覆盖一段语音,或遮住一个单词)。
然后让学生网络通过部分可见的输入去预测完整输入,再由教师网络去调整,达到一个模型处理多任务的效果。
那接下来的问题就是如何把不同类型的输入都转化为同一种形式了。
Data2vec如何标准化输入数据
在标准化输入这一块,Data2vec还是具体问题具体分析的。
毕竟像素、波形和文本是完全不同的形式,而Data2vec对不同形式的输入采用了不同的编码策略,但是目的都是一样的。
那就是将这些输入都转化为数据序列。
具体的操作方法是这样的:
| 任务 | 编码方式 | 掩码方式 |
| 计算机视觉 | ViT图像分块 | Block-wise Masking Strategy |
| 语音 | 多层一维卷积神经网络 | Mask spans of latent speech representation |
| 文本 | 预处理获得子词单元,然后通过嵌入向量将其嵌入分布空间 | Tokens |
其中ViT的编码策略就是把一张图分成一系列的图块,每个图块有16x16个像素,然后输入到一个线性变换系统中。
而语音的编码方式是用多层的一维卷积神经网络将16kHz的波形转换为50Hz的一串数据序列。
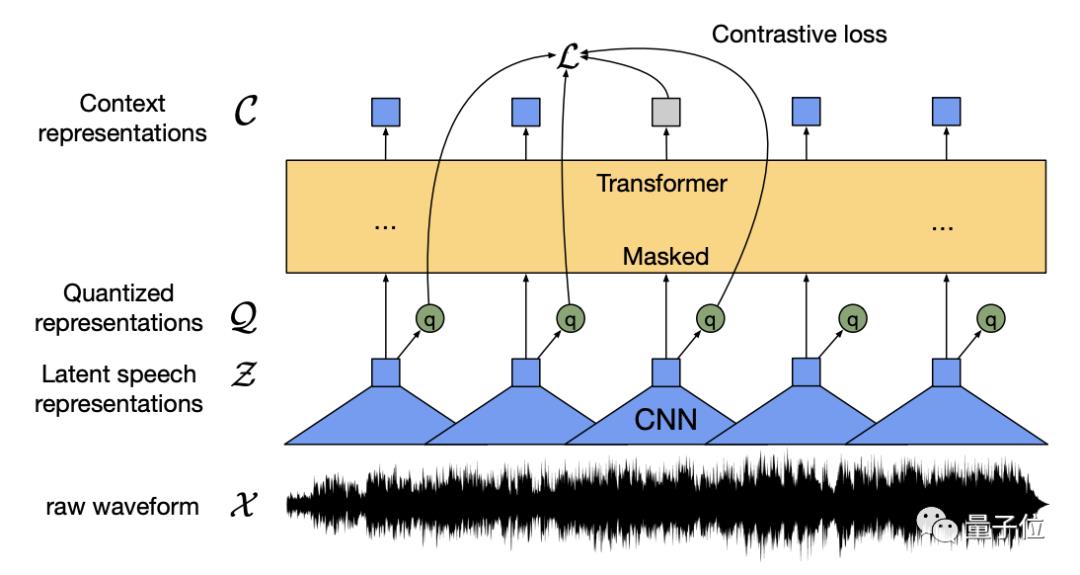
再加上文本编码的嵌入向量,这样所有模态的输入都转换为了数据序列,方便后续的训练。
而对于掩码策略来说,不同的模态的表现形式也是不一样的。
例如图像可以遮住一块,但是语音和文本有上下文的关联,不能随便遮住一部分。
因此对不同的模态,Data2vec也采取了相应的符合不同数据特征的掩码方式。
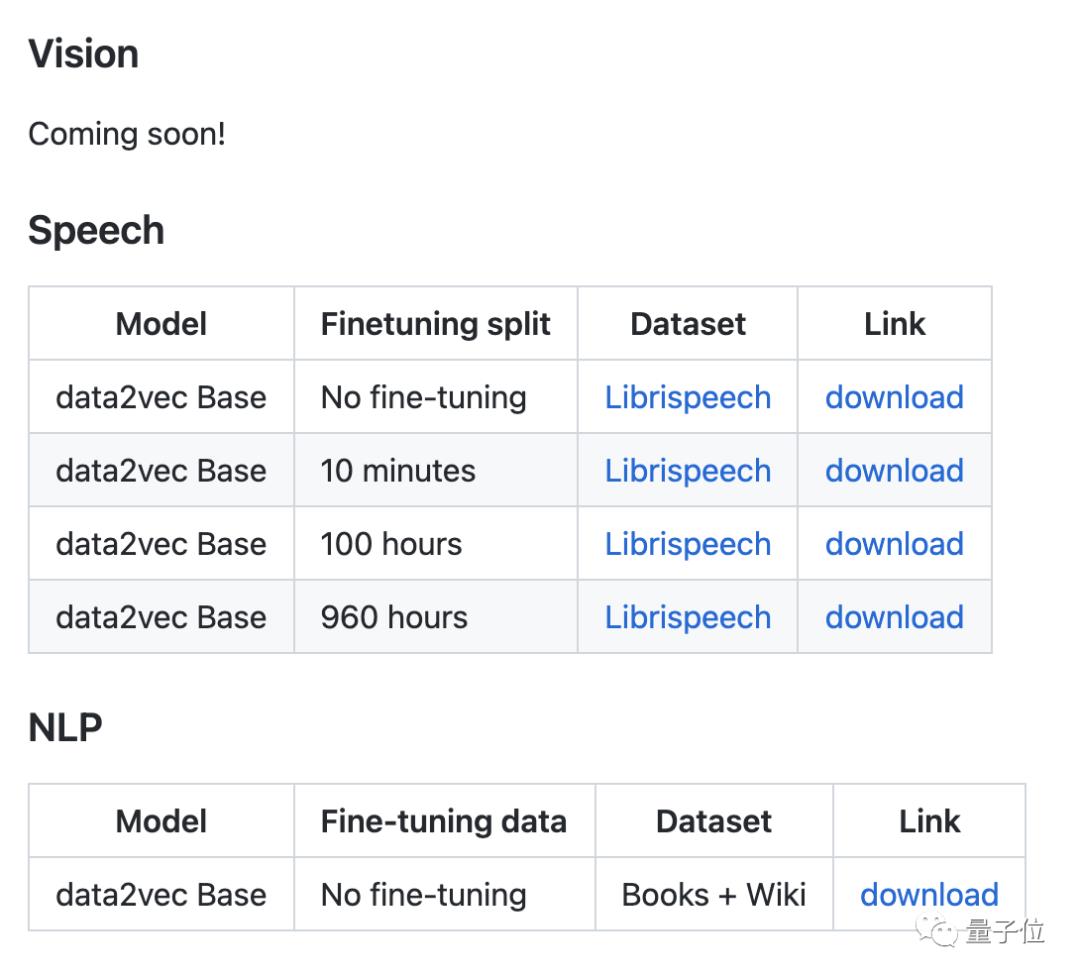
这样标准化之后,Data2vec还针对不同的下游任务做了一些微调,其中语音和文本的模型已经在GitHub上放出,视觉模型也正在路上:
我们来看看这统一的模型性能怎么样。
性能表现
虽然Data2vec三手齐抓,但是性能也没落下。
在计算机视觉方面,在IN1K上预训练情况如下表所示:
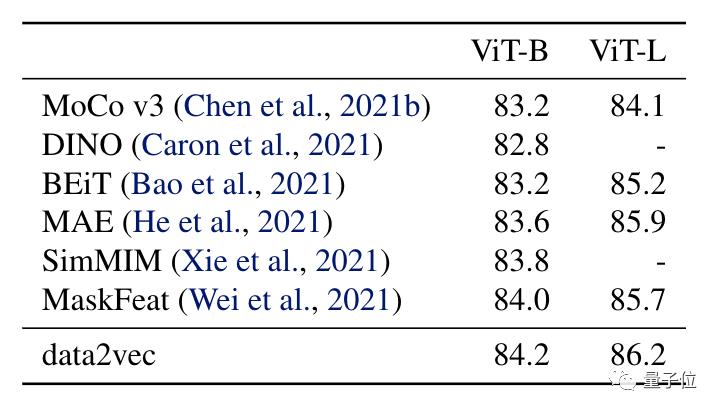
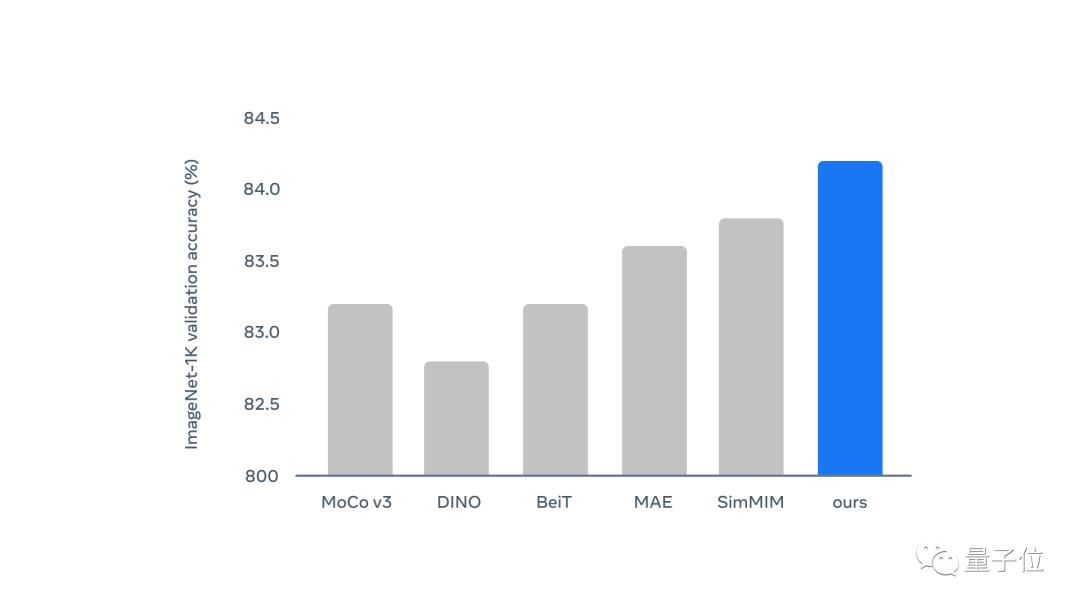
和一些其他模型相比,Data2vec精度表现最好。而且Data2vec只训练了800个epochs,而表中的MAE,MaskFeat训练了1600个epochs。
看柱状图则更为明显,蓝色为Data2vec:
在语音处理方面,在LS-960上预训练结果如下:
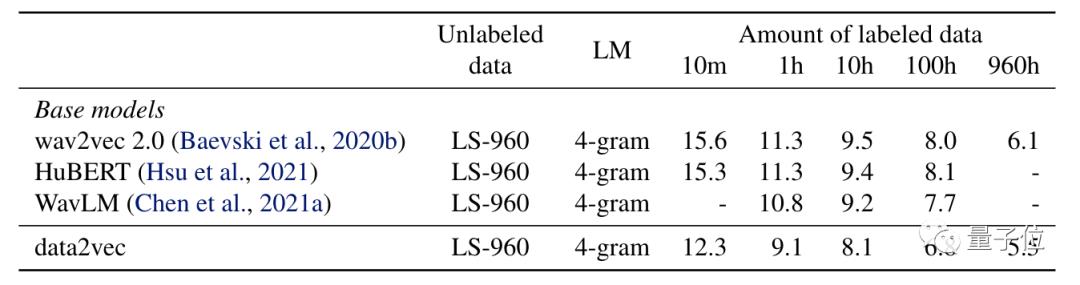
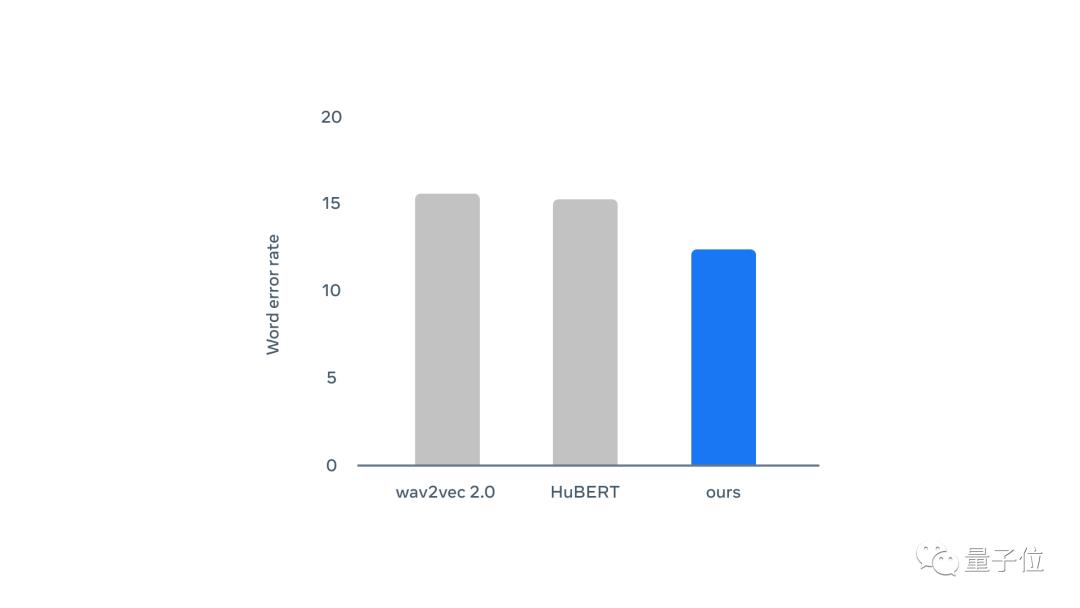
可以看出,Data2vec在不同的标签数据量下单词错误率都比wav2vec2.0和HuBERT要低。
而在文本处理上,Data2vec采用了和BERT相同的训练设置,训练集为Books Corpus和英文维基百科数据。
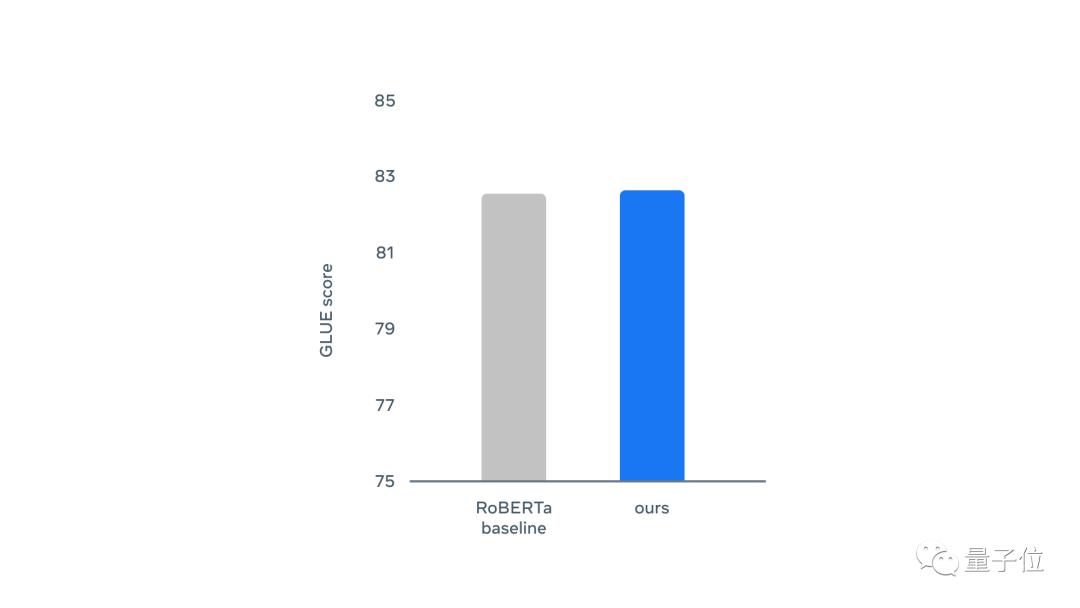
在GLUE评估中,Data2vec在自然语言推理(MNLI、QNLI、RTE),句子相似性(MRPC、QQP、STS-B),语法(CoLA)和情绪分析(SST)等指标中和RoBERTa不相上下。
其中Baseline这一条是RoBERTa在和BERT类似的设置中的训练结果:
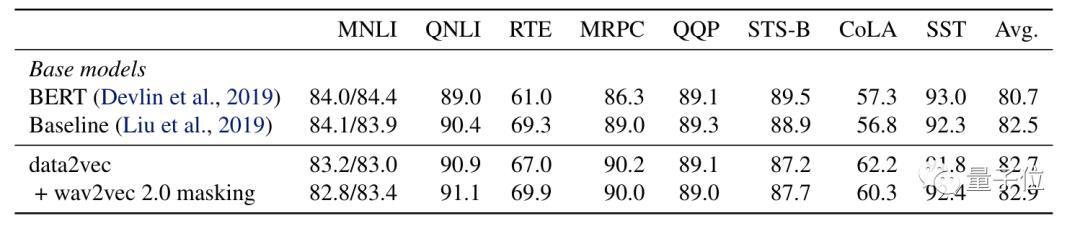
总体评分也差不多:
这么看来,统一的模型架构真的可以有效地用于多种任务模式。
虽然Data2vec在输入数据和掩码方式上还是按照不同的方法来处理,但是它仍然是探索模型统一的尝试。
或许将来会有统一的掩码策略和不同模态数据的混合数据集,做到真正的大一统。
参考链接:
[1]https://ai.facebook.com/research/data2vec-a-general-framework-for-self-supervised-learning-in-speech-vision-and-language
[2]https://ai.facebook.com/blog/the-first-high-performance-self-supervised-algorithm-that-works-for-speech-vision-and-text
[3]https://github.com/pytorch/fairseq/tree/main/examples/data2vec
以上是关于Meta AI发布图音文大一统模型Data2vec,4天在GitHub揽1.5万星的主要内容,如果未能解决你的问题,请参考以下文章
Meta AI 更新的 Data2vec 2.0 | 实现更快更高效的视觉语音和文本的自监督学习
Meta AI 更新的 Data2vec 2.0 | 实现更快更高效的视觉语音和文本的自监督学习
Meta 发布 Bean Machine 帮助衡量 AI 模型的不确定性