Hadoop学习笔记
Posted chenyyhh92
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop学习笔记相关的知识,希望对你有一定的参考价值。
Hadoop部署方式
- 本地模式
- 伪分布模式(在一台机器中模拟,让所有进程在一台机器上运行)
- 集群模式
服务器只是一堆废铁而已,上面跑了tomcat,我们叫它web服务器;上面跑了mysql,我们叫它数据库服务器。所以不同服务器只是上面跑的进程(或者说程序)不同,我们是根据它们跑的进程来命名它们分别叫什么服务器的。
宿主机(windows)和客户机(linux)之间通信
- host-only:宿主机与客户机单独组网
- 好处:网络隔离
- 坏处:虚拟机和其他服务器之间不能通信
- bridge:客户机与宿主机在同一个局域网
- 好处:都在同一个局域网,可以互相访问
- 坏处:不安全
Linux网络设置
修改主机名:/etc/sysconfig/network
将主机名和IP绑定:/etc/hosts
修改ip地址:/etc/sysconfig/network-scripts/ifcfg-eth0
关闭防火墙:service iptables stop chkconfig iptables off
防火墙是禁止一些端口启动的,而hadoop运行需要占用很多端口,因此要关闭防火墙
Hadoop伪分布式/完全分布式安装步骤
此安装步骤适用于Hadoop 0.x 和 Hadoop 1.x 版本。
Hadoop 2.x 很复杂,建议参考官网的教程,下面的不适用于版本2.x。
两种分布式模式
分布式模式分两种,伪分布式和完全分布式。
- 伪分布式是把进程运行在同一台机器上,但不是一个JVM
- 而完全分布式就是把整个服务分布在各个节点上
伪分布式
- 设置静态ip
- 修改主机名
- 修改当前会话的主机名:
hostname XXX - 修改配置文件中的主机名:
vi /etc/hosts
- 修改当前会话的主机名:
- 把hostname和ip绑定
vi /etc/hosts- 增加一行:
192.168.xx.yyy yourhostname
关闭防火墙
不论是伪分布安装,还是真实的分布式安装,如果不关闭防火墙,会遇到例如如下这种情况:执行
./start-dfs.sh后,提示说都启动了,也将启动写进日志了,可是去其他机器上执行jps发现并没有启动对应的Java进程。原因就是防火墙没有关闭。- service iptables stop
验证:
service iptables status- service iptables stop
- 防止防火墙再次启动:
chkconfig iptables off
验证:chkconfig --list | grep iptables SSH(secure shell)的免密码登陆
原理如图:
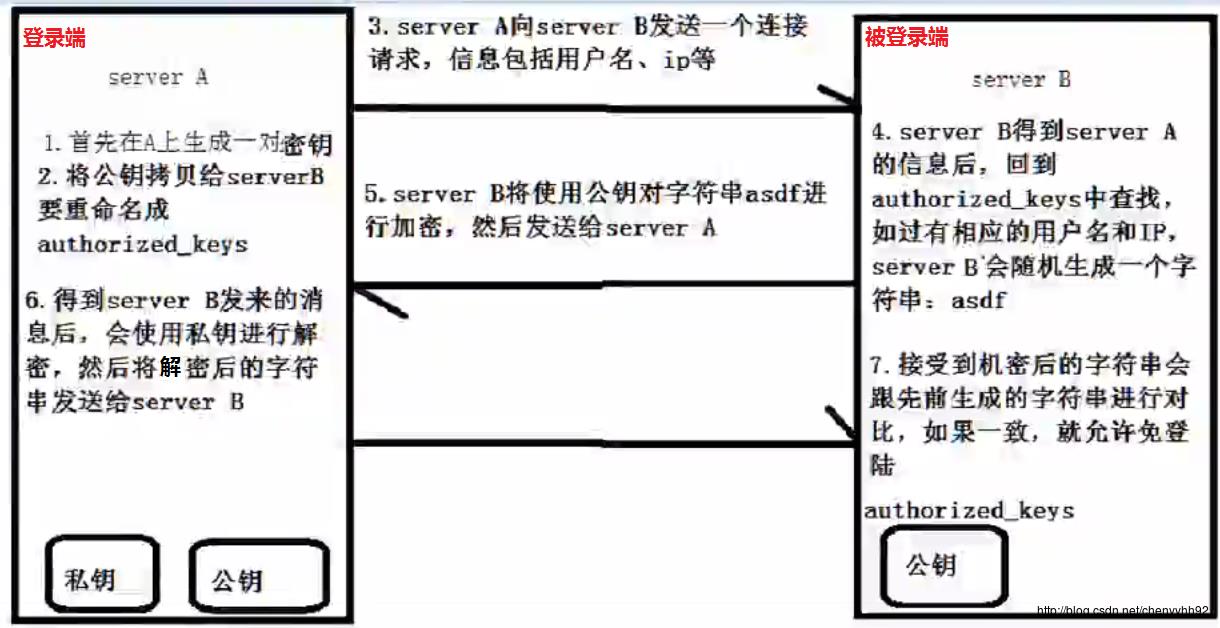
Q:为什么要设置免密码登录?
A:因为分布式应用程序,每台机器都有不同的进程,而整个分布式应用程序要想能起起来,需要各个机器上的进程都起起来并且还需要它们之间的配合。而每台机器上都有不同的进程需要启动,我们想做到在一台机器上能启动整个分布式应用,就需要达到在一台机器上能启动其他机器上的进程的目的。这个时候就需要免密码登录。
例如在node1上敲例如
start-all.sh等命令,它为什么能启动整个分布式应用呢?是因为node1远程登录到了其他节点,启动了其他节点的进程,从而达到启动整个分布式应用的目的。其实不配置免密码登录,HDFS一样能启动起来,免密码只是为了运维方便,如果不设置,每次手动去敲会很麻烦。
ssh-keygen -t rsa:产生密钥,位于~/.ssh文件夹中cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
验证:
ssh localhost然后两次exit宿主机上安装WinSCP(远程传输数据)
rm -rf /usr/local/*:这些东西用不到,我觉得可以全部删掉- 将JDK和hadoop拷贝到客户机
- 安装JDK
- 安装、配置hadoop
tar -zxvf hadoop-x.y.z.tar.gzmv hadoop-x.y.z hadoop
配置hadoop、JDK
vi /etc/profile,加下面几行export JAVA_HOME=/usr/local/jdkexport HADOOP_HOME=/usr/local/hadoopexport PATH=$HADOOP\\_HOME/bin:$JAVA\\_HOME/bin:$PATHsource /etc/profile
验证
java -version
修改
$HADOOP\\_HOME/conf下的4个配置文件(在WinSCP上面修改)hadoop-env.sh:修改该文件中被#注释掉的JAVA_HOME改成
export JAVA_HOME=/usr/local/jdk/core-site.xml:(配置NameNode进程)
<configuration> <property> <name>fs.default.name</name> <value>hdfs://hadoop0:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop/tmp</value> <description>HDFS的工作目录</description> </property> </configuration>hdfs-site.xml:
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> </configuration>mapred-site.xml:(配置JobTracker进程的主机)(TaskTracker不用配,默认每个DateNode上跑一个TaskTracker)
<configuration> <property> <name>mapred.job.tracker</name> <value>hadoop0:9001</value> </property> </configuration>
对hadoop进行格式化:
hadoop namenode -format启动hadoop:
start-all.sh可以用命令jps查看启动的java进程,
发现有5个。它们分别是:
NameNode、DataNode、SecondaryNameNode、JobTracker、TaskTracker可以去跟踪NameNode源码查看,它既是RPC服务端(里面有
RPC.getServer(..., ..., ..., ...)方法调用),又是一个web服务器(里面有一个org.mortbay.jetty.Server类成员变量)也可以用浏览器来查看,
在浏览器地址栏输入:yourhostname:50070,
回车即可yourhostname:50070中能看到NameNode,
说明NameNode是活着的;
yourhostname:50030中能看到Map/Reduce,
说明JobTracker是活着的若NameNode进程没有启动成功,原因可能为:
- 没有格式化
- 配置文件没有修改正确
- hostname与ip没有绑定
- SSH的免密码登录没有配置
多次格式化hadoop文件系统也是错误的!!!解决办法为:
- 删除
/usr/local/hadoop/tmp文件夹,重新格式化
- 删除
去除hadoop启动过程中的警告信息
/etc/profile中添加HADOOP_HOME_WARN_SUPRESS=1
分布式
- 确定分布式结构:
- 主结点(1个):NameNode、JobTracker、SecondaryNameNode
- 从结点(2个):DataNode、TaskTracker
- 各结点重新产生ssh加密文件;
- 编辑各结点的
/etc/hosts,在该文件中含有所有结点的ip与hostname的映射信息; - 两两结点之间的SSH免密码登录
ssh-copy-id -i remotehostnamescp /root/.ssh/authorized_keys remotehostname1:/root/.ssh remotehostname2:/root/.ssh ...
- 把hadoop0的hadoop目录下的logs和tmp删除
- 把hadoop0的jdk、hadoop文件夹复制到其他结点
- jdk的复制:
scp -r /usr/local/jdk remotehostname1:/usr/local/ - hadoop的复制同理
- jdk的复制:
- 把hadoop0的
/etc/profile复制到hadoop1和hadoop2结点,在目标结点执行source /etc/profile - 执行命令
cd /usr/local/hadoop/conf/,编辑hadoop0的配置文件slaves(vi slaves),改为从结点的主机名,分别是hadoop1和hadoop2,每个主机名各占一行。 - 格式化NameNode:
hadoop namenode -format - 执行
start-all.sh
注意: 对于配置文件core-site.xml和mapred-site.xml,在所有结点中都是相同的内容。
因此这些配置文件的内容应当在一开始搭建集群时就应该设计好,以后要避免修改。
验证: 以上步骤完成后,执行jps命令。可以看到:
- 主结点(hadoop0)上有3个java进程:SecondaryNameNode、NameNode、JobTracker。
- 从结点上有2个java进程:DataNode、TaskTracker。
- 当然也可以通过浏览器查看。
小细节: 按照上面步骤,SecondaryNameNode存放在主结点,若想把SecondaryNameNode存在其他机器(比如另一台内存较大的机器)上,则可以
- 执行命令
stop-all.sh - 执行命令
cd /usr/local/hadoop/conf/,编辑hadoop0的配置文件masters(vi masters)。
masters文件中存放SecondaryNameNode的主机名。
- 执行命令
start-all.sh
动态增加一个Hadoop结点(从结点)
- 配置新结点的环境
- 把新结点的hostname配置到主结点的slaves文件中
- 启动从结点上对应的java进程(从前面的集群安装过程知,从结点上有2个java进程:NameNode和TaskTracker)
hadoop-daemon.sh start namenodehadoop-daemon.sh start tasktracker
其它从结点上的hadoop族java进程都要在该新增结点中对应起动。
- 将新增结点的信息更新到集群中:
hadoop dfsadmin -refreshNodes
可通过浏览器查看新增的结点是否成功融入集群。
动态下架一个Hadoop结点(从结点)
- 用jps查看进程pid;
- 杀掉对应的hadoop族java进程:
kill -9 $pid
默认从结点失联10分钟时,主结点就认为该从结点已宕机。
注意
不管是伪分布式还是分布式,启动的顺序都依次为:namenode > 所有的datanode > secondarynamenode > jobtracker > 所有的tasktracker 。
还有一点要 注意: 这里有好几个端口,注意分清HTTP协议的端口和RPC协议的端口。
HDFS体系
core-site.xml中配置的是NameNode$HADOOP_HOME/conf/slaves中配置的是DataNode$HADOOP_HOME/conf/master中配置的是SecondaryNameNode
NameNode: 是整个文件系统的管理结点。
其主要功能:接受客户端的读写服务。
它维护整个:
- 文件系统的文件目录树;
- 文件/目录的元信息,例如owership和permission等;
- 每个文件对应的数据块(Block)列表;
- Block保存在哪个DataNode(由DataNode启动时上报,NameNode收到上报后存在内存中)
1.从操作系统的文件系统分层的角度来看,NameNode可以理解为逻辑文件系统(管理元信息,不包括实际内容)和文件组织系统(知道文件及其逻辑块和物理块)的总和。
2.从Linux的VFS角度去看,NameNode可以看成VFS接口。
NameNode的metadata信息在启动后会加载到内存:
- metadata存储到磁盘文件名为
fsimage - Block的位置信息不会保存在
fsimage(这个位置信息在DataNode启动上报后,一直会在内存中) - edits记录对metadata的操作日志
对metadata的修改不是马上由内存写到fsimage中,而是先写到了edits日志中。
例如,现在客户端发出一条删除某数据的请求,那么该请求被写进edits中,而此时fsimage并没有删除该数据的metadata。然后隔一段时间,edits中的日志文件和fsimage中的内容进行合并,此时,才发生真正的删除操作。
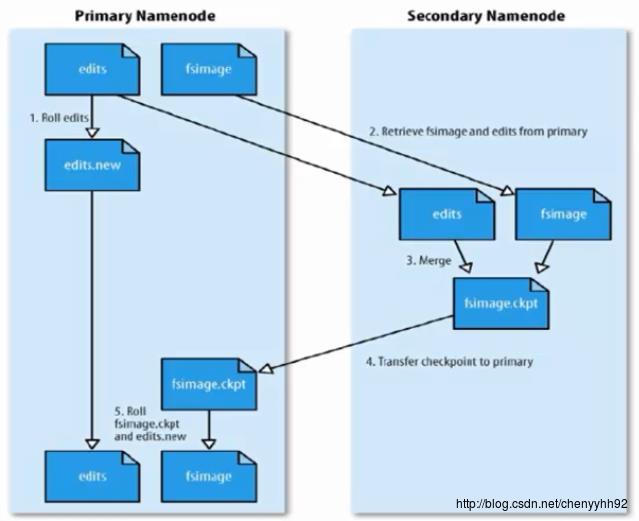
SecondaryNameNode(SNN): SNN不能和NN在同一台机器;它可以和DN在同一台,此时这台机器既是SNN节点,也是DN节点;它也可以单独在一台机器上。
它不是NN的备份(但可以备份**一部分** 元数据,也不是实时备份),它的主要工作是帮助NN合并edits-log,减少NN启动时间。 SNN执行合并的时机:(以下两条任意满足一个,就会触发合并)伪分布式:多个节点在同一台机器上。
- 根据配置文件设置的时间间隔
fs.checkpoint.period默认3600秒 - 根据配置文件设置edits-log大小
fs.checkpoint.size规定edits文件的最大值默认是64MB
合并过程图示:
DataNode: 提供真实文件数据的存储服务。
它按块(Block)存储数据。HDFS默认Block大小是64M。
不同于普通文件系统的是,HDFS中,如果一个文件小于一个数据块的大小,并不占用整个数据块的存储空间。
HDFS的DataNode在存储数据时,如果原始文件大小>64MB,则按照64MB大小切分;如果<=64MB,则占用磁盘空间是源文件实际大小。
Replication: 多副本,默认是3个。
- 第一个副本:放置在上传文件的DN;如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点;
- 第二个副本:放置在与第一个副本不同的机架节点上;
- 第三个副本:与第二个副本相同机架的节点;(同一个机架一般是同一个交换机)
- 更多副本:随机节点
HDFS读数据:
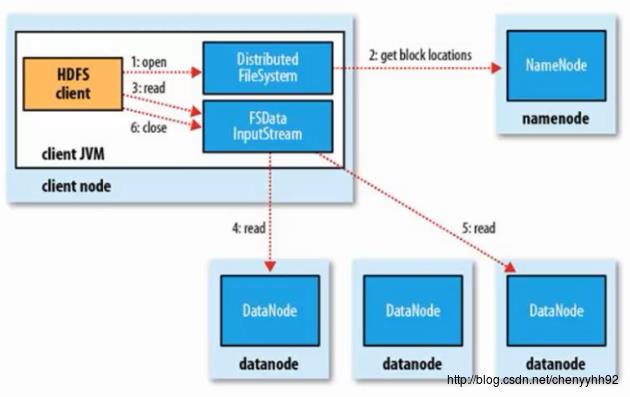
注意,图中步骤4和5是并发地去读各个Block
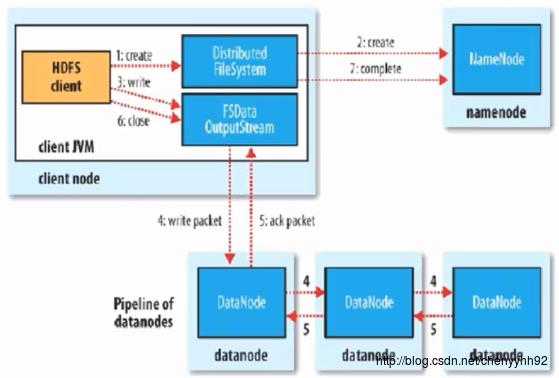
注意,图中步骤4和5是“三副本”的意思。但是client只负责写一个block,将block备份成三副本的任务,是由client所写block所在的DataNode完成的。
此外,还要注意步骤7:complete,即客户端写成功后,会给NameNode发消息让它知道写入成功。
HDFS文件权限:
其哲学是:阻止好人做错事,而不是阻止坏人做坏事。
你告诉我你是谁,我就认为你是谁。
正是这个原因,HDFS 安全性一般,它里面一般存储安全性不是那么高的数据。
HDFS安全模式:
- NameNode启动的时候,首先将映像文件(fsimage)载入内存,并执行编辑日志(edits)中的各项操作;
- 一旦在内存中成功建立文件系统元数据的映射,则创建一个新的fsimage文件(这个操作不需要SecondaryNameNode)和一个空的编辑日志;
- 此刻NameNode运行在安全模式,即NameNode的文件系统对于客户端来说是只读的(显示目录、显示文件内容等。写、删除、重命名都会失败);
- 在此阶段NameNode手机各个DataNode的报告,当数据块达到最小副本数以上时,会认为是“安全”的,在一定比例(可设置)的数据块被确定为“安全”后,再过若干时间,安全模式结束;
- 当检测到副本数不足的数据块时,该块会被复制直到达到最小副本数,系统中数据块的位置并不是由NameNode维护的,而是以块列表形式存储在DataNode中。
安全模式和数据安全有关。如果强制离开安全模式,很可能会造成数据丢失。
启动时,默认进入安全模式30s,然后退出安全模式。
安全模式时候,不能进行增删改(会报SafeModeException),只能查。
检查是否处在安全模式:hadoop dfsadmin -safemode get
进入安全模式:hadoop dfsadmin -safemode enter
离开安全模式:hadoop dfsadmin -safemode leave
NameNode和DataNode通信(DataNode主动和NameNode通信)
它们之间依赖DatanodeProtocol接口通信:
The only way a NameNode can communicate with a DataNode is by returning values from these functions(DatanodeProtocol类中的functions).
函数原型:public DatanodeCommand[] sendHeartbeat(...){}
调用者和接收者是DataNode,实现者是NameNode。
在
DatanodeProtocol通信协议中,DataNode是客户端,NameNode是服务端。DataNode通过
sendHeartbeat(...)来tells NameNode that the DataNode is still alive and well.Includes some status info,too.NameNode收到DataNode的“心跳”后,它会将反馈信息通过
sendHeartbeat(...)的返回值DatanodeCommand[]返回。It alse gives the NameNode a chance to return an array of
DatanodeCommandobjects.
A DatanodeCommand tells the DataNode to invalidata local block(s) or to copy them to other DataNodes, etc.
总结: DataNode通过sendHeartbeat(...)函数的形参将自身信息传给NameNode;NameNode对DataNode发送的命令是通过函数的返回值的方式。因此该方法的形参和返回值实际上完成了DataNode和NameNode通信的双向交互。
NameNode和DataNode源码中的namenode属性:
NameNode中,namenode属性是
ClientProtocol类型;public ClientProtocol namenode = null;
DataNode中,namenode属性是
DatanodeProtocol类型;public DatanodeProtocol namenode = null;
DataNode中心跳源码跟踪分析:
DataNode中的offerService()方法是DataNode的主循环。offerService()方法是在DataNode中的run()方法中被调用,而run()又是在DataNode的构造函数中被调用的。也就是说,run()是在NameNode**一启动就执行了** 。
MR分布式计算框架的理论基础
MR只是个分布式计算框架,除了它之外,还有很多分布式计算框架比如Storm、Spark等。
MR是离线计算框架,更适合做离线计算;Storm是流式计算框架,更适合做纯实时、毫秒级实时计算;Spark是流式的、内存计算框架,更适合做准实时、秒级计算。
所以每个计算框架都有各自的特点和适用场景。
MR设计理念:移动计算,而不是移动数据。
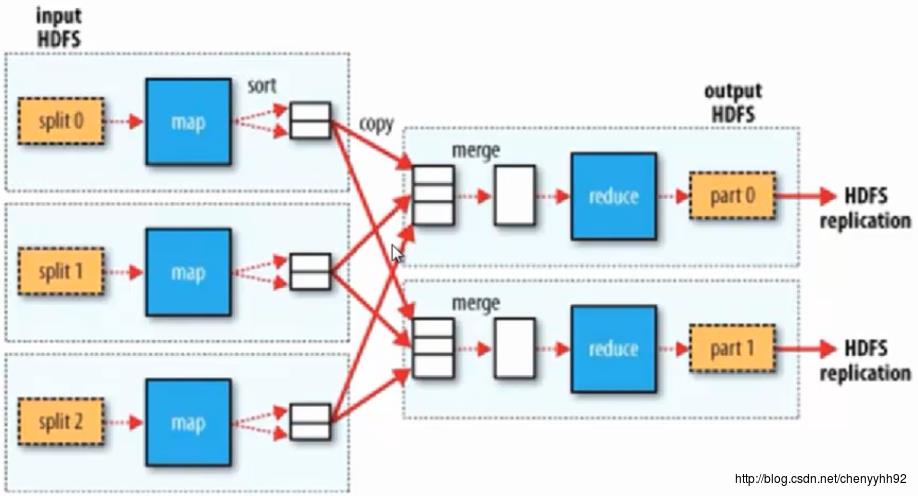
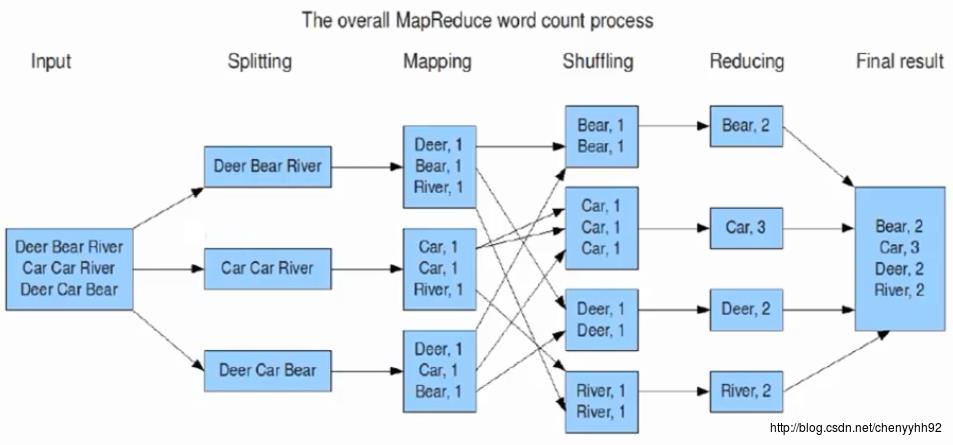
对于每一个split,都会有一个Java线程去执行map任务。
在Shuffling中,会发生合并和排序(会把相同key的进行合并)。
Reducing这一步可能只有一个Reduce任务,也可能有多个;怎么决定是一个还是多个呢,是由程序去决定的,程序可以随意地去定义有几个Reduce。
Shuffler阶段:MR最复杂的一个阶段。
- 这个阶段不由 程序猿去控制,也就是说,这个阶段都是由MR框架自动去完成的;
- 在mapper和reducer中间的一个步骤;
- 可以把mapper的输出按照某种key值重新切分和组合成n份,把key值符合某种范围的输出送到特定的reducer那里去处理;
- 可以简化reducer过程
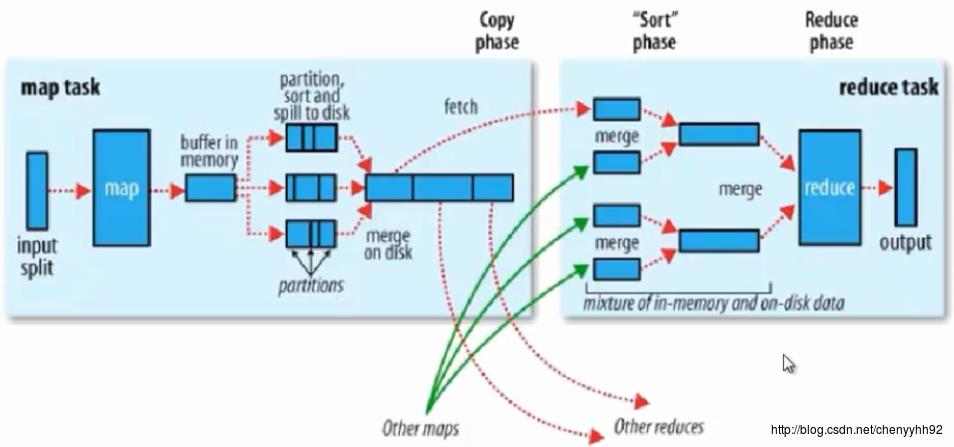
左半边图,经过
merge on disk后,放到磁盘上的数据已经分区并且排好序了。
一个map任务可能会产生多个文件,这是因为一个map任务的输入或输出可能很大,大到内存装不下;于是就需要在内存中执行一部分,然后spill(溢写)到磁盘,然后接着再执行,再spill,等等;这样一来一个map任务就可能会产生多个文件。
partition这一步在fetch的时候才会起作用;具体按什么规则分区,要看partition这部分代码怎么写的;程序猿不写也可以,因为有默认的分区规则(哈希模运算规则分区)。
分区是为了把map的输出数据进行负载均衡或者说解决数据倾斜问题的,换句话说就是为了给reducer做负载均衡。
Q:上面提到了,reduce会产生数据倾斜,为什么map不会产生数据倾斜?
A:
- map的数据从split切来的,切片段的规则是非常平均的;
- 就算切片段不平均也没关系,因为map的数据来源于DataNode上的block,每个block是64M,是一个不大的数据量,所以这种情况下map也不大会产生严重的数据倾斜。
- 而reduce就不同,不妨假如map的输出产生了10个G的数据,但是比如9个G压在了一个reduce任务上,另外1个G压在了另一个reduce任务上。由于数据量大的原因,此时的数据倾斜就很严重。
sort步骤:上面讨论了partition,现在来看sort
默认的排序按照字典序。
方便后面步骤中,map上的数据拷贝到对应的reduce任务所在的机器上去执行。
merge on disk:
这一步叫combiner。
默认合并规则是按照哈希值合并;可以自定义合并规则。
如果程序猿设置过combiner,那么在这一步中会将有相同key的key/value对的value加起来,以减少溢写到磁盘的数据量。但是,就算程序猿写了combiner代码,也不是一定有机会执行,例子见下图,
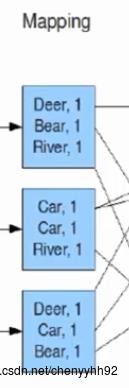
如图,对于map输出的三个结果,第一个和第三个无法使用执行combiner,但是第二个可以。第二个中的两条数据
Car, 1和Car, 1可以执行combiner、从而变成一条Car, 2。
Combiner问答:
Q:为什么使用Combiner?
A:Combiner发生在Map端,对数据进行规约处理,数据量变小了,传送到reduce端的数据量少,传输时间变短,作业的整体时间变短。
Q:为什么Combiner不作为MR运行的标配,而是可选步骤呢?
A:因为不是所有的算法都适合使用Combiner处理,例如求平均数。
Q:Combiner本身已经执行了reduce操作,为什么在Reducer阶段还要执行reduce操作呢?
A:Combiner操作发生在map端,处理一个任务锁接收的文件中的数据,不能跨map任务执行;只有reduce可以接受多个马屁任务处理的结果。
reduce:
reduce这一步是在执行reduce任务的机器上进行的(跟map任务不是同一组机器)。
map任务的执行结果需要拷贝到执行reduce任务的机器上。
Q:怎么拷贝?
A:根据partition的结果,只拷贝分给该reduce的数据。例如reduce1只拷贝分给reduce1的数据,而不会去拷贝分给reduce2、reduce3等的数据。
右图中merge这一步的不由程序猿控制。
注意左图中的
combiner和右图中的merge不同。
shuffle过程详解:
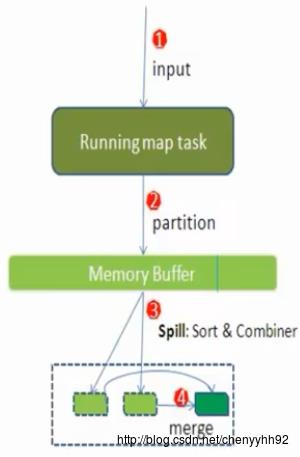
- 每个map有一个环形内存缓冲区,用于存储map任务的输出。其默认大小为100M(io.sort.mb属性),一旦达到阈值0.8(io.sort.spill.percent),一个后台线程需要将缓冲区的数据以一个临时文件的方式存放到磁盘(spill to disk),即把内容溢写到(spill)磁盘的指定目录(mapred.local.dir)下新建的一个溢出写文件中。
- 写磁盘前,要partition、sort。如果有combiner,combine排序后数据。
- 溢写(spill)是由单独线程来完成,不影响往缓冲区写map结果的线程;
- 等最后记录写完,合并全部溢出写文件为一个分区且排序的文件。
reduce过程详解:
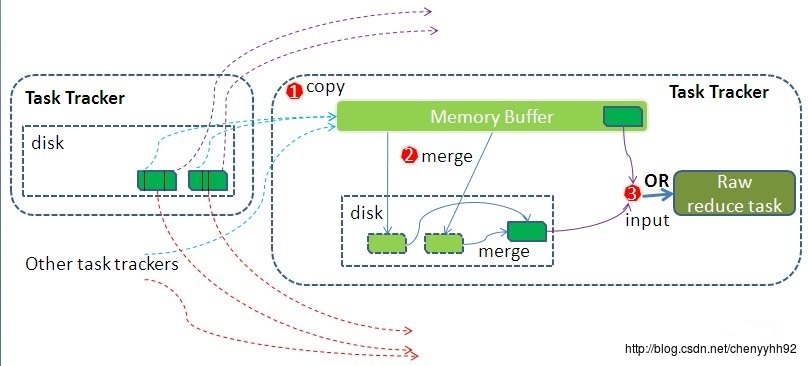
- reduce通过http方式得到输出文件的分区。
走的网络,所以这一步可以将数据压缩后再传送。
同理,reduce输出也可以压缩后再输出。 - TaskTracker为分区文件运行Reduce任务。复制阶段把Map输出复制到Reducer的内存火磁盘。一个Map任务完成,Reduce就开始复制输出。
- 排序阶段合并map输出,然后走Reduce阶段。
MR的split大小:
- max.split(100M)
- min.split(10M)
- block(64M)
- max(min.split, min(max.split, block))
MR架构的实践基础
MR是一个主从结构的,主是“`JobTracker“`,从是“`TaskTracker“`。一个MR任务提交到哪里去呢,答案是提交到“`JobTracker“`那里去。- 一主多从结构;
- 主JobTracker:
- 负责调度分配每一个子任务task运行于TaskTracker上;
- 如果发现有失败的task就要重新分配其任务到其他节点;
- 每一个hadoop集群中只有一个JobTracker,它一般运行在Master节点上。
- 从TaskTracker:
- TaskTracker主动与JobTracker通信,接收作业,并负责直接执行分配过来的每一个任务(map任务、reduce任务);
- 为了减少网络拥堵,TaskTracker最好运行在HDFS的DataNode上。
map任务有5步,reduce有3步。
**map任务处理:**Job提交作业编码步骤
- new出Job类的实例
job - 指定输入文件路径:
FileInputFormat.setInputPaths(job, $INPUT_PATH); - 指定哪个类用来格式化输入文件(以Text为例):
job.setInputFormatClass(TextInputFormat.class); - 设置Mapper类:
- 指定自定义的Mapper类:
job.setMapperClass(MyMapper.class); - 指定输出
- 指定自定义的Mapper类:
Job提交源码跟踪
和JobTracker通信
- Job类中有个
submit(...)方法,该方法能完成两件事情:一个是通过connect()方法和JobTracker连接;另一个是通过submitJobInternal(...)方法提交作业。 - Job类中
connect()方法有个内部类,内部类的run()方法中new了一个JobClient类实例。 - JobClient类构造方法中有个
init()方法,该方法中调用了createRPCProxy(...)方法。 createRPCProxy(...)方法返回值类型为JobSubmissionProtocol,这个类即为TaskTracker和JobTracker通信的协议,也是提交作业的接口。createRPCProxy(...)方法中通过RPC.getProxy(...)拿到代理对象。
小结:JobClient可以看成一个指向JobTracker的链接,拿到它就相当于拿到一个服务端的代理对象。
- Job类中有个
提交作业:下面追踪
submitJobInternal(...)(提交作业给系统的内部方法)- 该方法中有句话
jobSubmitClient.submitJob(...) - 点进去
submitJob(...)方法,发现是JobSubmissionProtocol接口的方法,而JobTracker实现了这个接口及submitJob(...)方法
小结:更准确的说,是调用了JobTracker的
submitJobInternal(...)方法,因此作业就是这样被提交到JobTracker。- 该方法中有句话
总结: 我们在程序中写的代码如何提交作业到JobTracker中?
- 代码
job.waitForCompletion(true)会依次调用两句话,因此依次发生两件事情:
connect();info = jobClient.submitJobInternal(conf);
- 在
connect()方法中,实际上创建了一个JobClient对象。在调用该对象的构造方法时,获得了JobTracker的客户端代理对象JobSubmissionProtocol。JobSubmissionProtocol的实现类是JobTracker。 - 在
jobClient.submitJobInternal(conf)方法中,调用了JobSubmissionProtocol.submitJob(...),即执行的是JobTracker.submitJob(...)。
RPC(remote procedure call)
不同java进程间的对象方法的调用。
一方称作服务端(server),一方称作客户端(client)。可见RPC是C/S结构。
server端提供对象,供client调用,被调用对象的方法的执行发生在server端。
RPC是hadoop框架运行的基础。
注意:
服务端提供的对象必须是一个接口,接口要
extends VersionedProtacal为什么要是接口呢?因为返回的代理对象,而JDK中要求反射的代理对象必须实现接口
客户端能够调用的对象中的方法必须位于对象的接口中。
Java基本类型与Hadoop常见基本类型
hadoop的数据类型要求必须实现Writable接口。
Long LongWritable
Integer IntWritable
Boolean BooleanWritable
String TextQ:java类型如何转化为hadoop基本类型?
A:直接调用hadoop类型的构造方法,或者调用set(…)方法。
Q:hadoop基本类型如何转化为java类型?
A:对于Text,需要调用toString()方法,其他类型调用get()方法。
MapReduce常见算法
- 单词计数
- 数据去重
- 排序
- Top K
- 选择
- 投影
- 分组
- 多表连接
- 单表关联
以上是关于Hadoop学习笔记的主要内容,如果未能解决你的问题,请参考以下文章
Hadoop学习笔记:使用Mrjob框架编写MapReduce
[原创]java WEB学习笔记61:Struts2学习之路--通用标签 property,uri,param,set,push,if-else,itertor,sort,date,a标签等(代码片段