TCP吞吐性能优化的吐槽与拯救
Posted dog250
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TCP吞吐性能优化的吐槽与拯救相关的知识,希望对你有一定的参考价值。
上周文章转发朋友圈后,我补充了个评论,我不晓得为什么RDMA底层传输协议还在复用TCP那一套,只是为了重用而重用吗?完全可以重写的协议还在GBN,还在将SACK作为GBN的优化,沿着老路重走一遍…请用QUIC吧,但这话不能对RDMA说,它用不了QUIC,转念一想,广域网传输也不是非用QUIC替代TCP,剥离导致TCP性能缺陷的因素,学着QUIC的样子改掉它,依然留着TCP的躯壳,作为TCP-ng,岂不是鸠占鹊巢更美妙?抛砖引玉,写下本文。
TCP吞吐性能已经经不住优化了,因为它的固有缺陷来自于它的原始设计。
TCP术语太多,滑动窗口,慢启动,拥塞避免,快速重传,快速恢复,超时重传,几乎任何资料都不可避免地以上述术语为线索,TCP的复杂性,无论是协议还是实现,均来自于此。
如此复杂的协议,竟然仅仅可用(幸亏AIMD也能让它收敛),毫无效率可言,够了!
最初的设计中,TCP只有积累确认,为让TCP滑动窗口持续滑动,必须以dupACK识别丢包,然后GBN(go-back-N),其中N指示重传的数量,这是一个简洁的设计,但低效。TCP原始设计的状态机为:
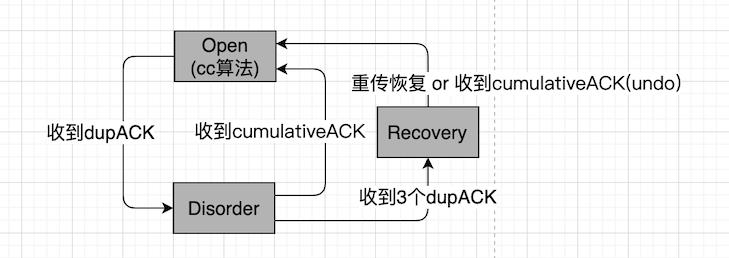
以Linux TCP实现为例,关于这个状态机的各状态描述如下:
/* Linux NewReno/SACK/ECN state machine.
* --------------------------------------
*
* "Open" Normal state, no dubious events, fast path.
* "Disorder" In all the respects it is "Open",
* but requires a bit more attention. It is entered when
* we see some SACKs or dupacks. It is split of "Open"
* mainly to move some processing from fast path to slow one.
* "CWR" CWND was reduced due to some Congestion Notification event.
* It can be ECN, ICMP source quench, local device congestion.
* "Recovery" CWND was reduced, we are fast-retransmitting.
* "Loss" CWND was reduced due to RTO timeout or SACK reneging.
...
*/
自SACK被引入直到RACK/BBR,围绕TCP原始设计的优化终于再也无法满足需求,并越来越成为吞吐性能提升的障碍。成为性能提升阻碍的原因不外乎:
- 状态机依然根据原始设计转换,在非Open状态接管拥塞控制算法。
是时候拿掉这个状态机了,就像赶走牵引蒸汽机的马匹一样。
为此需要设计一个新协议。但evolution比revolution更容易被接受。新协议不是QUIC,而是TCP-ng。重用TCP协议头是它的最大特征。
大致介绍一下TCP-ng对TCP做了哪些扩展以及如何做的。
首先,将TCP协议中不合时宜的机制剥离,如果不晓得哪些是不合时宜的,看看QUIC的方式:
- 收端不再支持reneging,内存已不再是瓶颈,手机内存动辄10G+。
- SACK段数量不再受限,带宽已足够,不必再压缩协议头空间。
- end-to-end越来越普遍得使用TLV而不再青睐定长的短协议头。
以上措施之外,需要增加的新机制:
- 以发送顺序而不是序列号标识传输,分离end-to-end和传输逻辑。
- 完备的不依赖TCP拥塞状态机的拥塞控制算法。
综上,TCP-ng需要做的是:
- 取消reneging。QUIC不允许reneging。
- 完全的SACK。QUIC即完全SACK。
- 独立的传输。QUIC中的packet ID
- 解放拥塞控制算法。
幸运的是,以Linux TCP为例,需要修改的地方非常少,分别来看就是:
- 收端和发端删除reneging相关的代码。
- 收端将所有SACK段放入payload。发端用payload解析出的SACK段扫描retrans rbtree。
- 发送端实现完整的RACK,发送时不区分new data和retrans。
- 取消拥塞状态机,cc算法根据采集带宽来自己决策。
取消reneging的风险是,乱序太多或RTT太抖动的弱网环境,收端内存占用会很大,空洞长时间无法填补,严重情况下会出现类DDoS症状。
取消拥塞状态机,TCP的复杂性就砍掉了大部分,背后的思想很简单:
- 拥塞一定会带来测量吞吐及RTT的变化,与丢包无关。
- 丢包一定可以靠RACK重传恢复。如下图:
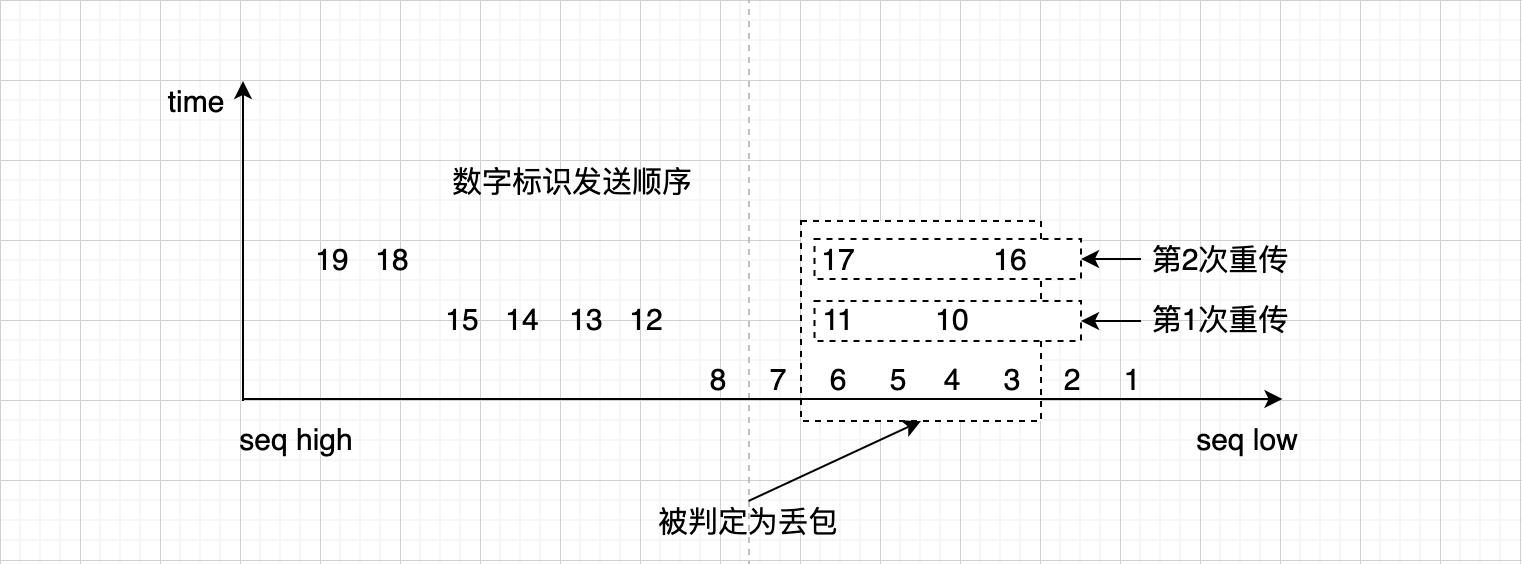
Linux TCP实现了RACK之后,其实已经很完美了,启用RACK后,完全依赖RACK来mark lost,而不再使用oneshot的tcp_update_scoreboard,这表明Linux RACK-Based TCP已经完全基于时间序发包了,此前的scoreboard已经成了历史。
核心问题SACK段数量受限以及时间序发送问题已经解决,TCP-ng便得以快速滑动窗口,HoL得到极大缓解,剩下的就是细枝末节了。
TCP-ng的不足是,ACK依然无法和transmit相对应,造成DSACK误判,undo效率降低。
以Linux TCP实现为例,当前的undo操作依赖于:
tp->undo_retrans == 0
该字段在收到DSACK时递减。由于无法区分一次重传报文带来的DSACK还是两次重传中其中一次带来的DSACK,有可能会造成undo失败并影响重传效率:
- 进入重传状态后,只要之前有丢失的重传依然未决,本次undo就会失败。
- retrans_out占据inflight份额,重传窗口无法张开。
好在packets_out是准的,下一轮packets_out清零之时可顺便清除retrans_out,但迟到的DSACK会带来warning。所以我建议在RTO时无条件清除retrans_out。
彻底解决这个问题需要增加类似QUIC的packet id字段。为此,TCP-ng2我这么建议:
- 将SACK option分裂为3个type:type1为packet number(8字节,必选); type2为SACK(in payload);type3为stream ID(4字节,可优化接收负载均衡,或自研网卡优化RSS)
- ACK中SACK段格式为begin data-seq:begin packet-seq~end data-seq:end packet-seq的映射段,用于发端检测并对应DSACK。
- data seq和packet seq全部采用字节单位,不影响TSO/GSO,GRO/LRO等offload机制的运行。
undo只是降低一些重传率,对整体的带宽利用率提高影响有限,且机制复杂,为了不引入更多复杂性从而引发额外问题,不建议实现undo。
…
TCP-ng重用TCP协议头及其大多数原有处理逻辑,其原因是:
- 主观原因:我太懒惰且编程水平太差,重写一个新协议虽好看但beyond my ability。
- 客观原因:TCP-ng兼容性极好。
TCP有诸多缺陷,设计一个针对性弥补这些缺陷的新协议并不是一件很难的事,但在工程和生态视角,将新协议部署落地就太难了,一个很简单的例子就是IPv6。
IPv4的问题众所周知,IPv6逐一针对性解决,可是IPv6的部署之路却很艰难。
与之类似,QUIC也一样。
妇孺皆知的是QUIC对状态防火墙不友好。何止状态防火墙,QUIC对所有途径的运营商设备都不友好:
- UDP没有状态机,设备无法跟踪连接,便无法精确实施ACL,计费等关键动作。
- QUIC over UDP,作为应用层协议迄今没有统一标准,且变化多端,设备商的固化升级成本太高。
- QUIC协议并非没有生态,而是各大厂商自立门户,生态太多,无法协调。
- QUIC用户态的cc算法很容易被不懂拥塞控制为何物的人乱搞,严重破坏互联网公平。
…
所以,我选择不修改TCP协议头的方式,所有的设备还是和原来一样运作,新协议完全透明经过。再也没有人说新协议不友好了。
下面是我之前写的一篇欺骗网络设备的内核插件,它可以将UDP假装成TCP:https://github.com/marywangran/pseudotcp-tunnel
最后,演示一个扩展TCP协议的实际例子。
当前主机性能相比1980年代已经大幅提升,进程容量大大增加,为提升主机搜索可用端口号的效率(connect/bind中的逻辑),需要扩展TCP端口号位宽。下面介绍如何不改变TCP协议头而将端口号扩展成24位:
- 新端口号的低16位用TCP协议头中的端口号字段表示。
- 新端口号的高8位用TCP协议头中2个新的8位自定义option表示。
- 发送端自行拼接端口号组装数据包。
- 接收端解封装端口号多路复用。
浙江温州皮鞋湿,下雨进水不会胖。
以上是关于TCP吞吐性能优化的吐槽与拯救的主要内容,如果未能解决你的问题,请参考以下文章