协同过滤推荐算法
Posted 你隔壁的小王
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了协同过滤推荐算法相关的知识,希望对你有一定的参考价值。

一、协同过滤思想简介
协同过滤,从字面上理解,包括协同和过滤两个操作。首先我们在外出和朋友吃饭的时候肯定会问身边的朋友哪些饭店味道比较好,看看最近有什么美食推荐,而我们一般更倾向于从口味比较类似的朋友那里得到推荐。这就是协同过滤的核心思想。
所谓协同就是利用群体的行为来做决策(推荐),生物上有协同进化的说法,通过协同的作用,让群体逐步进化到更佳的状态。对于推荐系统来说,通过用户的持续协同作用,最终给用户的推荐会越来越准。而过滤,就是从可行的决策方案中将用户喜欢的方案找出来,协同过滤就是对从群体的行为中来寻找存在的普遍相似性,通过相似性来对用户做出决策和推荐。
协同过滤利用了两个非常朴素的自然哲学思想:“群体的智慧”和“相似的物体具备相似的性质”,群体的智慧从数学上讲应该满足一定的统计学规律,是一种朝向平衡稳定态发展的动态过程,越相似的物体化学及物理组成越一致,当然表现的外在特性会更相似。虽然这两个思想很简单,也很容易理解,但是正因为思想很朴素,价值反而非常大。所以协同过滤算法原理很简单,但是效果很不错,而且也非常容易实现。
协同过滤推荐算法分为两类,分别是基于用户的协同过滤算法(user-based collaboratIve filtering),和基于物品的协同过滤算法(item-based collaborative filtering)。
二、协同过滤算法原理介绍
简单的说就是:物以类聚,人以群分。所谓物以类聚,就是计算出每个物品最相似的物品列表,可以为用户推荐相似的物品。所谓人以群分,就是我们可以将与该用户相似的用户喜欢过的物品推荐给该用户。
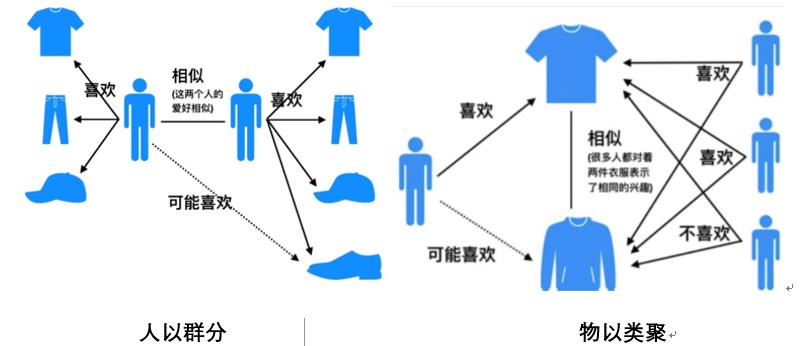
三、基于用户的协同过滤算法描述
基于用户的协同过滤算法的实现主要分为两个步骤:
- 1)如何找到和你有相似爱好的人,也就是要计算数据的相似度:
- 2)通过相似爱好的人来推荐商品
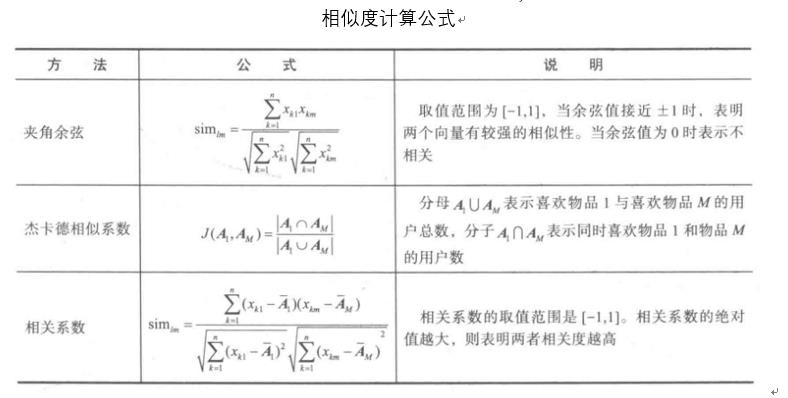
计算相似度需要根据数据特点的不同选择不同的相似度计算方法,有几个常用的计算方法:
我们在寻找有有相同爱好的人的时候,可能会找到许多个,例如几百个人都喜欢A商品,但是这几百个人里,可能还有几十个人与你同时还喜欢B商品,他们的相似度就更高,我们通常设定一个数K,取计算相似度最高的K个人称为最相邻的K个用户,作为推荐的来源群体。
这里存在一个小问题,就是当用户数据量十分巨大的时候,在所有人之中找到K个基友花的时间可能会比较长,而且实际中大部分的用户是和你没有什么关系的,所以在这里需要用到反查表
所谓反查表,就是比如你喜欢的商品有A、B、C,那就分别以ABC为行名,列出喜欢这些商品的人都有哪些,其他的人就必定与你没有什么相似度了,从这些人里计算相似度,找到K个人
通过这K个人推荐商品
| 你 | A | B | C | D |
| X(相似度30%) | √ | √ | √ | |
| Y(相似度40%) | √ | √ |
我们假设找到的人的喜好程度如下,那么对于产品ABCD,推荐度可以计算为:
- A:1*0.3=0.3
- B:1*0.3=0.3
- C:1*0.4=0.4
- D:1*0.3+1*0.4=0.7
很明显,我们首先会推荐D商品,其次是C商品,再后是其余商品
当然我们也可以采用其他的推荐度计算方法,但是我们一定会使用得到的相似度0.3和0.4,也即一定是进行加权的计算。
基于用户的协同推荐算法的步骤可以总结为:
1.计算其他用户的相似度,可以使用反查表除掉一部分用户
2.根据相似度找到最相似的K个用户
3.在这些邻居喜欢的物品中,根据与你的相似度算出每一件物品的推荐度
4.根据相似度推荐物品
四、基于物品的协同过滤算法(item-based collaborative filtering)
基于物品的协同过滤算法(简称ItemCF 算法)主要分为2个步骤:
- 1)计算物品之间的相似度;
- 2)根据物品的相似度和用户的历史行为给用户生成推荐列表;
其中,关于物品相似度计算的方法有夹角余弦、杰卡德(Jaccard)相似系数和相关系数等。
将用户对某一产品的喜好或者评分作为一个向量,例如用户对产品1的评分为

,对产品m的评分或者喜好程度为

其中m为物品,n为用户数
计算各个物品之间的相似度之后,即可构成一个物品之间的相似度矩阵,通过相似度矩阵,推荐算法会给用户推荐与其物品最相似的K个物品,推荐系统是根据物品的相似度以及用户的历史行为对用户的兴趣度进行预测并推荐的,在评价模型的时候一般是将数据集划分成训练集和测试集两部分。模型通过在训练集的数据上进行训练学习得到推荐模型,然后在测试集数据上进行模型预测,最终统计出相应的评测指标来评价模型预测效果的好与坏。
模型的评测采用的方法是交叉验证法。交叉验证法即将用户行为数据集按照均匀分布随机分成M份,挑选一份作为测试集,将剩下的M-1份作为训练集。然后在训练集上建立模型,并在测试集上对用户行为进行预测,统计出相应的评测指标。为了保证评测指标并不是过拟合的结果,需要进行M次实验,并且每次都使用不同的测试集。最后将M次实验测出的评测指标的平均值作为最终的评测指标。
基于用户的协同过滤推荐算法进行推荐,构建模型的流程如下图所示:
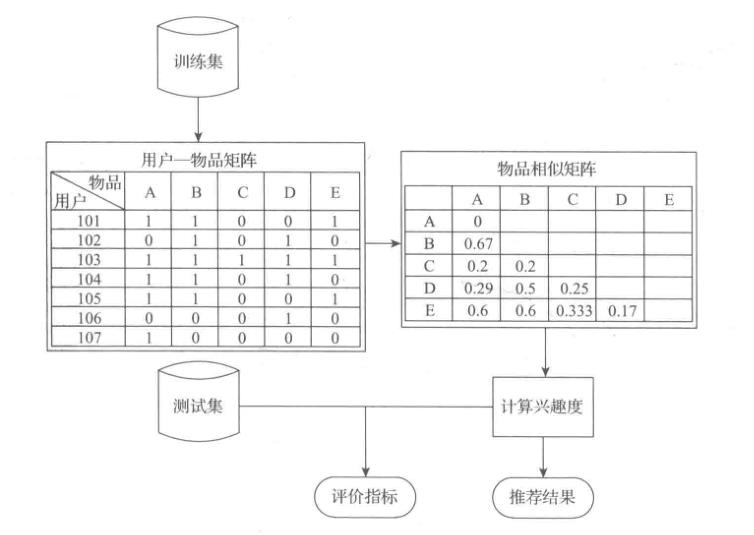
训练集与测试集是通过交叉验证的方法划分后的数据集,通过协同过滤算法的原理可知,在建立推荐系统时,建模的数据量越大越能消除数据中的随机性,得到的模型准确度也就越高,但是随之而来也会导致计算时长过长。
基于物品的协同过滤算法的优缺点
优点:
- 可以离线完成相似性步骤,降低了在线计算量,提高了推荐效率,可以利用用户的历史行为给用户做出推荐解释,结果容易让客户信服
缺点:
- 现有的协同过滤算法没有充分利用到用户间的差别,使计算得到的相似度不够准确,导致影响了推荐精度;此外,用户的兴趣是随着时间不断变化的,算法可能对用户新点击兴趣的敏感性较低,缺少一定的实时推荐,从而影响了推荐质量。
- 基于物品的协同过滤适用于物品数明显小于用户数的情形,如果物品数很多,会导致计算物品相似度矩阵代价巨大。
- 不积跬步,无以至千里

以上是关于协同过滤推荐算法的主要内容,如果未能解决你的问题,请参考以下文章