第3次翻译了 Pandas 官方文档,叒写了这一份R万字肝货操作!
Posted AI科技大本营
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第3次翻译了 Pandas 官方文档,叒写了这一份R万字肝货操作!相关的知识,希望对你有一定的参考价值。

作者 | 黄伟呢
来源 | 数据分析与统计学之美
今天,我继续为大家讲述Pandas如何实现R语言的相关操作。
由于 Pandas 旨在提供人们使用 R 进行的大量数据操作和分析功能,因此本页开始提供更详细的 R 语言及其与 Pandas 相关的许多第三方库的介绍。
与 R 和 CRAN 库相比,我们关心以下几点:
① 功能/灵活性:每个工具可以/不能做什么;
② 性能:操作的速度。硬数字/基准是可取的;
③ 易于使用:是一种更容易/更难使用的工具吗(鉴于并排代码比较,您可能必须对此做出判断);
此页面还为这些 R 包的用户提供了一些翻译指南。
要将 DataFrame 对象从 Pandas 传输到 R,一种选择是使用 HDF5 文件。
1. 快速参考
我们将从快速参考指南开始,将使用 dplyr 的一些常见 R 操作与 Pandas 等价配对。
① 查询、过滤、采样
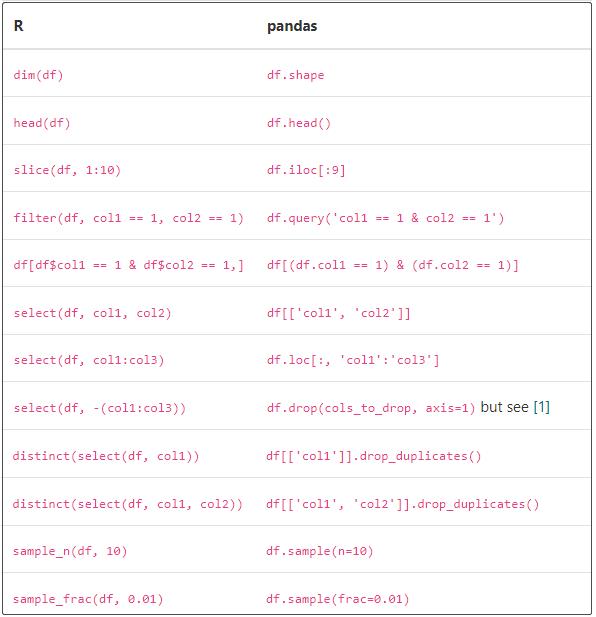
R对列子范围 ( select(df, col1:col3) )的简写可以在 Pandas 中清晰地使用,如果您有列列表,例如 df[cols[1:3]] 或 df.drop(cols[1:3]),但按列名执行此操作有点麻烦。
② 排序
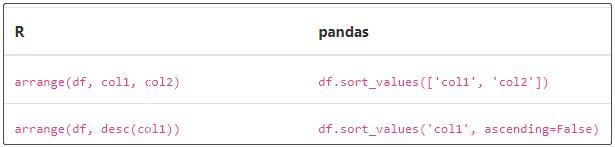
③ 转换
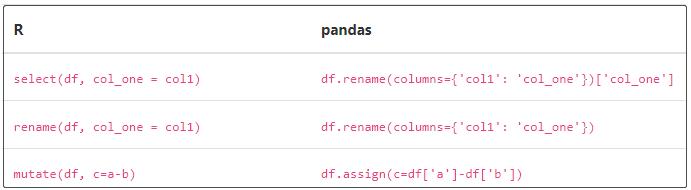
④ 分组和汇总

2. 基于R
① 用 R 的 c 切片
R 使得按名称访问 data.frame 列变得容易。
df <- data.frame(a=rnorm(5), b=rnorm(5), c=rnorm(5), d=rnorm(5), e=rnorm(5))
df[, c("a", "c", "e")]或按整数位置。
df <- data.frame(matrix(rnorm(1000), ncol=100))
df[, c(1:10, 25:30, 40, 50:100)]在 Pandas 中,按名称选择多列很简单。
df = pd.DataFrame(np.random.randn(10, 3), columns=list("abc"))
df[["a", "c"]]
df.loc[:, ["a", "c"]]结果如下:

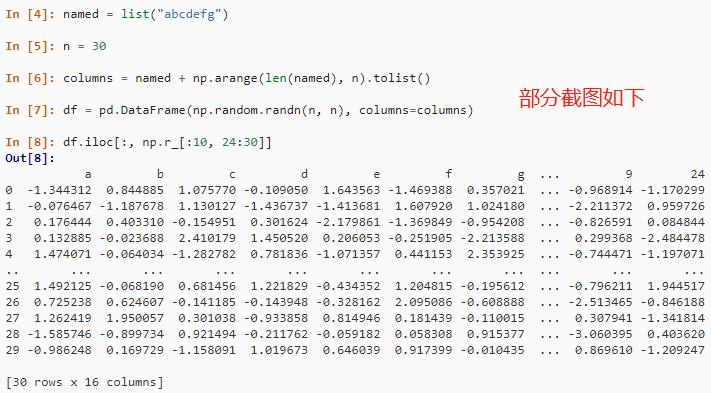
可以通过 iloc 索引器属性和 numpy.r_ 的组合,来实现按整数位置选择多个非连续列。
named = list("abcdefg")
n = 30
columns = named + np.arange(len(named), n).tolist()
df = pd.DataFrame(np.random.randn(n, n), columns=columns)
df.iloc[:, np.r_[:10, 24:30]]结果如下:
② aggregate
在 R 中,您可能希望将数据拆分为子集并计算每个子集的平均值。使用名为 df 的 data.frame 并将其分为 by1 和 by2 组。
df <- data.frame(
v1 = c(1,3,5,7,8,3,5,NA,4,5,7,9),
v2 = c(11,33,55,77,88,33,55,NA,44,55,77,99),
by1 = c("red", "blue", 1, 2, NA, "big", 1, 2, "red", 1, NA, 12),
by2 = c("wet", "dry", 99, 95, NA, "damp", 95, 99, "red", 99, NA, NA))
aggregate(x=df[, c("v1", "v2")], by=list(mydf2$by1, mydf2$by2), FUN = mean)groupby() 方法类似于基 R的聚合函数。
df = pd.DataFrame(
"v1": [1, 3, 5, 7, 8, 3, 5, np.nan, 4, 5, 7, 9],
"v2": [11, 33, 55, 77, 88, 33, 55, np.nan, 44, 55, 77, 99],
"by1": ["red", "blue", 1, 2, np.nan, "big", 1, 2, "red", 1, np.nan, 12],
"by2": ["wet","dry",99,95,np.nan,"damp",95,99,"red",99,np.nan,np.nan,]
)
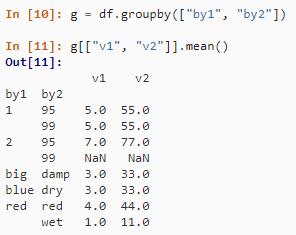
g = df.groupby(["by1", "by2"])
g[["v1", "v2"]].mean()结果如下:
③ match(%in%)
在 R 中选择数据的一种常用方法是使用 %in% ,它是使用函数 match 定义的。运算符 %in% 用于返回一个逻辑向量,指示是否存在匹配。
s <- 0:4
s %in% c(2,4)isin() 方法类似于 R %in% 运算符。
s = pd.Series(np.arange(5), dtype=np.float32)
s.isin([2, 4])结果如下:

match 函数在其第二个参数中,返回其第一个参数的匹配位置向量。
s <- 0:4
match(s, c(2,4))④ tapply
tapply类似于aggregate,但数据可以在一个参差不齐的数组中,因为子类的大小可能是不规则的。使用名为baseball的data.frame,并根据数组检索信息team。
baseball <-
data.frame(team = gl(5, 5,
labels = paste("Team", LETTERS[1:5])),
player = sample(letters, 25),
batting.average = runif(25, .200, .400))
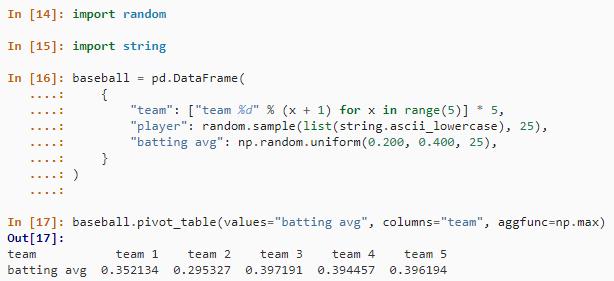
tapply(baseball$batting.average, baseball.example$team,max)在 Pandas 中,我们可以使用 pivot_table() 方法来处理这个。
import random
import string
baseball = pd.DataFrame(
"team": ["team %d" % (x + 1) for x in range(5)] * 5,
"player": random.sample(list(string.ascii_lowercase), 25),
"batting avg": np.random.uniform(0.200, 0.400, 25)
)
baseball.pivot_table(values="batting avg", columns="team", aggfunc=np.max)结果如下:
⑤ subset
query() 方法类似于基本的 R 子集函数。在 R 中,您可能想要获取 data.frame 的某些行,其中一列的值小于另一列的值。
df <- data.frame(a=rnorm(10), b=rnorm(10))
subset(df, a <= b)
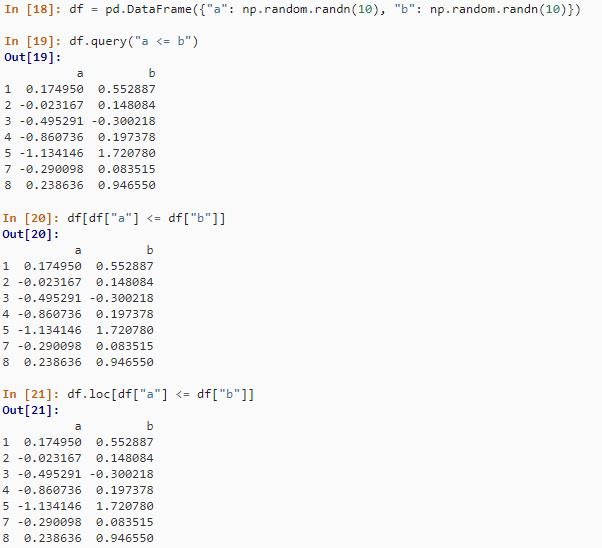
df[df$a <= df$b,]在 Pandas 中,有几种方法可以执行子集化。您可以使用 query() 或传递表达式,就好像它是索引/切片以及标准布尔索引一样。
df = pd.DataFrame("a": np.random.randn(10), "b": np.random.randn(10))
df.query("a <= b")
df[df["a"] <= df["b"]]
df.loc[df["a"] <= df["b"]]结果如下:
⑥ with
使用df在 R 中调用的带有列的 data.frame 的表达式a, b将使用with如下方式进行评估。
df <- data.frame(a=rnorm(10), b=rnorm(10))
with(df, a + b)
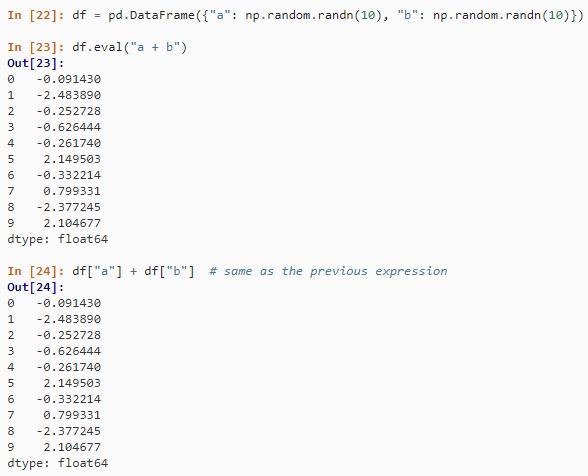
df$a + df$b在 Pandas 中,使用 eval() 方法的等效表达式为。
df = pd.DataFrame("a": np.random.randn(10), "b": np.random.randn(10))
df.eval("a + b")
df["a"] + df["b"]结果如下:
在某些情况下eval()会比纯 Python 中的评估快得多。
3. plyr库
plyr 是用于数据分析的拆分-应用-组合策略的 R 库。这些函数围绕 R 中的三个数据结构展开,a 代表数组,l 代表列表,d 代表 data.frame。下表显示了如何在 Python 中映射这些数据结构。
① ddply库
在 R 中使用名为 df 的 data.frame 的表达式,您要在其中按月汇总 x。
require(plyr)
df <- data.frame(
x = runif(120, 1, 168),
y = runif(120, 7, 334),
z = runif(120, 1.7, 20.7),
month = rep(c(5,6,7,8),30),
week = sample(1:4, 120, TRUE)
)
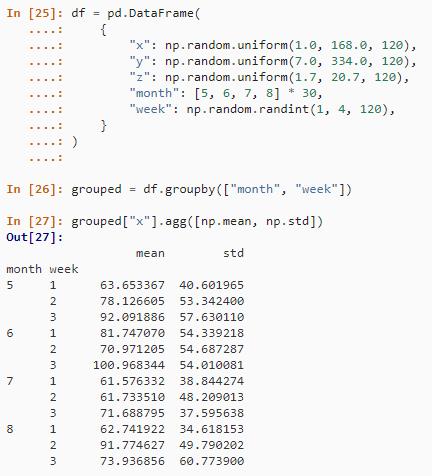
ddply(df, .(month, week), summarize,
mean = round(mean(x), 2),
sd = round(sd(x), 2))在 Pandas 中,使用 groupby() 方法的等效表达式为。
df = pd.DataFrame(
"x": np.random.uniform(1.0, 168.0, 120),
"y": np.random.uniform(7.0, 334.0, 120),
"z": np.random.uniform(1.7, 20.7, 120),
"month": [5, 6, 7, 8] * 30,
"week": np.random.randint(1, 4, 120)
)
grouped = df.groupby(["month", "week"])
grouped["x"].agg([np.mean, np.std])结果如下:
4. 重塑
① melt.array
使用 R 中称为 a 的 3 维数组的表达式,您希望将其融合到 data.frame 中。
a <- array(c(1:23, NA), c(2,3,4))
data.frame(melt(a))在 Python 中,由于 a 是一个列表,您可以简单地使用列表推导式。
a = np.array(list(range(1, 24)) + [np.NAN]).reshape(2, 3, 4)
pd.DataFrame([tuple(list(x) + [val]) for x, val in np.ndenumerate(a)])结果如下:

② melt.list
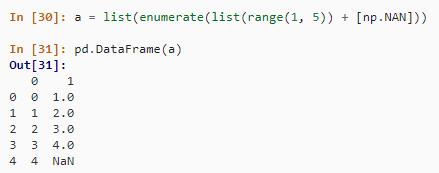
使用 R 中称为 a 的列表的表达式,您要将其融合到 data.frame 中。
a <- as.list(c(1:4, NA))
data.frame(melt(a))在 Python 中,此列表将是元组列表,因此 DataFrame() 方法会根据需要将其转换为数据帧。
a = list(enumerate(list(range(1, 5)) + [np.NAN]))
pd.DataFrame(a)结果如下:
③ melt.data.frame
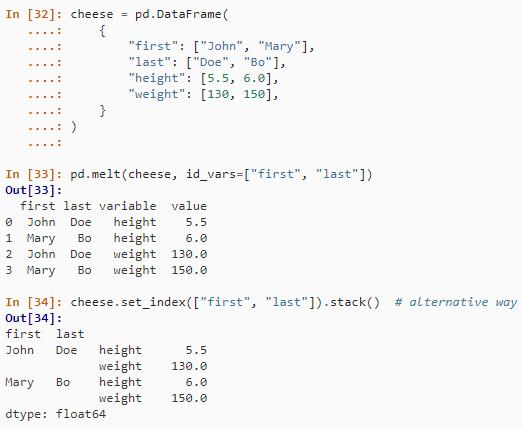
在 R 中使用名为 cheese 的 data.frame 的表达式,您要在其中重塑 data.frame。
cheese <- data.frame(
first = c('John', 'Mary'),
last = c('Doe', 'Bo'),
height = c(5.5, 6.0),
weight = c(130, 150)
)
melt(cheese, id=c("first", "last"))在 Python 中,melt() 方法与 R 等效。
cheese = pd.DataFrame(
"first": ["John", "Mary"],
"last": ["Doe", "Bo"],
"height": [5.5, 6.0],
"weight": [130, 150]
)
pd.melt(cheese, id_vars=["first", "last"])
cheese.set_index(["first", "last"]).stack() # alternative way结果如下:
④ cast
在 R 中 acast 是一个表达式,它使用 R 中名为 df 的 data.frame 来转换为更高维数组。
df <- data.frame(
x = runif(12, 1, 168),
y = runif(12, 7, 334),
z = runif(12, 1.7, 20.7),
month = rep(c(5,6,7),4),
week = rep(c(1,2), 6)
)
mdf <- melt(df, id=c("month", "week"))
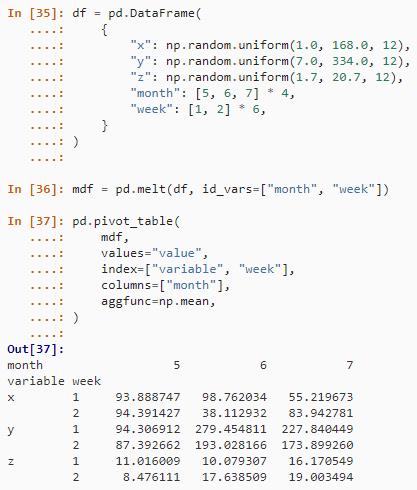
acast(mdf, week ~ month ~ variable, mean)在 Python 中,最好的方法是使用 pivot_table()。
df = pd.DataFrame(
"x": np.random.uniform(1.0, 168.0, 12),
"y": np.random.uniform(7.0, 334.0, 12),
"z": np.random.uniform(1.7, 20.7, 12),
"month": [5, 6, 7] * 4,
"week": [1, 2] * 6
)
mdf = pd.melt(df, id_vars=["month", "week"])
pd.pivot_table(
mdf,
values="value",
index=["variable", "week"],
columns=["month"],
aggfunc=np.mean
)结果如下:
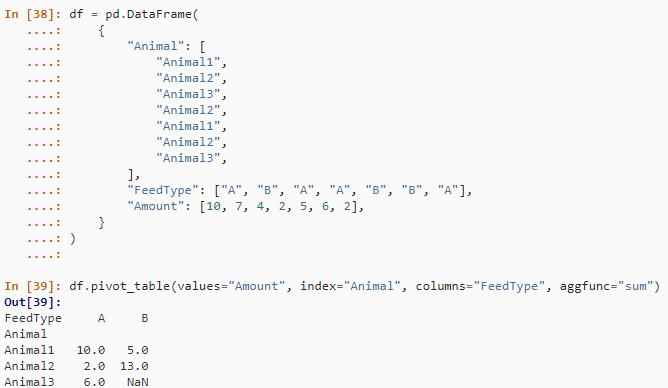
类似的 dcast 使用 R 中名为 df 的 data.frame 来聚合基于 Animal 和 FeedType 的信息。
df <- data.frame(
Animal = c('Animal1', 'Animal2', 'Animal3', 'Animal2', 'Animal1',
'Animal2', 'Animal3'),
FeedType = c('A', 'B', 'A', 'A', 'B', 'B', 'A'),
Amount = c(10, 7, 4, 2, 5, 6, 2)
)
dcast(df, Animal ~ FeedType, sum, fill=NaN)
# Alternative method using base R
with(df, tapply(Amount, list(Animal, FeedType), sum))Python 可以通过两种不同的方式来解决这个问题。首先,类似于上面使用pivot_table()。
df = pd.DataFrame(
"Animal": ["Animal1","Animal2","Animal3","Animal2","Animal1","Animal2","Animal3",],
"FeedType": ["A", "B", "A", "A", "B", "B", "A"],
"Amount": [10, 7, 4, 2, 5, 6, 2]
)
df.pivot_table(values="Amount", index="Animal", columns="FeedType", aggfunc="sum")结果如下:
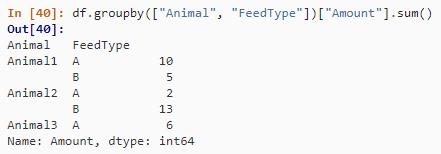
第二种方法是使用 groupby() 方法。
df.groupby(["Animal", "FeedType"])["Amount"].sum()结果如下:
⑤ factor
pandas 具有用于分类数据的数据类型。
cut(c(1,2,3,4,5,6), 3)
factor(c(1,2,3,2,2,3))在Pandas中,这是通过 pd.cut 和 astype("category") 完成的。
pd.cut(pd.Series([1, 2, 3, 4, 5, 6]), 3)
pd.Series([1, 2, 3, 2, 2, 3]).astype("category")结果如下:


往
期
回
顾
技术
资讯
技术
资讯

分享

点收藏

点点赞

点在看
以上是关于第3次翻译了 Pandas 官方文档,叒写了这一份R万字肝货操作!的主要内容,如果未能解决你的问题,请参考以下文章
pandas.DataFrame.describe 官方文档翻译percentile_width,percentiles,include, exclude
熬夜肝了这一份来自牛客,LeetCode,剑指 Offer大佬整理的前端常用算法面试题.pdf,你也能进大厂
熬夜肝了这一份来自牛客,LeetCode,剑指 Offer大佬整理的前端常用算法面试题.pdf,你也能进大厂