Spring中依赖注入DI
Posted 踩踩踩从踩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spring中依赖注入DI相关的知识,希望对你有一定的参考价值。
Spring中Bean实例创建过程_踩踩踩从踩的博客-CSDN博客
前言
前篇文章对bean实例创建 对bean创建得四种方式,以及 创建成功过后做初始化处理调用初始化方法等都有了流程上得理解,本篇文章会继续解析在创建bean实例过程中,属性依赖注入,这个是在我们开发过程中应用到许多的地方。
xml中开启注解方式
这里说一下 在xml中 开启注解的扫描的方式 如何将 annotation-config 注册bean定义的解析器。 如何可以自动扫描的方式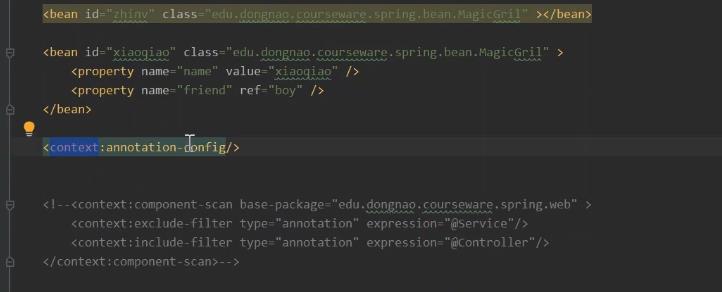
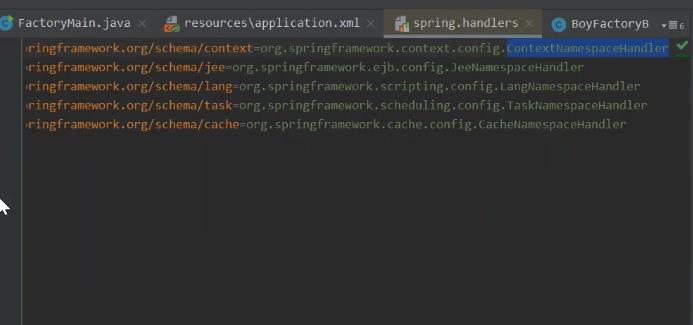
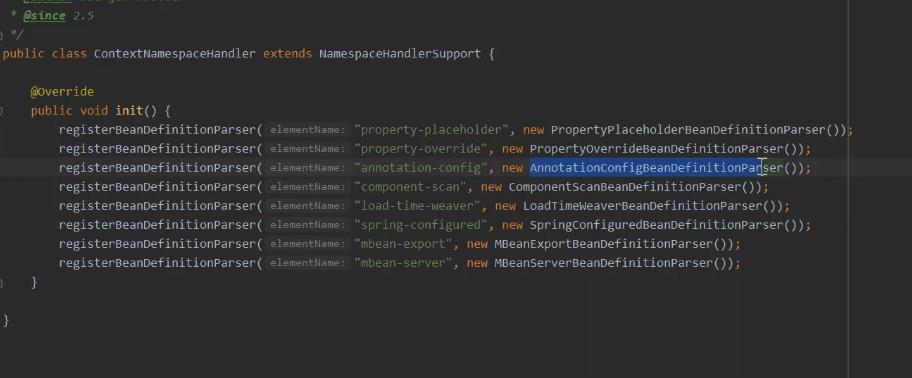
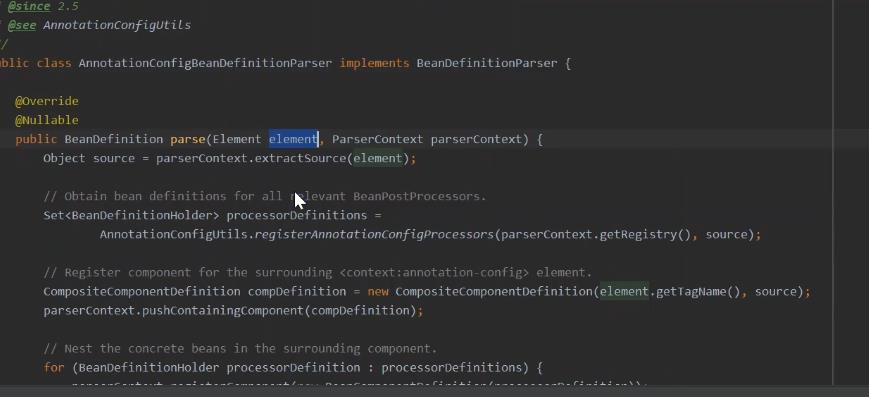
bean定义的解析 这也是 在 xml中去开启 注解扫描器 解析成注解的原因。
包括获取所有的 bean功能增强的。
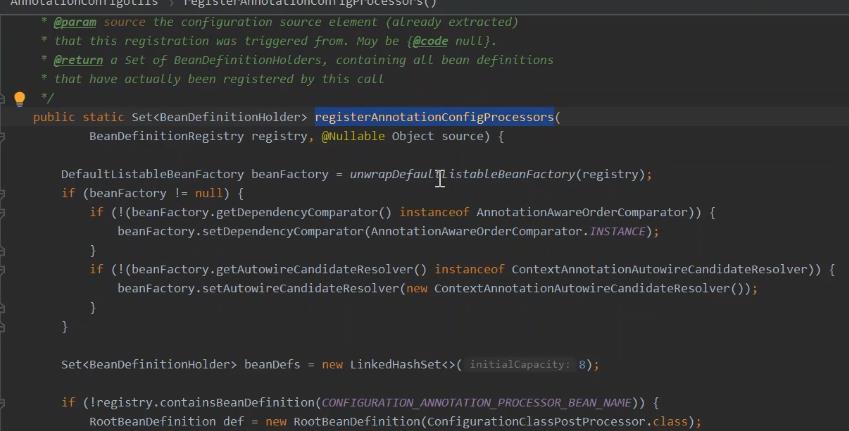
注入各种的注解处理器。作为bean定义都放到 ioc容器中去。
最终将注解的准备工作放到容器中去。
这里深入看一下对于注解解析时,怎么开启bean增强的方式 会将autowired添加进去。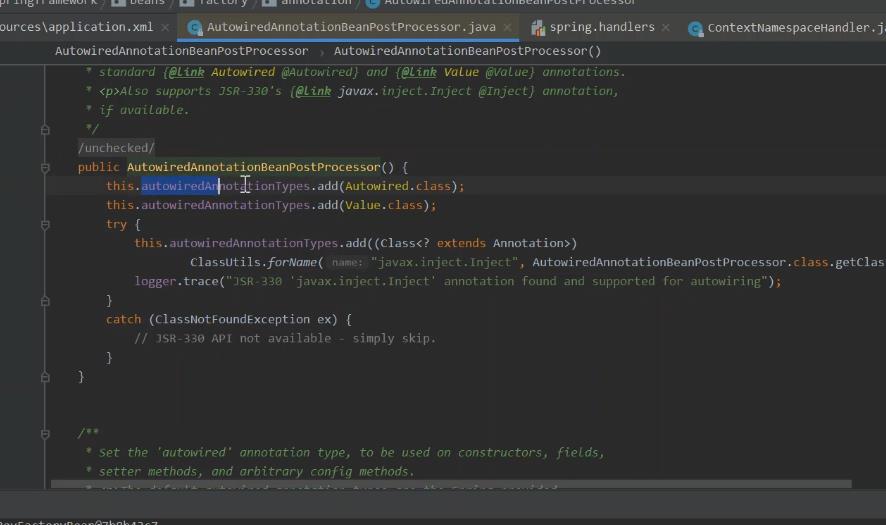
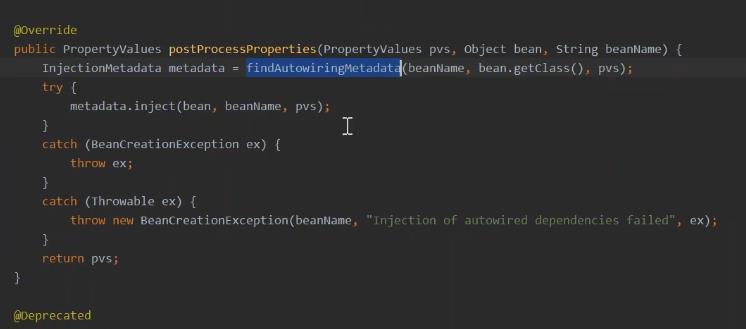
依赖注入
依赖注入的方式:构造函数、属性字段
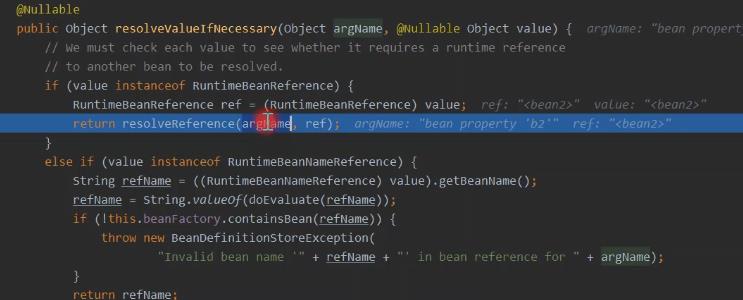
bean 实例创建的时候, AbstractAutowireCapableBeanFactory.createBeanInstance 流程中,的 构造函数方式创建实例,匹配构造的方法中。 具体在 ConstructorResolver.autowireConstructor 方法里进行了依赖注入的逻辑实现。 ConstructorResolver#resolveConstructorArguments 解析构造参数值 BeanDefinitionValueResolver#resolveValueIfNecessary 解析值的关键地方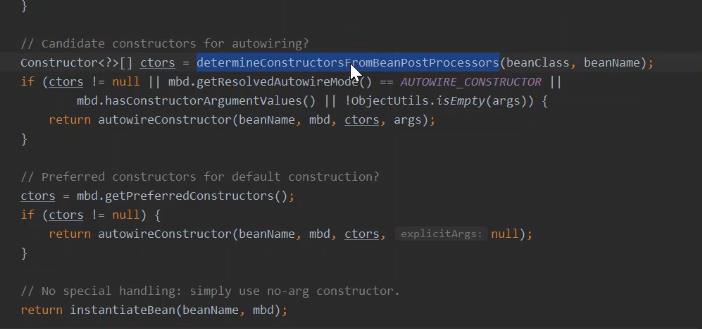
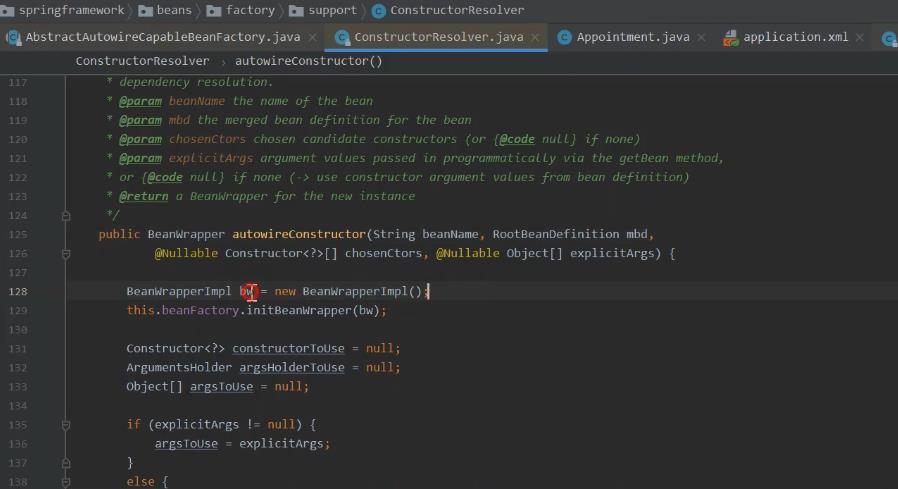 往下面走 解析准备参数的。
往下面走 解析准备参数的。
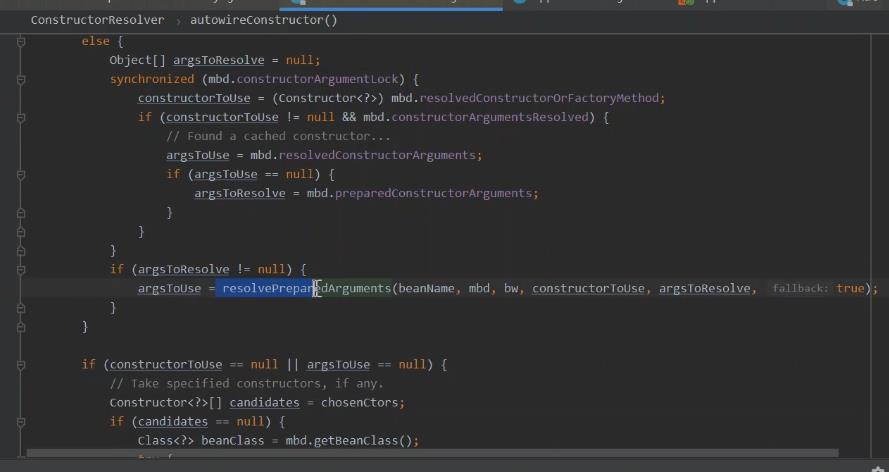
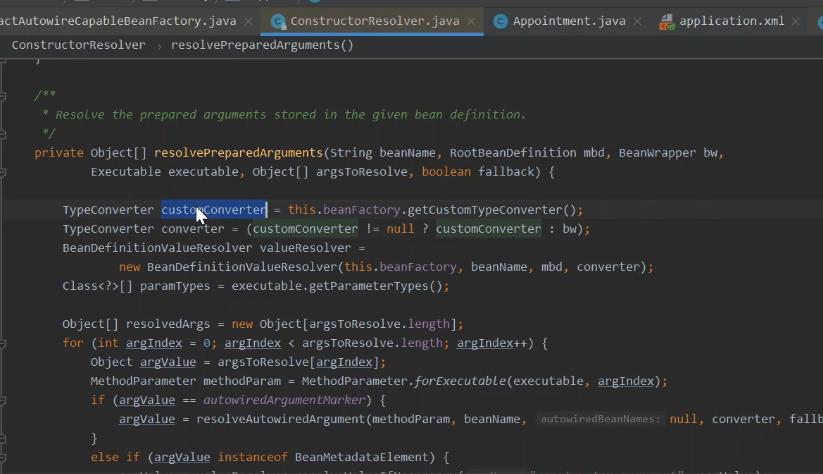
参数索引的处理,判断 string的参数方式,bean定义 dataelement 对于不同类型的解析。

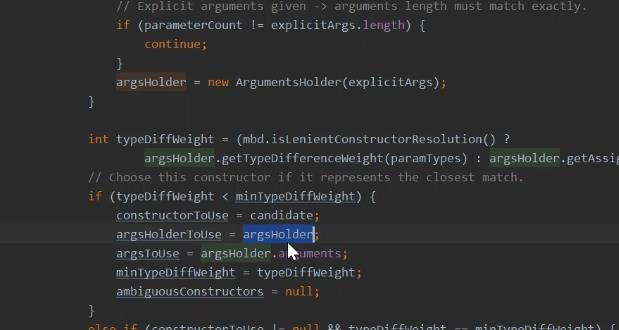
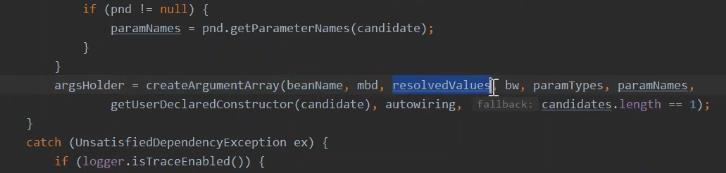
被解析完 的value值,
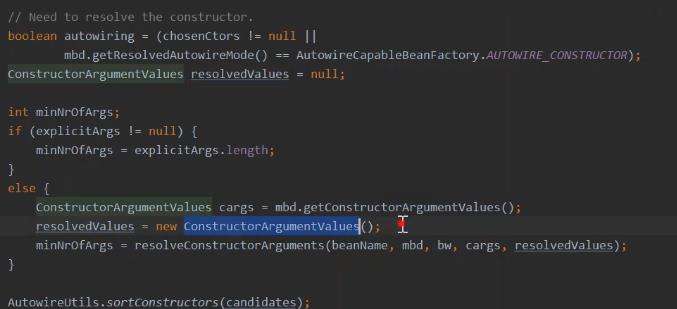
构造函数,中 根据调用栈的方式,分析判断到底是那里赋值的。

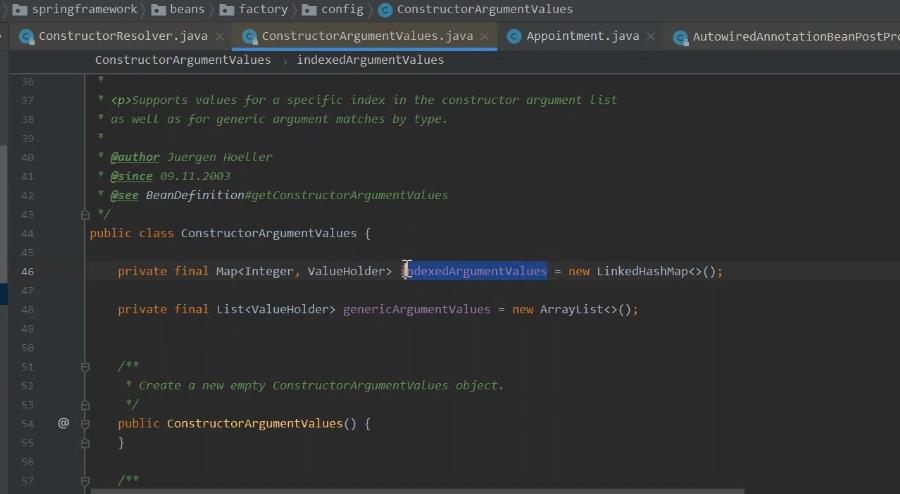
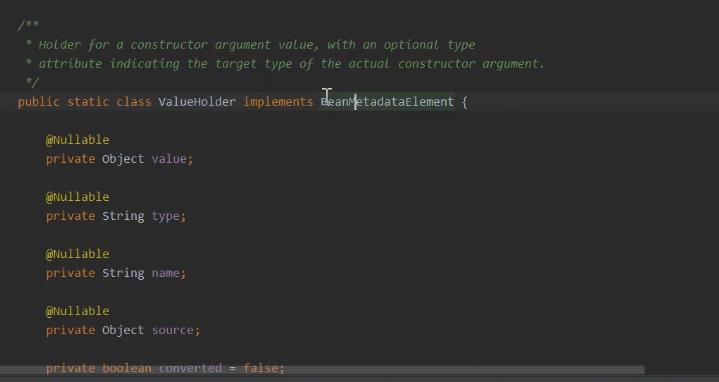
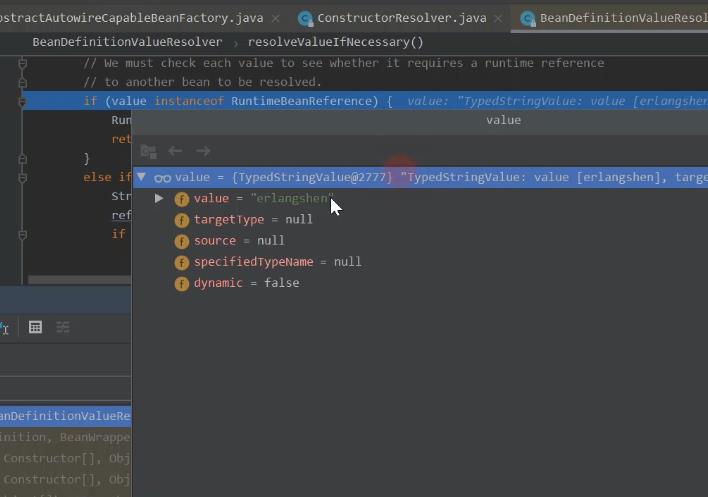
这里可以看一下propertyvalue 转换值。
执行具体的注入方法。
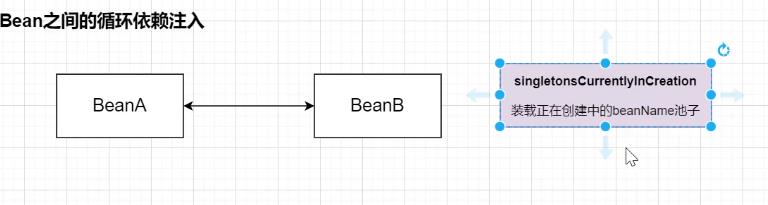
针对多个相同类型的 bean,@Primary 、 @Qualifier 的使用。 配合起来使用 单例 Bean 的循环依赖 Sping 中对象之间的循环依赖存在下面的方式: 1. 构造器注入循环依赖,不成功 2. 属性注入循环依赖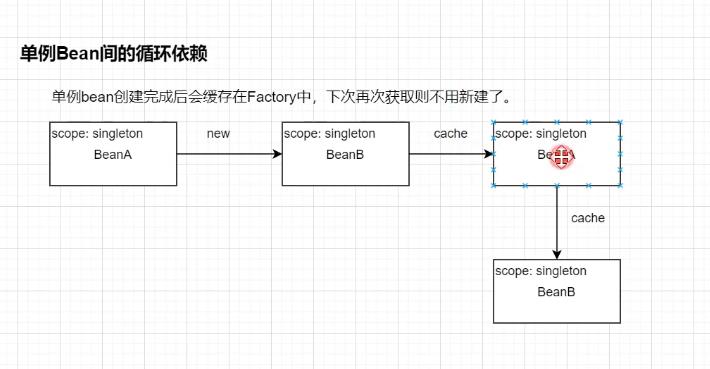
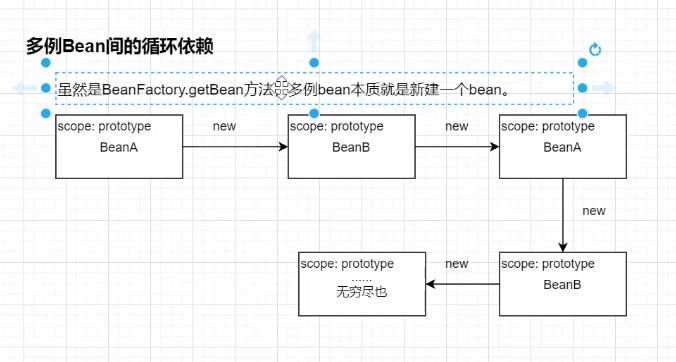
多例bean间的循环依赖
 单例
bean
和原型
bean
有什么区别?
单例
Bean
是缓存在
BeanFactory
中的
原型
Bean是不缓存的
一个单例,一个多例的循环依赖,过程类似,虽然新建动作会多一个,但是会有终点。
可见能不能循环依赖,只要确保一个:
能结束、有终点
源码分析
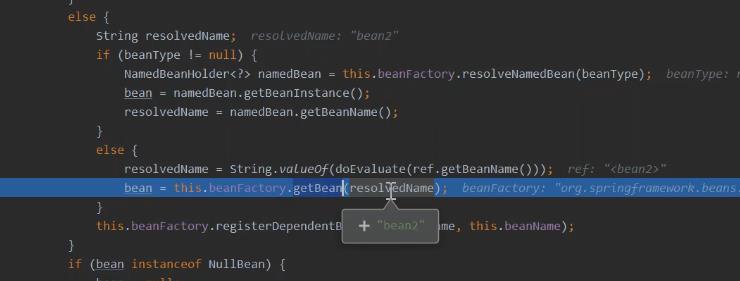
在属性依赖注入中,为满足单例
bean
可循环属性依赖注入,会对单例
Bean
进行提前暴露,从第一次获取bean
时开始,来看一下这个逻辑:
AbstractBeanFactory#getBean(String name)
单例
bean
和原型
bean
有什么区别?
单例
Bean
是缓存在
BeanFactory
中的
原型
Bean是不缓存的
一个单例,一个多例的循环依赖,过程类似,虽然新建动作会多一个,但是会有终点。
可见能不能循环依赖,只要确保一个:
能结束、有终点
源码分析
在属性依赖注入中,为满足单例
bean
可循环属性依赖注入,会对单例
Bean
进行提前暴露,从第一次获取bean
时开始,来看一下这个逻辑:
AbstractBeanFactory#getBean(String name)
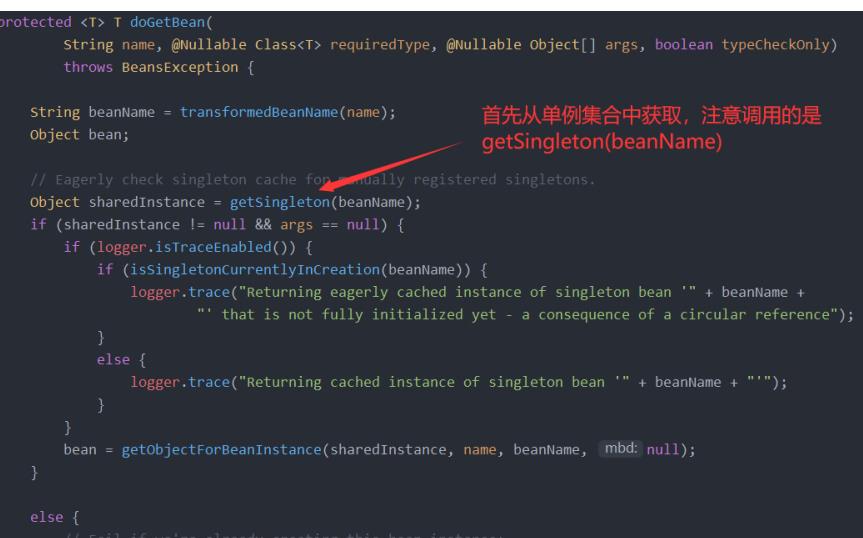
 1.
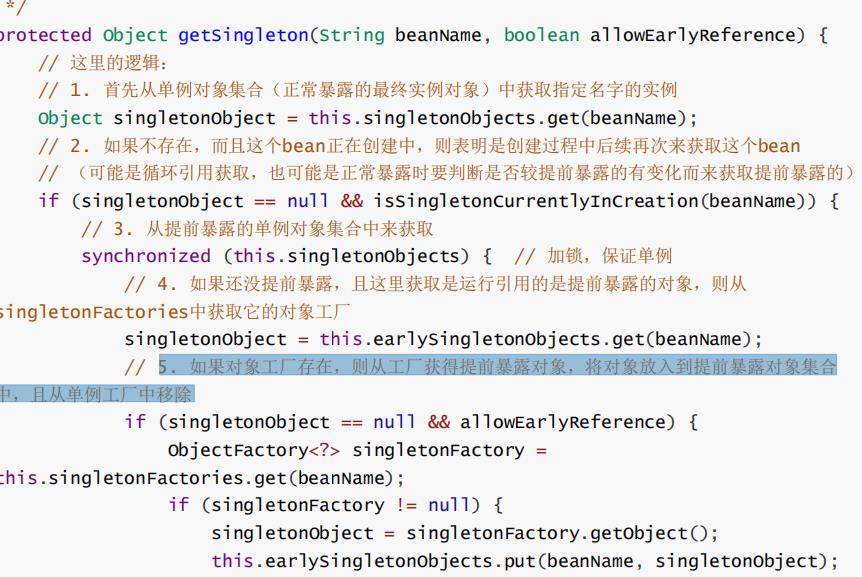
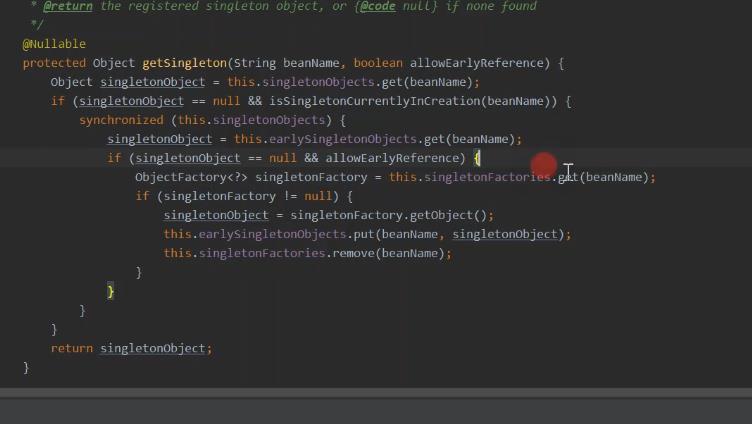
首先从单例对象集合(正常暴露的最终实例对象)中获取指定名字的实例
2.
如果不存在,而且这个
bean
正在创建中,则表明是创建过程中后续再次来获取这个bean(可能是循环引用获取,也可能是正常暴露时要判断是否较提前暴露的有变化而来获取提前暴露的)
3.
从提前暴露的单例对象集合中来获取
4.
如果还没提前暴露,且这里获取是运行引用的是提前暴露的对象,则从 singletonFactories中获取它的对象工厂
5.
如果对象工厂存在,则从工厂获得提前暴露对象,将对象放入到提前暴露对象集合
中,且从单例工厂中移除
1.
首先从单例对象集合(正常暴露的最终实例对象)中获取指定名字的实例
2.
如果不存在,而且这个
bean
正在创建中,则表明是创建过程中后续再次来获取这个bean(可能是循环引用获取,也可能是正常暴露时要判断是否较提前暴露的有变化而来获取提前暴露的)
3.
从提前暴露的单例对象集合中来获取
4.
如果还没提前暴露,且这里获取是运行引用的是提前暴露的对象,则从 singletonFactories中获取它的对象工厂
5.
如果对象工厂存在,则从工厂获得提前暴露对象,将对象放入到提前暴露对象集合
中,且从单例工厂中移除
做了缓存起来。
如果一致(即初始化阶段没有生产新的代理对象),则最终暴露的bean使用提前暴露的bean
如果不一致,则需要判断是否有真的引用对象,有则抛出异常!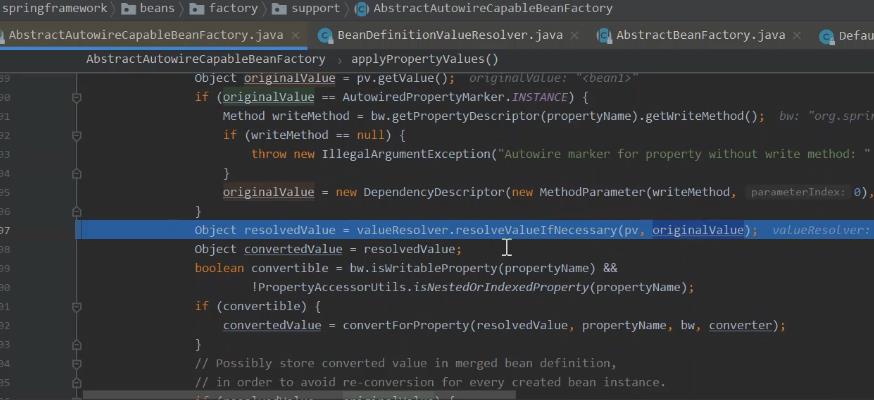
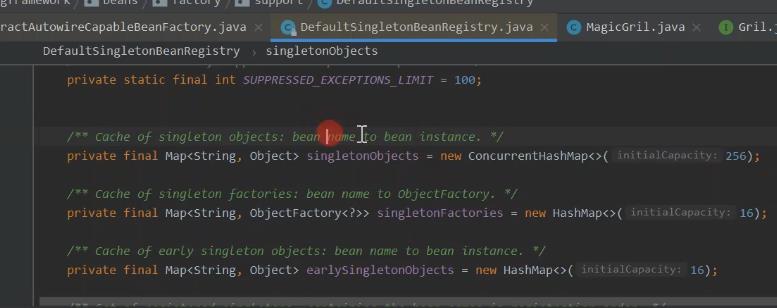
单例缓存起来 用来作为单例bean的方式。
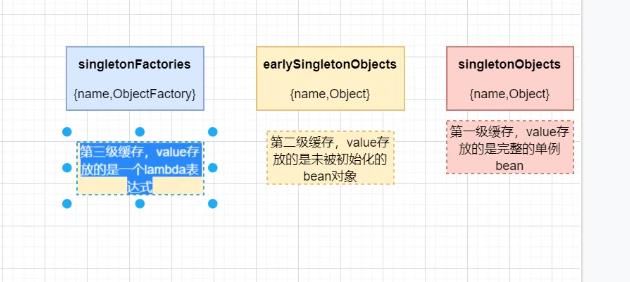
这都是spring来防止循环依赖的情况。 所以在spring中 针对单例bean 防止循环依赖。

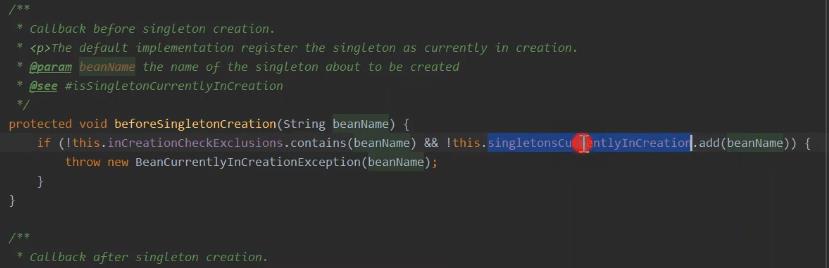
在单例bean中做了两次的获取单例bean,就是防止单例bean未获取到。


添加一级缓存

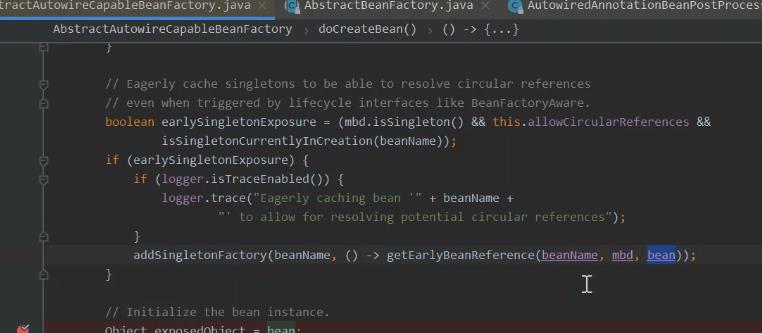
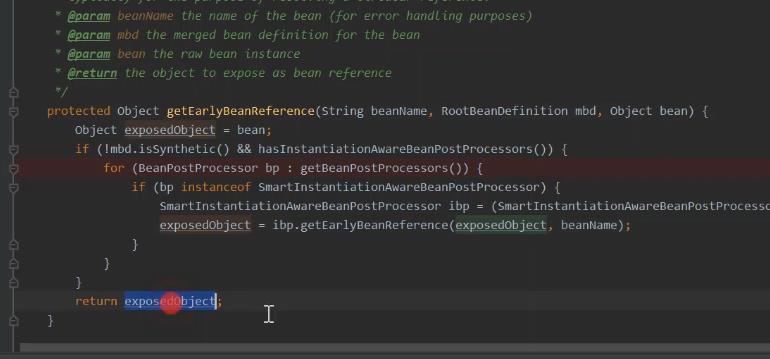
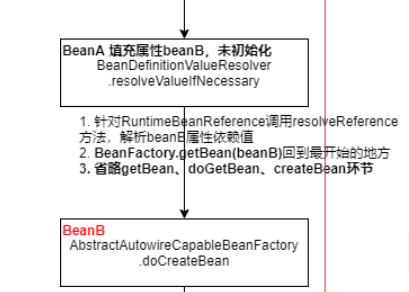
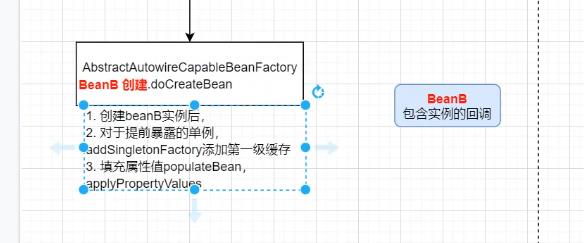
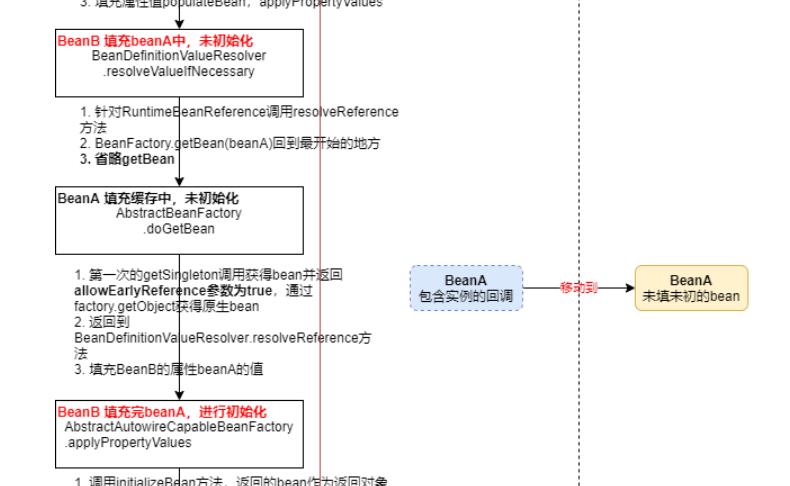
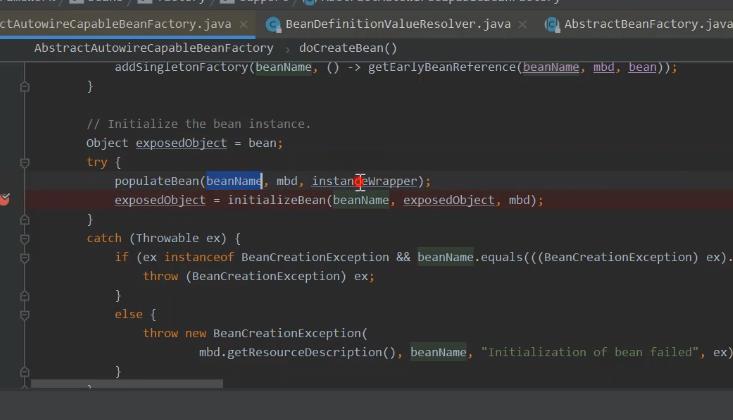
返回到 beana实例化这里。
没有进行初始化的beana填充进去。

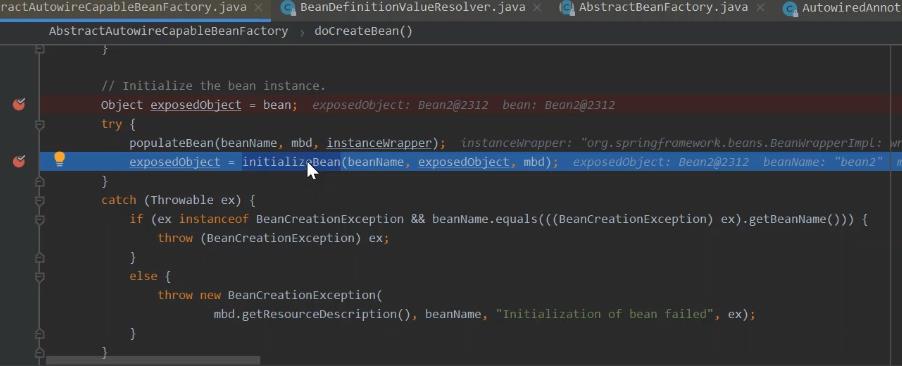
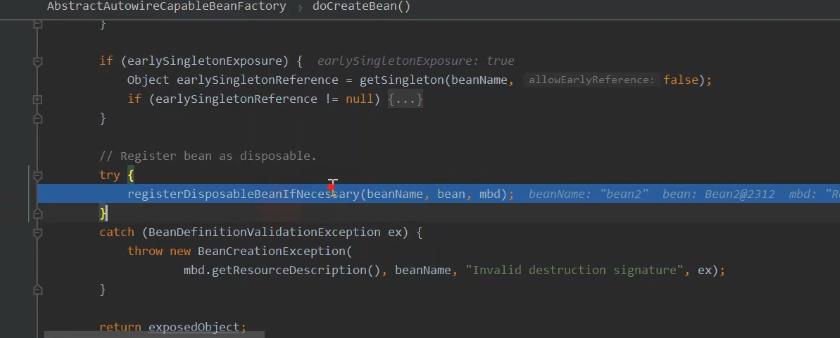

最后对于创建好的对象 进行处理 记录。

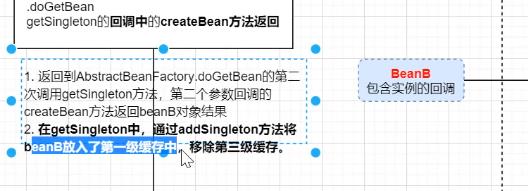
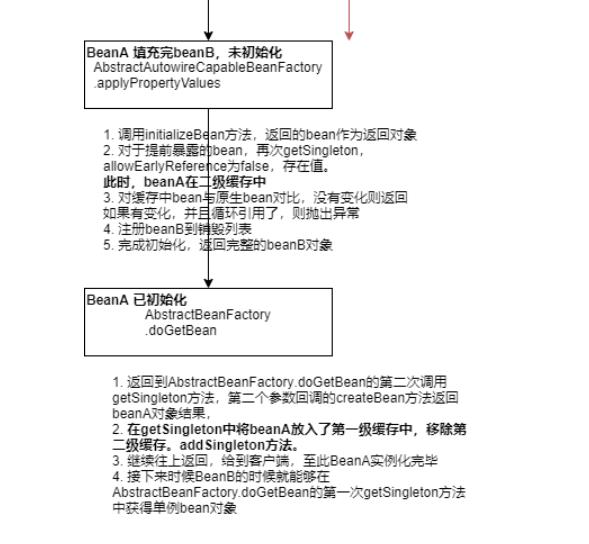
为什么spring要用三级缓存 也是由于 一级缓存 在引用 时,就会出现未初始化好的bean就拿出去用了。
多级缓存 也就是解决循环依赖的。
循环依赖总结一下(假设 A,B 之间循环依赖): 一级缓存 singletonObject ,也就是常说的单例池,是个 Map 二级缓存 earlySingletonObjects ,也就是提前一点的单例池,哈哈,字面翻译 , 也是 Map 三级缓存 singletonFactories ,这个 Map 有点特殊,因为这个 Map 的 value 存放的是一个 lambda 表达式 1 、单例池不能存放原始对象,只能存放经过完整生命周期的对象,也就是 java bean 2 、 A , B 在注入属性都会执行一个 addSingletonFactory 方法,这个方法里面三级缓存就出现了,三级缓存put 了 key 为 beanName , value 为一个 lambda 表达式 3 、其实最容易绕晕的地方是,当 B 注入属性 A 的时候,执行 populateBean 注入一个 bean 的属性的时候会执行getSingleton 这个方法,一定要记得! populateBean 方法体中没有直接调 getSingleton 这个方法,但一定要记得,执行了这个方法 4 、 getSingleton 这个方法,会依次到一级缓存,二级缓存,三级缓存中 get(beanName) ,很显然当 B 注入A 属性的时候,一级,二级里面都没有内容,只有三级有,这时会执行 lambda 表达式, lambda 表达式的作用就是生成代理对象!然后把生成的代理对象存入二级缓存,并返回这个代理对象,B 就会得到这个代理对象A , B 就会认为这个代理对象 A 就是 A 的最后的 bean 对象,因此也就完成了对 A 的属性注入这步操作,接着依次执行B 后续的操作,最后就完成了 B 的生命周期, B 就成功变成了 bean 对象, B 也就完成了使命 5 、当 B 完成使命之后, A 就会继续注入 B ,这时就会注入属性成功了,接下来开始执行 AOP 操作,因为上一步中A 已经生成了代理对象 A ,也就是相当于完成了 AOP ,所以 B 就不执行 AOP 操作了,此时 A 就会执行最后一步操作,将代理对象A 放入到单例池中去,这时 A 就会执行方法 getSingleton ,从二级缓存中获得了代理对象A ,最后将其存入单例池,也就是一级缓存!现在 A 和 B 都放入了单例池,圆满结束。以上是关于Spring中依赖注入DI的主要内容,如果未能解决你的问题,请参考以下文章