go实现高并发高可用分布式系统:设计类似kafka的高并发海量数据存储机制2
Posted tyler_download
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了go实现高并发高可用分布式系统:设计类似kafka的高并发海量数据存储机制2相关的知识,希望对你有一定的参考价值。
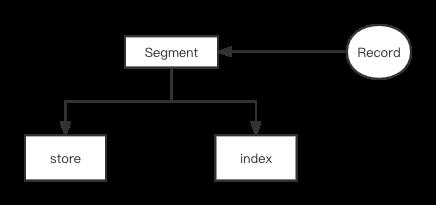
上一节我们完成了数据的存储和索引,本节我们看如何写入数据和进行查询。我们将创建一个Segment对象,它一方面接收发送来的请求,也就是Record数据结构,然后将数据写入到store和index,基本架构如下:
在前面章节中,我们使用代码定义了Record的数据结构,现在我们需要使用protobuf来重新定义它,一来protobuf是常用于微服务架构不同服务间进行数据交互的数据格式,同时它支持跨语言,也就是使用不同编程语言开发的服务都能通过protobuf来实现数据交互,我们现在根目录proglog下面创建目录api/v1,然后在api/v1下创建文件log.proto,其内容如下:
syntax = "proto3";
package log.v1;
option go_package = "api/log_v1";
message Record
bytes value = 1;
uint64 offset = 2;
接着使用protoc对其进行编译:
protoc -I=. --go_out=. *.proto
执行上命令后,会在api/v1下面新建出目录api/log_v1,在目录下多了log_pb.go文件,我们可以使用该文件导出的接口对Record数据结构进行序列化或反序列化,关于Protobuf的内容在网络上非常多,不了解的同学可以搜索一下。要想调用log_pb.go的代码,我们还需要将其模块化,进入api/log_v1,执行命令:
sudo go mod init api/v1/api/log_v1
完成上面命令后,其他模块才能调用log_pb.go的代码。回到目录proglog/internal/log下,创建文件segment.go,
package log
import (
"fmt"
"os"
"path"
api "api/v1/api/log_v1"
"google.golang.org/protobuf/proto"
)
type segment struct
store *store //存储数据的二进制文件
index *index //索引文件
baseOffset, nextOffset uint64 //对应下一个Record的下标
config Config
func newSegment(dir string, baseOffset uint64, c Config) (*segment, error)
//创建两个二进制文件.store和.index,分别用于初始化store和index
s := &segment
baseOffset : baseOffset,
config : c ,
var err error
storeFile, err := os.OpenFile(path.Join(dir, fmt.Sprintf("%d%s", baseOffset, ".store")),
os.O_RDWR | os.O_CREATE | os.O_APPEND, 0644)
if err != nil
return nil, err
if s.store, err = newStore(storeFile); err != nil
return nil, err
indexFile, err := os.OpenFile(path.Join(dir, fmt.Sprintf("%d%s", baseOffset, ".index")),
os.O_RDWR | os.O_CREATE | os.O_APPEND, 0644)
if err != nil
return nil, err
if s.index, err = newIndex(indexFile, c); err != nil
return nil, err
if off, _, err := s.index.Read(-1); err != nil
s.nextOffset = baseOffset
else
s.nextOffset = baseOffset + uint64(off) + 1
return s, nil
func (s *segment) Append(record *api.Record) (offset uint64, err error)
//收到客户端发来的Record二进制数据,将其序列化成Record结构体并存储到store,同时增加其索引在index
cur := s.nextOffset
record.Offset = cur
p, err := proto.Marshal(record) //序列化
if err != nil
return 0, err
_, pos, err := s.store.Append(p)
if err != nil
return 0, err
if err = s.index.Write(uint32(s.nextOffset - uint64(s.baseOffset)), pos); err != nil
return 0, err
s.nextOffset++
return cur, nil
func (s *segment) Read(off uint64) (*api.Record, error)
/*
读取下标为off的记录,每个segment会存储一系列record,例如第一个segment存储下标从0到100的记录
第二个segment存储下标为101到200的记录,当客户端要查询下标为150的记录时,代码会选择第二个segment,
然后计算下标偏移,由于第二个segment对应的记录起始为101,也就是baseOffset=101,于是我们要在第二个segment
查找下标为150-101也就是下标为39的记录
*/
_, pos, err := s.index.Read(int64(off - s.baseOffset))
if err != nil
return nil, err
p, err := s.store.Read(pos)
if err != nil
return nil, err
record := &api.Record
err = proto.Unmarshal(p, record)
return record, err
func (s *segment) IsMaxed() bool
/*
当接收到的记录总量超过了给定范围,这个范围由config.Segment.MaxStoreBytes决定,
或者说索引的数量超过了给定范围,该范围由config.Segment.MaxIndexBytes决定,一旦接收的数据
超过预先指定的范围后,我们就将store和index存储的数据写入到磁盘文件
*/
return s.store.size >= s.config.Segment.MaxStoreBytes || s.index.size >= s.config.Segment.MaxIndexBytes
func (s *segment) Remove() error
//删除segment对应的store和index磁盘文件
if err := s.Close(); err != nil
return err
if err := os.Remove(s.index.Name()); err != nil
return err
if err := os.Remove(s.store.Name()); err != nil
return err
return nil
func (s *segment) Close() error
if err := s.index.Close(); err != nil
return err
if err := s.store.Close(); err != nil
return err
return nil
func nearestMultiple(j, k uint64) uint64
if j >= 0
return (j / k) * k
return ((j - k + 1) * k)
接下来我们测试segment的基本逻辑是否正确,创建文件segment_test.go,输入代码如下:
package log
import(
"io"
"io/ioutil"
"os"
"testing"
"github.com/stretchr/testify/require"
api "api/v1/api/log_v1"
)
func TestSegment(t *testing.T)
dir, _ := ioutil.TempDir("", "segment-test")
defer os.RemoveAll(dir)
want := &api.RecordValue: []byte("hello world")
c := Config
c.Segment.MaxStoreBytes = 1024
c.Segment.MaxIndexBytes = entWidth * 3
s, err := newSegment(dir, 16, c)
require.NoError(t, err)
require.Equal(t, uint64(16), s.nextOffset, s.nextOffset)
require.False(t, s.IsMaxed())
for i := uint64(0); i < 3; i++
off, err := s.Append(want)
require.NoError(t, err)
require.Equal(t, 16 + i, off)
got, err := s.Read(off)
require.NoError(t, err)
require.Equal(t, want.Value, got.Value)
_, err = s.Append(want)
require.Equal(t, io.EOF, err)
require.True(t, s.IsMaxed())
c.Segment.MaxStoreBytes = uint64(len(want.Value) * 3)
c.Segment.MaxIndexBytes = 1023
s, err = newSegment(dir, 16, c)
require.NoError(t, err)
require.True(t, s.IsMaxed())
err = s.Remove()
require.NoError(t, err)
s, err = newSegment(dir, 16, c)
require.NoError(t, err)
require.False(t, s.IsMaxed())
使用GO语言的好处在于,它写出来的代码比较好读,有时候逻辑很难通过平白的语言进行描述,你只能通过读代码来理解作者的意思,同时GO还配备了非常便利的单元测试套件,我们每实现一个逻辑模块后,立马通过创建相关的测试来验证模块的实现是否正确,同时其他人通过读取测试用例就能更好的理解代码逻辑。
前面我们说过,假设日志服务器收到了一亿条数据,我们不可能把所有数据都存储在内存中,因此我们的做法是,当接收到的数据达到一定量时,就要把内存中的数据写入到store文件,同时创建对应的index文件以便索引,因此Segment在接收到数据后,它要判断当前存储在内存的数据是否需要写入到磁盘以便清空内存,那么这里的逻辑我们使用log.go在新的文件里实现,在同一个目录下创建log.go,输入代码如下:
package log
import (
//"fmt"
"io"
"io/ioutil"
"os"
"path"
"sort"
"strconv"
"strings"
"sync"
api "api/v1/api/log_v1"
)
type Log struct
mu sync.RWMutex
Dir string
Config Config
activeSegment *segment //这个segment对应的数据还存储在内存中
segments []*segment //这些segment对应的数据已经写入到磁盘
func NewLog(dir string, c Config) (*Log, error)
/*
当接收到的日志数据大于1024字节,或者索引数据超过了1024字节,那就把内存中的数据写入到磁盘
,这里的写入标准可以根据实际需要进行修改
*/
if c.Segment.MaxStoreBytes == 0
c.Segment.MaxStoreBytes = 1204
if c.Segment.MaxIndexBytes == 0
c.Segment.MaxIndexBytes = 1024
l := &Log
Dir : dir,
Config : c,
return l, l.setup()
func (l *Log) setup() error
//在给定目录下可能已经存储了一系列日志文件,因此我们需要将他们加载起来,如果没有那么我们就创建新的日志文件
files, err := ioutil.ReadDir(l.Dir)
if err != nil
return err
var baseOffsets []uint64
for _, file := range files
offStr := strings.TrimSuffix(file.Name(), path.Ext(file.Name()))
off , _ := strconv.ParseUint(offStr, 10, 0)
baseOffsets = append(baseOffsets, off)
/*
这里的排序很重要,假设当前我们已经接收到了500条日志,如果每100条对应一个segment,于是在磁盘上就要0.stroe,0.index,
1.store, 1.index, 2.store, 2.index, 3.store,3.index; 4.store,4.index.排好序后,如果要查询的日志下标为
250,那么我们可以快速定位到segments[2],然后再从里面查询下标为49的记录
*/
sort.Slice(baseOffsets, func(i, j int) bool
return baseOffsets[i] < baseOffsets[j]
)
for i := 0; i < len(baseOffsets); i++
if err = l.newSegment(baseOffsets[i]); err != nil
return err
//以baseOffset数值为开头的文件有两种一种是.store,一种是.index,排序后两种相同开头的文件会排在一起,
//这里我们只需要他们开头的数值,因此忽略第二个相同开头的文件
i++
if l.segments == nil
if err = l.newSegment(l.Config.Segment.InitialOffset,); err != nil
return err
return nil
func (l *Log) Append(record *api.Record) (uint64, error)
l.mu.Lock()
defer l.mu.Unlock()
//每次日志数据过来时,我们直接将其存储到activeSegment
off, err := l.activeSegment.Append(record)
if err != nil
return 0, err
if l.activeSegment.IsMaxed()
err = l.newSegment(off + 1)
return off, err
func (l *Log) Read(off uint64) (*api.Record, error)
l.mu.RLock()
defer l.mu.RUnlock()
/*
Read用于获取下标为off的日志,由于我们把所有接收到的日志根据下标存储在不同segment中,
同时我们也对segment存储的起始日志进行了排序,因此我们可以根据off快速定位它在哪个segment
*/
var s *segment
for _, segment := range l.segments
if segment.baseOffset <= off && off < segment.nextOffset
s = segment
break
if s == nil || s.nextOffset <= off
return nil, fmt.Errorf("offset out of range: %d", off)
return s.Read(off)
func (l *Log) Close() error
l.mu.Lock()
defer l.mu.Unlock()
for _, segment := range l.segments
if err := segment.Close(); err != nil
return err
return nil
func (l *Log) Remove() error
if err := l.Close(); err != nil
return err
return os.Remove(l.Dir)
func (l *Log) Reset() error
if err := l.Remove(); err != nil
return err
return l.setup()
/*
LowestOffset 和HighestOffset先不要管,他们涉及到服务共识,数据备份等功能
*/
func (l *Log) LowestOffset() (uint64, error)
l.mu.RLock()
defer l.mu.RUnlock()
return l.segments[0].baseOffset, nil
func (l *Log) HighestOffset()(uint64, error)
l.mu.RLock()
defer l.mu.RUnlock()
off := l.segments[len(l.segments) - 1].nextOffset
if off == 0
return 0, nil
return off - 1, nil
func (l *Log) Truncate(lowest uint64) error
l.mu.Lock()
defer l.mu.Unlock()
var segments []*segment
for _, s := range l.segments
if s.nextOffset <= lowest + 1
if err := s.Remove(); err != nil
return err
continue
segments = append(segments, s)
l.segments = segments
return nil
func (l *Log) Reader() io.Reader
l.mu.RLock()
defer l.mu.RUnlock()
readers := make([]io.Reader, len(l.segments))
for i, segment := range l.segments
readers[i] = &originReadersegment.store, 0
return io.MultiReader(readers...)
type originReader struct
*store
off int64
func (o *originReader) Read(p []byte) (int , error )
n, err := o.ReadAt(p, o.off)
o.off += int64(n)
return n, err
func (l *Log) newSegment(off uint64) error
s, err := newSegment(l.Dir, off, l.Config)
if err != nil
return err
l.segments = append(l.segments, s)
l.activeSegment = s
return nil
log.go的代码逻辑其实很简单,它的基本功能就是接收到Record数据,将它加入内存,然后判断当前Segment是否达到了写入磁盘的标准,如果达到就将当前Segment的数据写入磁盘文件。同时它还接收读取请求,根据读请求发来的日志下标,它快速在多个semgent对象中进行定位,由此缩小查找范围,然后在选中的Segment里面查询所需要的Record结构。通过它对应的单元测试,我们能更清楚它的实现逻辑,创建log_test.go:
package log
import (
"io/ioutil"
"os"
"testing"
"github.com/stretchr/testify/require"
api "api/v1/api/log_v1"
"google.golang.org/protobuf/proto"
)
func TestLog(t *testing.T)
for scenario, fn := range map[string]func(t *testing.T, log *Log)
"append and read a record succeeds" : testAppendRead,
"offset out of range error" : testOutOfRangeErr,
"init with of range error" : testInitExisting,
"reader" : testReader,
"truncate" : testTruncate,
t.Run(scenario, func(t *testing.T)
dir, err := ioutil.TempDir("", "store-test")
require.NoError(t, err)
defer os.RemoveAll(dir)
c := Config
c.Segment.MaxStoreBytes = 32
log, err := NewLog(dir, c)
require.NoError(t, err)
fn(t, log)
)
func testAppendRead(t *testing.T, log *Log)
append := &api.Record
Value: []byte("first log"),
off , err := log.Append(append)
require.NoError(t, err)
require.Equal(t, uint64(0), off)
read, err := log.Read(off)
require.NoError(t, err)
require.Equal(t, append.Value, read.Value)
func testOutOfRangeErr(t *testing.T, log *Log)
read, err := log.Read(1)
require.Nil(t, read)
//require.Error(t, err)
apiErr := err.(api.ErrOffsetOutOfRange)
require.Equal(t, uint64(1), apiErr.Offset)
func testInitExisting(t *testing.T, o *Log)
append := &api.Record
Value: []byte("hello world"),
for i := 0; i < 3; i++
_, err := o.Append(append)
require.NoError(t, err)
require.NoError(t, o.Close())
off, err := o.LowestOffset()
require.NoError(t, err)
require.Equal(t, uint64(0), off)
off, err = o.HighestOffset()
require.NoError(t, err)
require.Equal(t, uint64(2), off)
n, err := NewLog(o.Dir, o.Config)
require.NoError(t, err)
off, err = n.LowestOffset()
require.NoError(t, err)
require.Equal(t , uint64(0), off)
off, err = n.HighestOffset()
require.NoError(t, err)
require.Equal(t, uint64(2), off)
func testReader(t *testing.T, log *Log)
append := &api.Record
Value : []byte("first log"),
off , err := log.Append(append)
require.NoError(t, err)
require.Equal(t, uint64(0), off)
reader := log.Reader()
b, err := ioutil.ReadAll(reader)
require.NoError(t, err)
read := &api.Record
err = proto.Unmarshal(b[lenWidth:], read)
require.NoError(t, err)
require.Equal(t, append.Value, read.Value)
func testTruncate(t *testing.T, log *Log)
append := &api.Record
Value: []byte("hello world"),
for i := 0; i < 3; i++
_, err := log.Append(append)
require.NoError(t, err)
err := log.Truncate(1)
require.NoError(t, err)
_, err = log.Read(0)
require.Error(t, err)
我们这里实现的数据存储系统在逻辑上其实很简单,我们也没有涉及到什么复杂的算法或数据结构,然而工业级的消息队列kafaka,它的日志数据存储系统差不多也是这个原理,所以虽然原理简单,但却相当实用,下一节我们进入gRPC原理的研究,看看在微服务架构下,各个服务是如何相互交互的。
代码在这里下载
https://github.com/wycl16514/go_distribute_system_store_index.git
以上是关于go实现高并发高可用分布式系统:设计类似kafka的高并发海量数据存储机制2的主要内容,如果未能解决你的问题,请参考以下文章
GO实现高可用高并发分布式系统:使用gRPC实现一对多和多对多交互
GO实现高可用高并发分布式系统:gRPC实现客户端与服务端的一对一通讯
马哥高端Go语言百万并发高薪班微服务分布式高可用Go高并发(低价网盘分享)