图像处理---Pytorch中模块化的代码整理(持续更新中......)
Posted 鼠标滑轮不会动
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图像处理---Pytorch中模块化的代码整理(持续更新中......)相关的知识,希望对你有一定的参考价值。
🙋♂️写在最前面的
- 🥳博客主页:😋 鼠标滑轮不会动 😋
- 🏅欢迎 关注🎯 点赞👍 收藏⭐️ 留言📋
- 🎬首发时间:🎉2022年1月15日🎉
- 🆕最新更新时间:🎉2022年1月15日🎉
- 🌟本文由 鼠标滑轮不会动 原创,CSDN首发!
- 📬不积跬步无以至千里!
- 📌本人水平非常有限,如有错误,请留言捶我小脑袋,万分感谢感谢感谢!
-
热门文章目录
-
☑️跑通代码—2020-CVPR–StegaStamp: Invisible Hyperlinks in Physical Photographs
-
☑️跑通代码—2020-WACV-Dense Extreme Inception Network: Towards a Robust CNN Model for Edge Detection
-
☑️跑通代码—2021-ICCV-HiNet: Deep Image Hiding by Invertible Network
-
☑️代码复现—2021-IEEE-TETCI-A Generalized Deep Neural Network Approach for Digital Watermarking Analysis
-
☑️跑通代码—2018-CVPR—D-LinkNet: DeepGlobe-Road-Extraction-Challenge

目录
✨代码整理初衷
在复现算法和看大佬们写的代码过程中发现,很多代码都很模块化,需要修改的地方无非是模型部分和一些前处理或者后处理的部分,其他构建数据集,设置参数都是很模块化的代码,根本不需要花费太多的时间,所以,想着可以将自己认为比较模块化的代码整理出来,方便自己今后写代码直接查找和使用。需要对应部分代码的可以复制部分,也可以在最后将所有的代码一起复制。🤩
✨基础设置
🌿必要的包
import os
import torch
import time # 时间相关的包,训练中计时
import numpy as np # 数值计算
from glob import glob # 获取相匹配的路径下文件,读取数据时使用
from PIL import Image, ImageOps # 强大的图像处理包
from torch.utils.data import Dataset, DataLoader # 批量导入图像数据使用
from torch.utils.tensorboard import SummaryWriter # 训练过程中数据监视器
from torchvision import transforms # 对图像数据进行预处理变换
import cv2 # 强大的图像处理包
import random # 产生随机数
🌿基础检查与设置
🎄训练设备的检测与选择
device = torch.device('cpu' if torch.cuda.device_count() == 0 else 'cuda')
🎄参数的设置
🔶方法1️⃣:直接使用 parser = argparse.ArgumentParser(), 使用 parser.add_argument() 增加设置,使用 args.batch_size 来调用
def parse_args():
parser = argparse.ArgumentParser(description='DexiNed trainer.')
parser.add_argument('--batch_size',type=int, default=8, help=''the mini-batch size (default: 8)'')
parser.add_argument('--choose_test_data', type=int, default=0, help='Already set the dataset for testing choice: 0 - 8')
parser.add_argument('--input_dir',type=str, default="dataset/BIPED", help='the path to the directory with the input data.')
parser.add_argument('--log_path',type=str, default="logs/test0115", help='the path to the directory with the input data.')
args = parser.parse_args()
return args
🔶方法2️⃣:在.yaml文件单独存放参数设置变量,使用 args.lr 来调用
with open('setting.yaml', 'r') as f:
args = EasyDict(yaml.load(f, Loader=yaml.SafeLoader))
# setting.yaml文件中的设置如下,使用变量+:+参数的设置方法
cuda: True
exp_name: test0115
num_steps: 14000
batch_size: 16
lr: 0.0001
train_path: 'D:\\data\\mirflickr'
logs_path: "./logs/"
checkpoints_path: './checkpoints/'
saved_models: './saved_models'
# train函数中调用直接使用如下命令 args.lr
optimize_secret_loss = optim.Adam(g_vars, lr=args.lr)
🎄路径的检查与创建
🔶检查路径,如果不存在创建路径; 拼接路径
# 检查路径,如果不存在创建路径
if not os.path.exists(args.checkpoints_path):
os.makedirs(args.checkpoints_path)
# 拼接路径
checkpoints_path = os.path.join(args.checkpoints_path, str(args.exp_name))
#创建路径
os.makedirs(checkpoints_path, exist_ok=True)
✨数据集的制作和导入
🎄单类图像数据集导入
class MakeData(Dataset):
def __init__(self, data_path, size=(400, 400)):
self.data_path = data_path
self.size = size
# .jpg根据自己的数据集进行替换,例如.png
self.files_list = glob(os.path.join(self.data_path, '*.jpg'))
self.to_tensor = transforms.ToTensor()
def __getitem__(self, idx):
img_cover_path = self.files_list[idx]
# 读取图像并转化成RGB格式
img_cover = Image.open(img_cover_path).convert('RGB')
# ImageOps.fit用于获得制定裁剪尺寸的图像
img_cover = ImageOps.fit(img_cover, self.size)
img_cover = self.to_tensor(img_cover)
return img_cover
def __len__(self):
return len(self.files_list)
# train函数中使用如下命令调用
dataset = MakeData(args.train_path, size=(400, 400))
dataloader = DataLoader(dataset, batch_size=args.batch_size, shuffle=True, pin_memory=True)
🎄带有groundtruth的数据集导入
🔶以边缘提取的数据集Biped为例,数据集分为原始图像和边缘的ground truth图像
class BipedDataset(Dataset):
def __init__(self,
data_root,
img_height,
img_width,
mean_bgr,
train_mode='train',
dataset_type='rgbr',
crop_img=False,
arg=None
):
self.data_root = data_root
self.train_mode = train_mode
self.dataset_type = dataset_type
self.data_type = 'real' # be aware that this might change in the future
self.img_height = img_height
self.img_width = img_width
self.mean_bgr = mean_bgr
self.crop_img = crop_img
self.arg = arg
self.data_index = self._build_index()
def _build_index(self):
# os.path.abspath取指定文件或目录的绝对路径(完整路径)
data_root = os.path.abspath(self.data_root)
sample_indices = []
images_path = os.path.join(data_root, 'imgs', self.train_mode, self.dataset_type)
labels_path = os.path.join(data_root, 'edge_maps', self.train_mode, self.dataset_type)
for directory_name in os.listdir(images_path):
image_directories = os.path.join(images_path, directory_name)
for file_name_ext in os.listdir(image_directories):
file_name = os.path.splitext(file_name_ext)[0]
sample_indices.append(
(os.path.join(images_path, directory_name, file_name + '.jpg'),
os.path.join(labels_path, directory_name, file_name + '.png'),)
) # 这里的.jpg和.png是根据自己数据集更换的
return sample_indices
def __len__(self):
return len(self.data_index)
def __getitem__(self, idx):
# get data sample
image_path, label_path = self.data_index[idx]
# 读取图像数据
image = cv2.imread(image_path, cv2.IMREAD_COLOR)
label = cv2.imread(label_path, cv2.IMREAD_GRAYSCALE)
image, label = self.transform(img=image, gt=label)
return dict(images=image, labels=label)
def transform(self, img, gt):
gt = np.array(gt, dtype=np.float32)
if len(gt.shape) == 3:
gt = gt[:, :, 0]
gt /= 255. # 归一化
img = np.array(img, dtype=np.float32)
img -= self.mean_bgr # 取均值处理
i_h, i_w,_ = img.shape
# 设置随机剪裁的尺寸为400
crop_size = self.img_height if self.img_height == self.img_width else 400#
# # for BIPED
if np.random.random() > 0.5:
h,w = gt.shape
LR_img_size = 256
i = random.randint(0, h - LR_img_size)
j = random.randint(0, w - LR_img_size)
# if img.
img = img[i:i + LR_img_size , j:j + LR_img_size ]
gt = gt[i:i + LR_img_size , j:j + LR_img_size ]
img = cv2.resize(img, dsize=(crop_size, crop_size),)
gt = cv2.resize(gt, dsize=(crop_size, crop_size))
else:
# 如果不随机剪裁就重置图像尺寸
img = cv2.resize(img, dsize=(crop_size, crop_size))
gt = cv2.resize(gt, dsize=(crop_size, crop_size))
# 对图像进行变换,由原来的 H W C-> C H W
img = img.transpose((2, 0, 1))
img = torch.from_numpy(img.copy()).float() # 转成tensor
gt = torch.from_numpy(np.array([gt])).float()
return img, gt
✨训练过程数据和图像的及时反馈
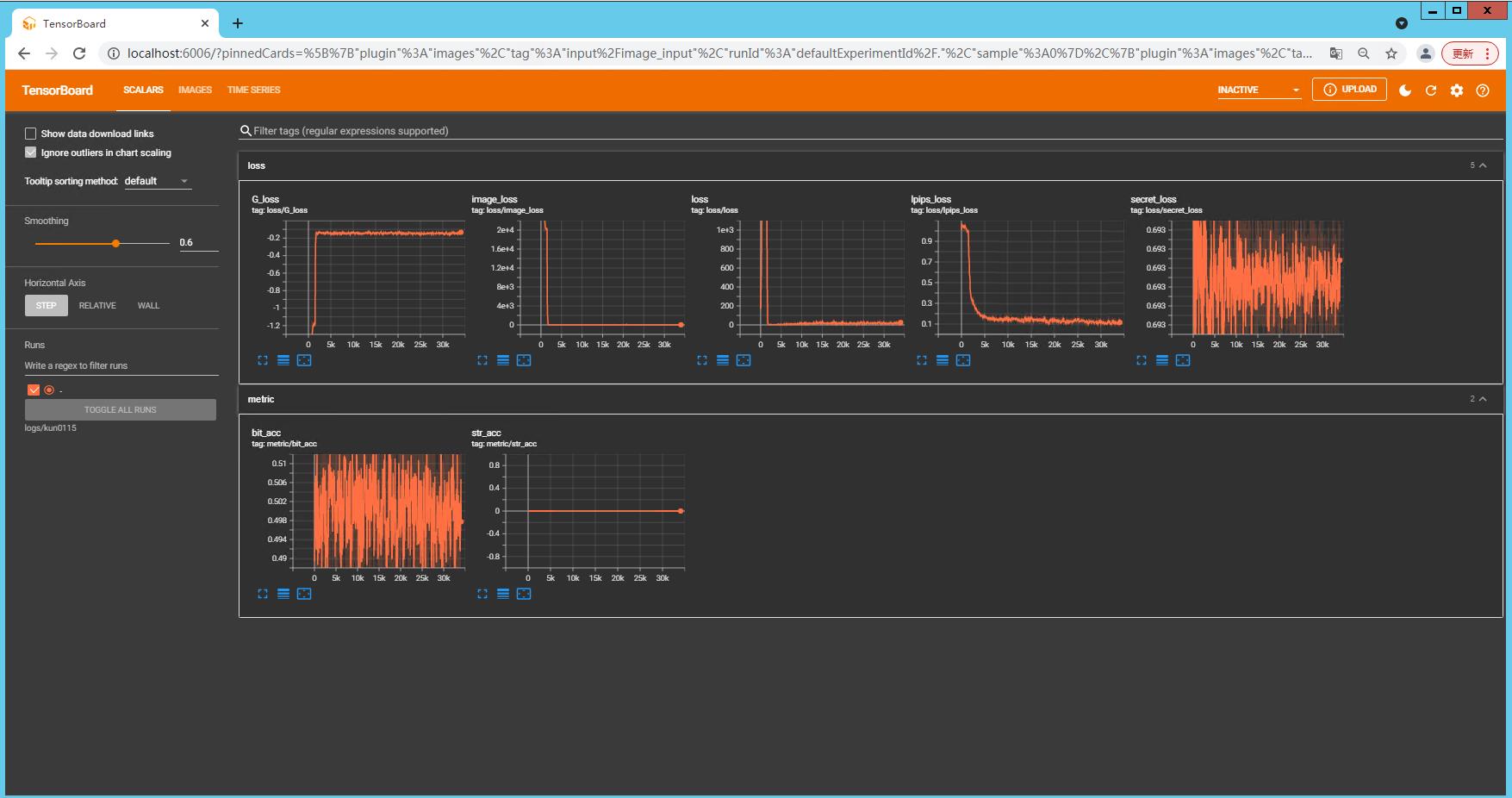
🔶使用tensorborad对训练中的数据和图像进行展示
# 设置路径保存数据和图像
writer = SummaryWriter(args.log_path)
# 增加要展示的数据,其中 loss/image_loss中的loss代表分组,image_loss是对应数据的名称,global_step为全局的步数,告诉writer什么时候展示
writer.add_scalar('loss/image_loss', image_loss, global_step)
writer.add_scalar('loss/secret_loss', secret_loss, global_step)
# 增加不同的分组,设置metric的分组
writer.add_scalar('metric/bit_acc', bit_acc, global_step)
writer.add_scalar('metric/str_acc', str_acc, global_step)
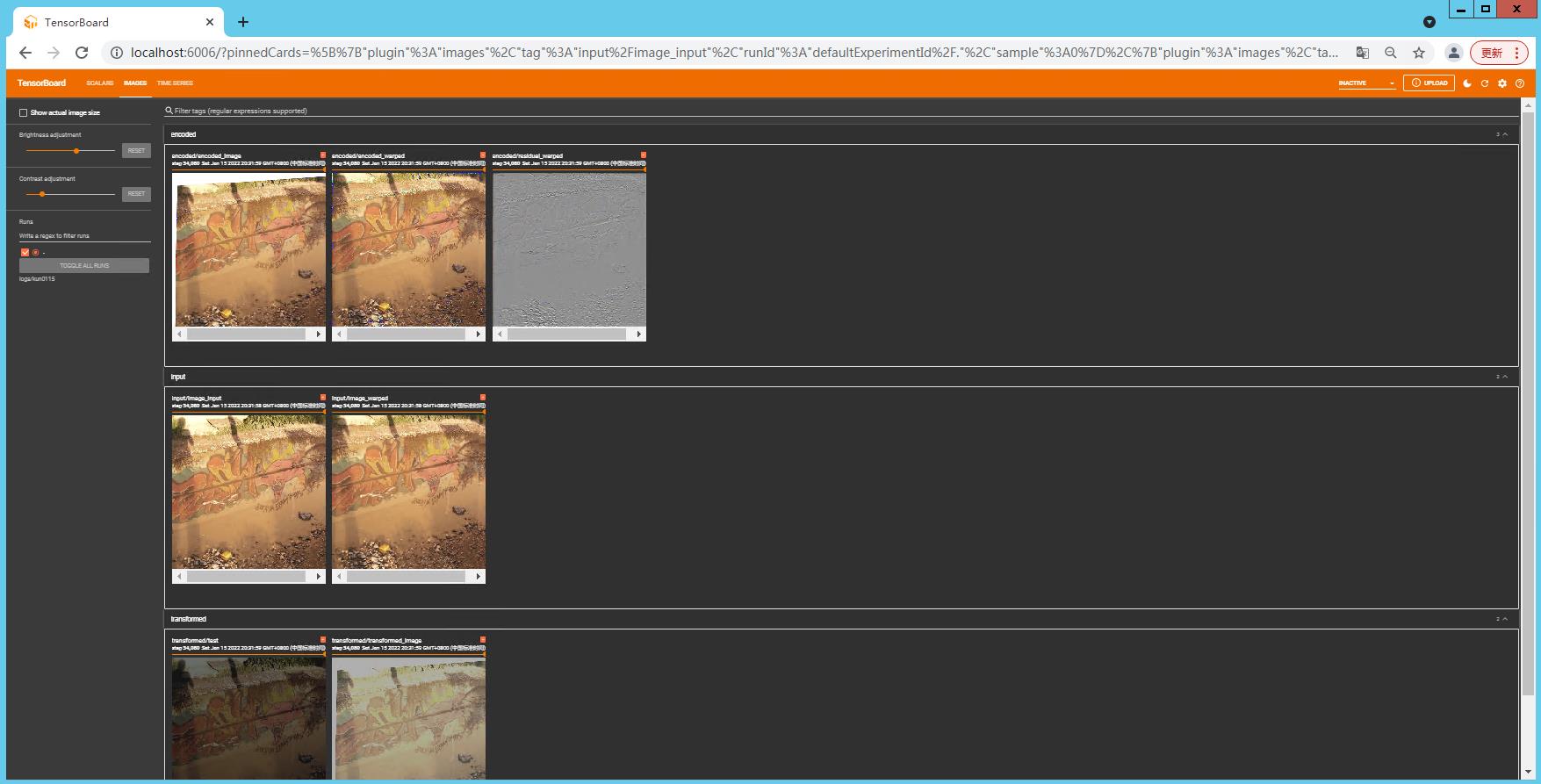
# 增加图像的展示,设置了三个分组,input,encoded和transformed
writer.add_image('input/image_input', image_input[0], global_step)
writer.add_image('input/image_warped', input_warped[0], global_step)
writer.add_image('encoded/encoded_warped', encoded_warped[0], global_step)
writer.add_image('encoded/residual_warped', residual_warped[0] + 0.5, global_step)
writer.add_image('encoded/encoded_image', encoded_image[0], global_step)
writer.add_image('transformed/transformed_image', transformed_image[0], global_step)
writer.add_image('transformed/test', test_transform[0], global_step)
# 在global_step训练完成之后关闭writer
writer.close()
# 训练过程中在terminal中输入对应的路径,查看过程中的结果,其中tensorboard --logdir不变,只需要输入保存的log_path即可。如果想退出 CTRL+C
PS D:\\StegaStamp_pytorch_original> tensorboard --logdir logs/test0115
在terminal中输入tensorboard --logdir logs/test0115之后,点击出现的本地链接 http://localhost:6006/ ,会弹出tensorborad的监视网页,能实时看到训练的结果
✨所有代码的汇总
# ---------------------------------基础的包导入----------------------------------
import os
import torch
import time # 时间相关的包,训练中计时
import numpy as np # 数值计算
from glob import glob # 获取相匹配的路径下文件,读取数据时使用
from PIL import Image, ImageOps # 强大的图像处理包
from torch.utils.data import Dataset, DataLoader # 批量导入图像数据使用
from torch.utils.tensorboard import SummaryWriter # 训练过程中数据监视器
from torchvision import transforms # 对图像数据进行预处理变换
import cv2 # 强大的图像处理包
import random # 产生随机数
# --------------------------------训练设备的检测与选择--------------------------------
device = torch.device('cpu' if torch.cuda.device_count() == 0 else 'cuda')
# 参数的设置,使用 **parser.add_argument()** 增加设置,使用 **args.batch_size** 来调用
def parse_args():
parser = argparse.ArgumentParser(description='DexiNed trainer.')
parser.add_argument('--batch_size',type=int, default=8, help=''the mini-batch size (default: 8)'')
parser.add_argument('--choose_test_data', type=int, default=0, help='Already set the dataset for testing choice: 0 - 8')
parser.add_argument('--input_dir',type=str, default="dataset/BIPED", help='the path to the directory with the input data.')
args = parser.parse_args()
return args
# --------------------------------路径相关操作--------------------------------
# 检查路径,如果不存在创建路径
if not os.path.exists(args.checkpoints_path):
os.makedirs(args.checkpoints_path)
# 拼接路径
log_path = os.path.join(args.logs_path, str(args.exp_name))
#创建路径
os.makedirs(checkpoints_path, exist_ok=True)
# -------------------------单类数据集的处理---------------------------------
class MakeData(Dataset):
def __init__(self, data_path, size=(400, 400)):
self.data_path = data_path
self.size = size
# .jpg根据自己的数据集进行替换,例如.png
self.files_list = glob(os.path.join(self.data_path, '*.jpg'))
self.to_tensor = transforms.ToTensor()
def __getitem__(self, idx):
img_cover_path = self.files_list[idx]
# 读取图像并转化成RGB格式
img_cover = Image.open(img_cover_path).convert('RGB')
# ImageOps.fit用于获得制定裁剪尺寸的图像
img_cover = ImageOps.fit(img_cover, self.size)
img_cover = self.to_tensor(img_cover)
return img_cover, secret
def __len__(self):
return len(self.files_list)
# train函数中使用如下命令调用
dataset = MakeData(args.train_path, size=(400, 400))
dataloader = DataLoader(dataset, batch_size=args.batch_size, shuffle=True, pin_memory=True)
# -------------------------带有groundtruth的数据集导入---------------------------------
class BipedDataset(Dataset):
def __init__(self,
data_root,
img_height,
img_width,
mean_bgr,
train_mode='train',
dataset_type='rgbr',
crop_img=False,
arg=None
):
self.data_root = data_root
self.train_mode = train_mode
self.dataset_type = dataset_type
self.data_type = 'real' # be aware that this might change in the future
self.img_height = img_height
self.img_width = img_width
self.mean_bgr = mean_bgr
self.crop_img = crop_img
self.arg = arg
self.data_index = self._build_index()
def _build_index(self):
# os.path.abspath取指定文件或目录的绝对路径(完整路径)
data_root = os.path.abspath(self.data_root)
sample_indices = []
images_path = os.path.join(data_root, 'imgs', self.train_mode, self.dataset_type)
labels_path = os.path.join(data_root, 'edge_maps', self.train_mode, self.dataset_type)
for directory_name in os.listdir(images_path):
image_directories = os.path.join(images_path, directory_name)
for file_name_ext in os.listdir(image_directories):
file_name = os.path.splitext(file_name_ext)[0]
sample_indices.append(
(os.path.join(images_path, directory_name, file_name + '.jpg'),
os.path.join(labels_path, directory_name, file_name + '.png'),)
) # 这里的.jpg和.png是根据自己数据集更换的
return sample_indices
def __len__(self):
return len(self.data_index)
以上是关于图像处理---Pytorch中模块化的代码整理(持续更新中......)的主要内容,如果未能解决你的问题,请参考以下文章