Zookeeper--09---Zookeeper集群 ZAB协议
Posted 高高for 循环
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Zookeeper--09---Zookeeper集群 ZAB协议相关的知识,希望对你有一定的参考价值。
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
Zookeeper集群
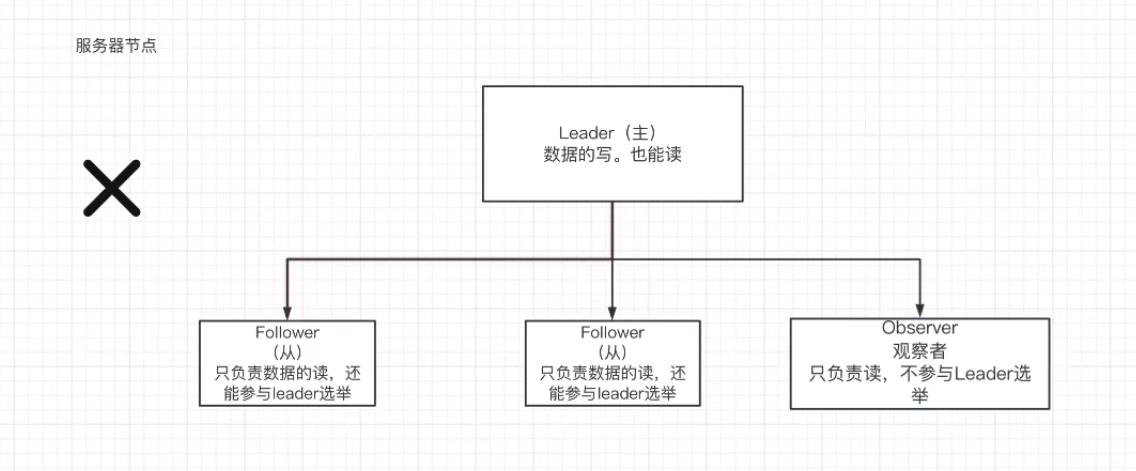
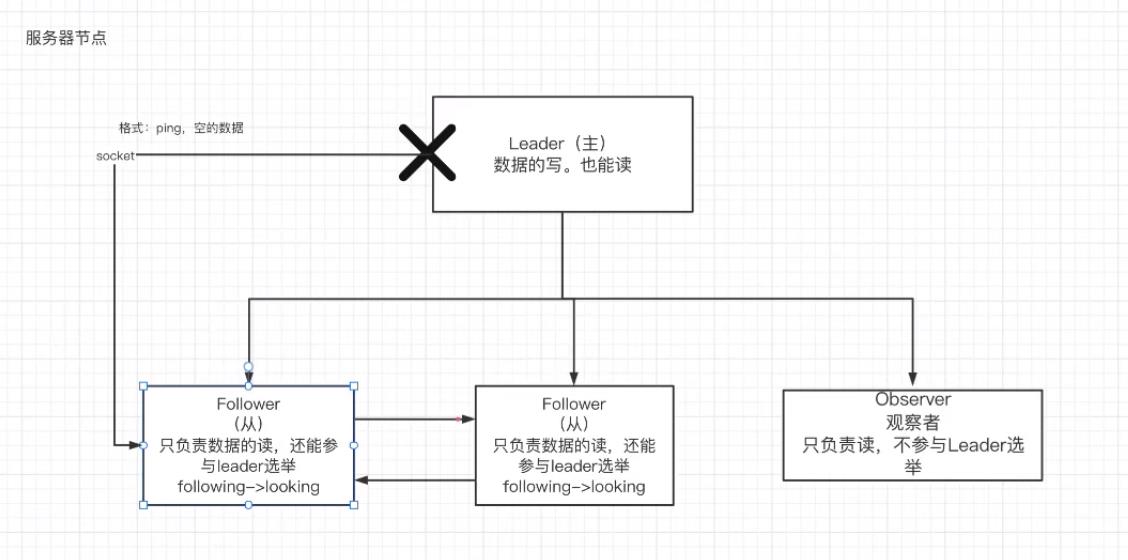
Zookeeper集群⻆⾊
zookeeper集群中的节点有三种⻆⾊
- Leader:处理集群的所有事务请求,集群中只有⼀个Leader。
- Follower:只能处理读请求,参与Leader选举。
- Observer:只能处理读请求,提升集群读的性能,但不能参与Leader选举。
集群搭建
- 搭建4个节点,其中⼀个节点为Observer
1)创建4个节点的myid,并设值

2)编写4个zoo.cfg

3)启动4台Zookeeper
4)连接Zookeeper集群
./bin/zkCli.sh -server
172.16.253.54:2181,172.16.253.54:2182,172.16.253.54:2183
ZAB协议
1.什么是ZAB协议
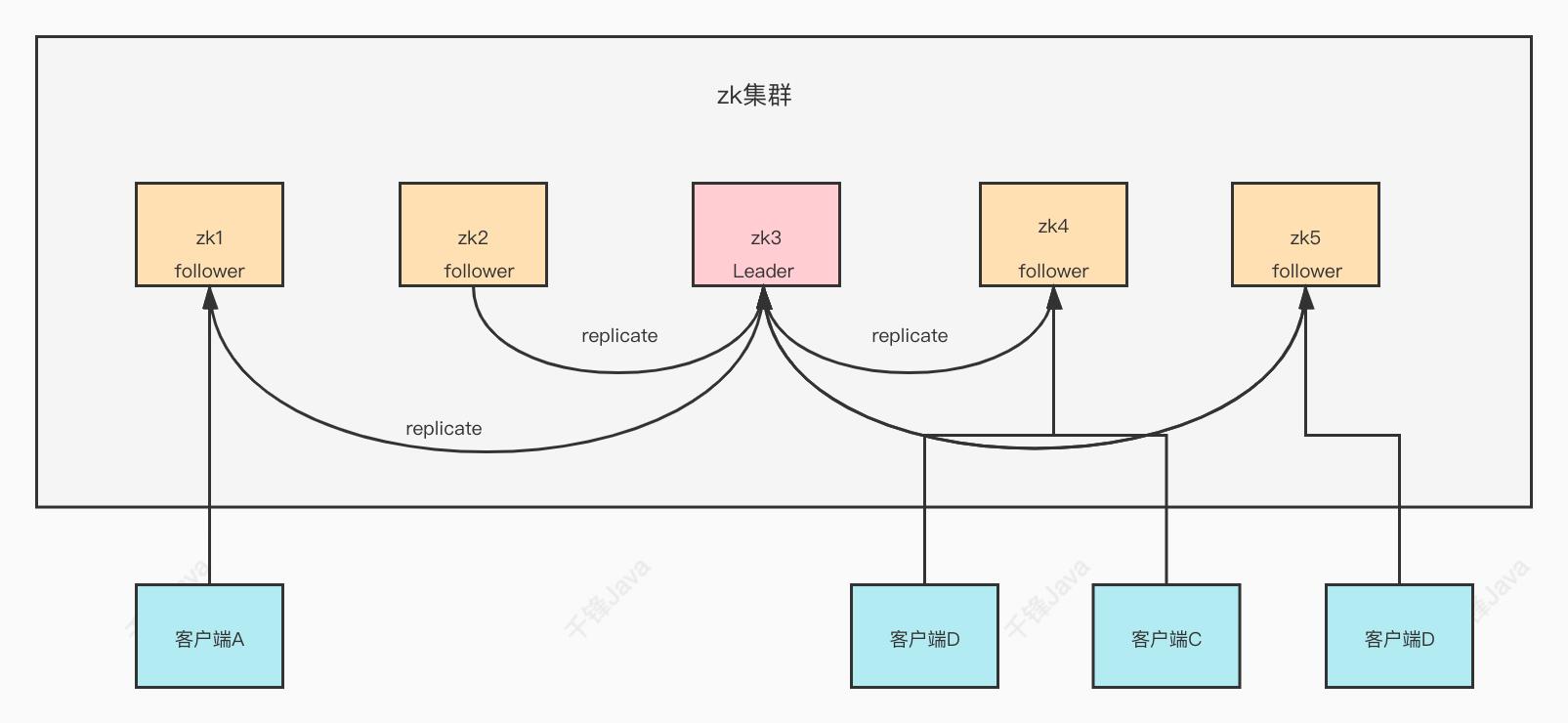
- zookeeper作为⾮常重要的分布式协调组件,需要进⾏集群部署,集群中会以⼀主多从的形式进⾏部署。zookeeper为了保证数据的⼀致性,使⽤了ZAB(Zookeeper AtomicBroadcast)协议,这个协议解决了Zookeeper的崩溃恢复和主从数据同步的问题。
2.ZAB协议定义的-----四种节点状态
- Looking :选举状态。
- Following :Follower 节点(从节点)所处的状态。
- Leading :Leader 节点(主节点)所处状态。
- Observing:观察者节点所处的状态
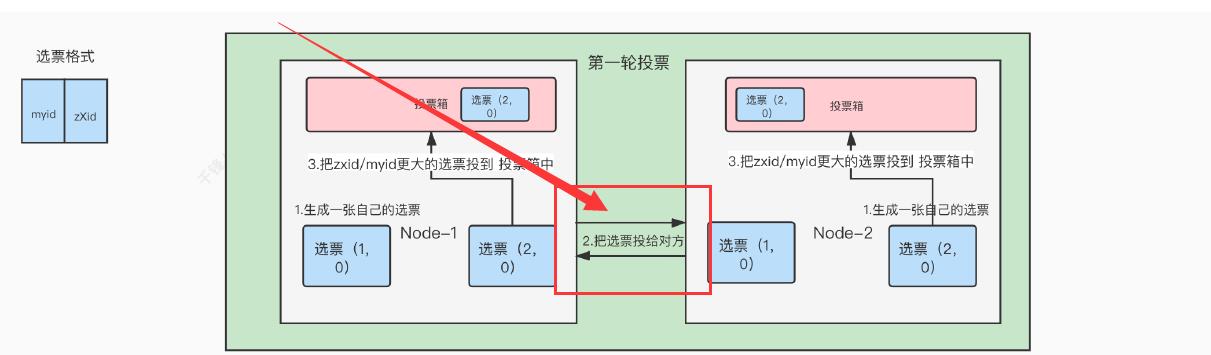
3.集群上线时的Leader选举过程
Zookeeper集群中的节点在上线时,将会进⼊到Looking状态,也就是选举Leader的状态,这
个状态具体会发⽣什么?
超集群数半数同意,即可当选主机
- 生成一张自己的选票
- 把选票发送短信给对方
- 把zxid/myid最大的选票投到 投票投到投票箱中
- 投票箱中有超过集群半数的服务器节点,当选为Lead,选举结束
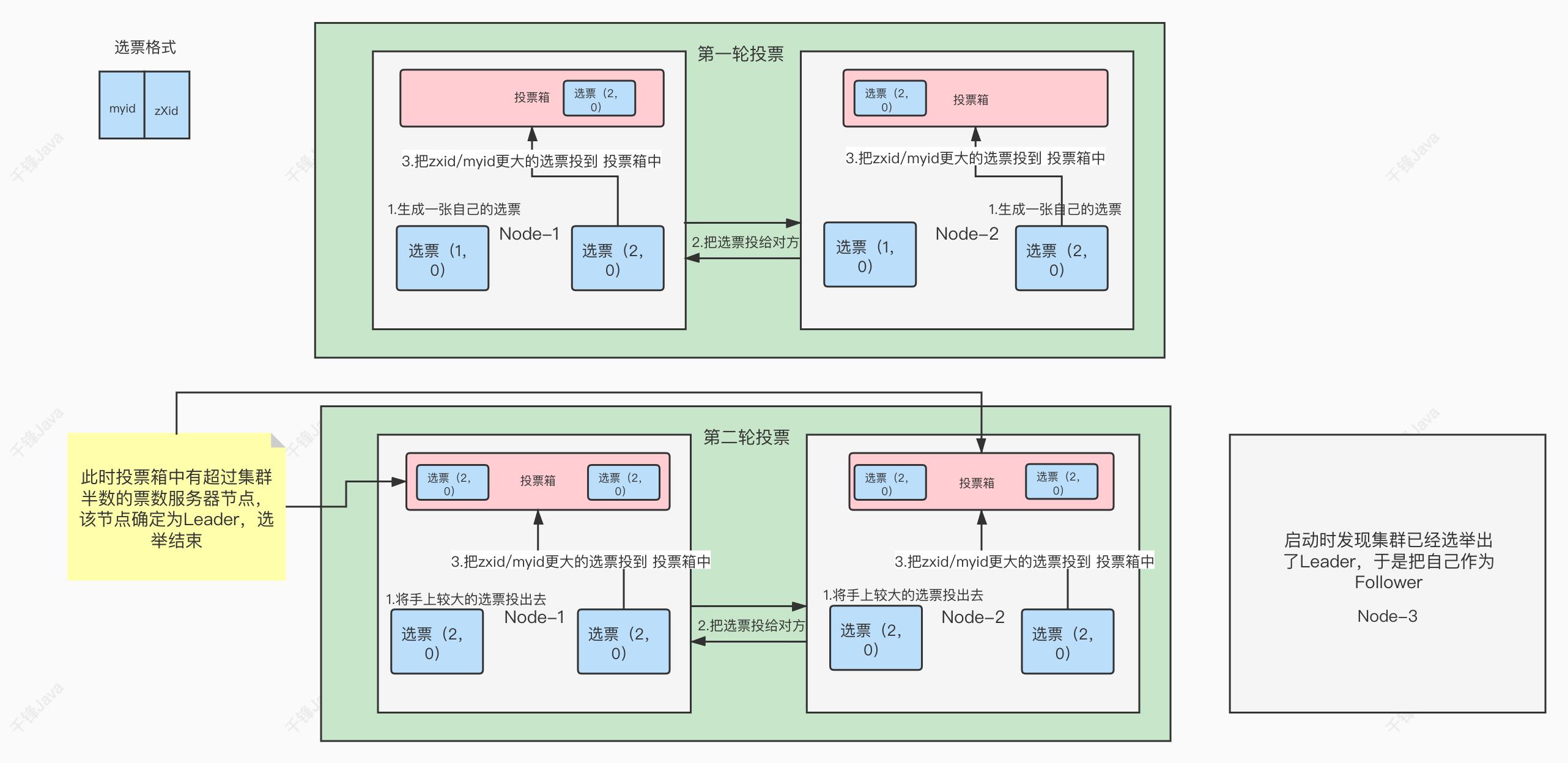
zxid : 事务id 、 myid: 创建集群时定义的id
题目

4.崩溃恢复时的Leader选举
- Leader建⽴完后,Leader周期性地不断向Follower发送⼼跳(ping命令,没有内容的 socket)。
- 当Leader崩溃后,Follower发现socket通道已关闭,于是Follower开始进⼊到 Looking状态,
- 重新回到上⼀节中的Leader选举过程,此时集群不能对外提供服务。
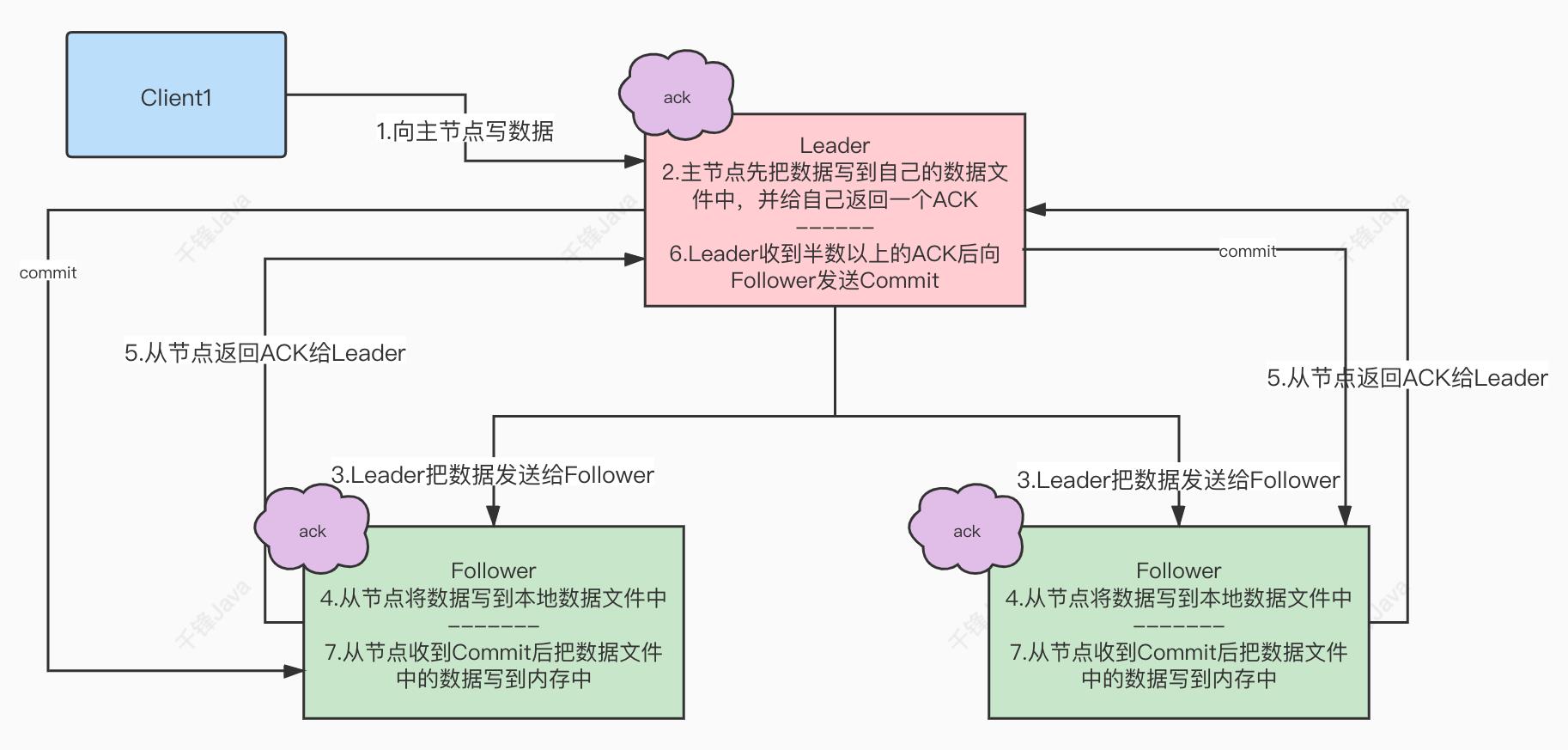
5.主从服务器之间的数据同步
二阶段提交
- 向主节点写数据
- 主节点先把数据写到自己的数据文件中,并给自己返回一个ACK
- Leader把数据发给Follower
- 从节点讲数据写到本地数据文件中
- 从节点返回ACK给Leader
- Leader 收到半数以上的ACK后,向Follower 发送Commit
- 从节点收到Commit后 把数据文件中的数据写到内存中
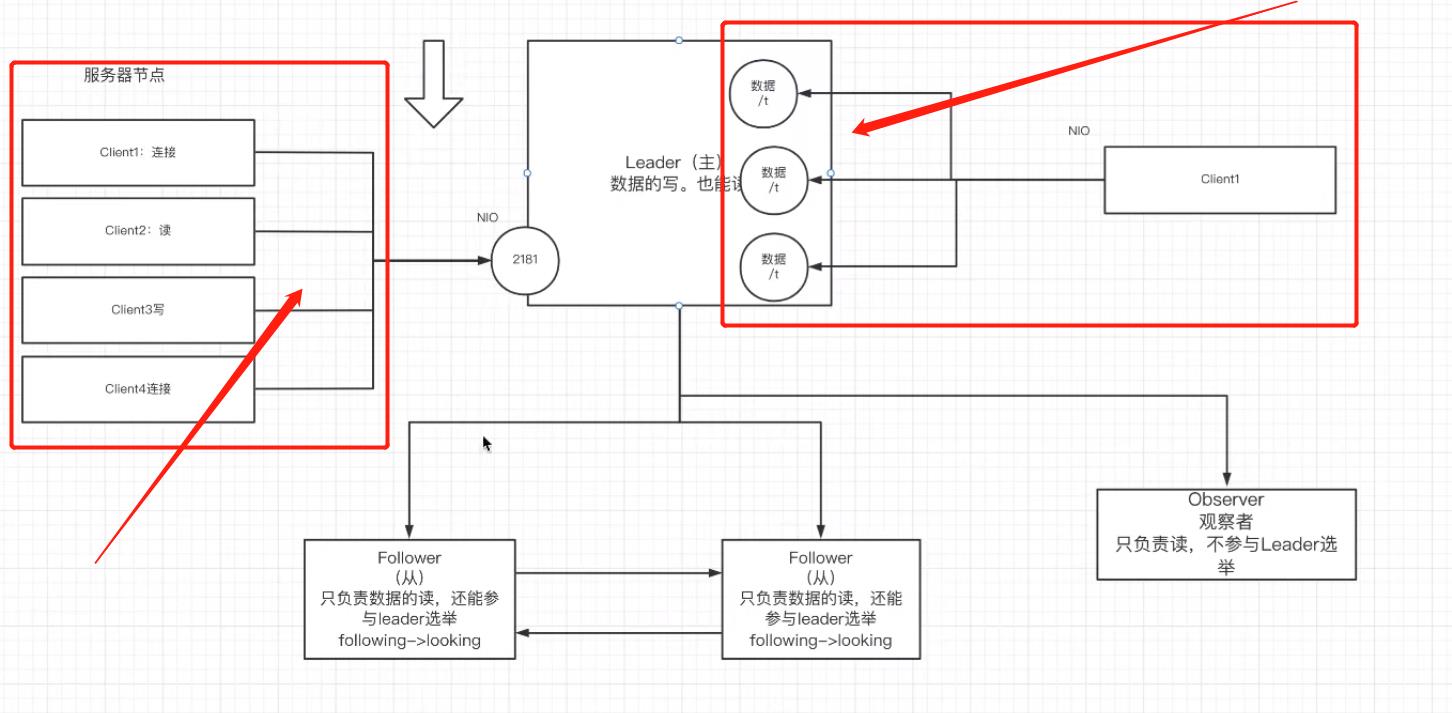
6.Zookeeper中的NIO与BIO的应⽤
- 早期Zookeeper用NIO,
- 后期Zookeeper,3.1 以后 用Netty
NIO–01–BIO,NIO,AIO简介
NIO场景
- ⽤于被客户端连接的2181端⼝,使⽤的是NIO模式与客户端建⽴连接
- 客户端开启Watch时,也使⽤NIO,等待Zookeeper服务器的回调
BIO场景
- 集群在选举时,多个节点之间的投票通信端⼝,使⽤BIO进⾏通信。
以上是关于Zookeeper--09---Zookeeper集群 ZAB协议的主要内容,如果未能解决你的问题,请参考以下文章