redis主从复制,哨兵机制,缓存穿透缓存击穿缓存雪崩
Posted 小智RE0
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了redis主从复制,哨兵机制,缓存穿透缓存击穿缓存雪崩相关的知识,希望对你有一定的参考价值。
版权声明:本文转载自为CSDN博主「面向cv编」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/m0_49797779/article/details/122346308
转载自博主 面向cv编
关系型数据库与非关系型数据库
关系型数据库
采用关系模型来组织数据的数据库,关系模型就是二维表格模型。一张二维表的表名就是关系,二维表中的一行就是一条记录,二维表中的一列就是一个字段。
- (1)优点
容易理解;使用方便,通用的sql 语言;易于维护,丰富的完整性(实体完整性、参照完整性和用户定义的完整性)大大降低了数据冗余和数据不一致的概率缺点 - (2)缺点
磁盘 I/O 是并发的瓶颈;海量数据查询效率低;
横向扩展困难,无法简单的通过添加硬件和服务节点来扩展性能和负载能力,
当需要对数据库进行升级和扩展时,需要停机维护和数据迁移多表的关联查询以及复杂的数据分析类型的复杂 sql 查询,性能欠佳。因为要保证 ACID.
非关系型数据库
非关系型,分布式,一般不保证遵循 ACID 原则的数据存储系统。键值对存储,结构不固定。
- (1)优点
根据需要添加字段,不需要多表联查。仅需 id 取出对应的 value严格上讲不是一种数据库,而是一种数据结构化存储方法的集合 - (2)缺点
只适合存储一些较为简单的数据;不适合复杂查询的数据;不适合持久存储海量数据
主从复制
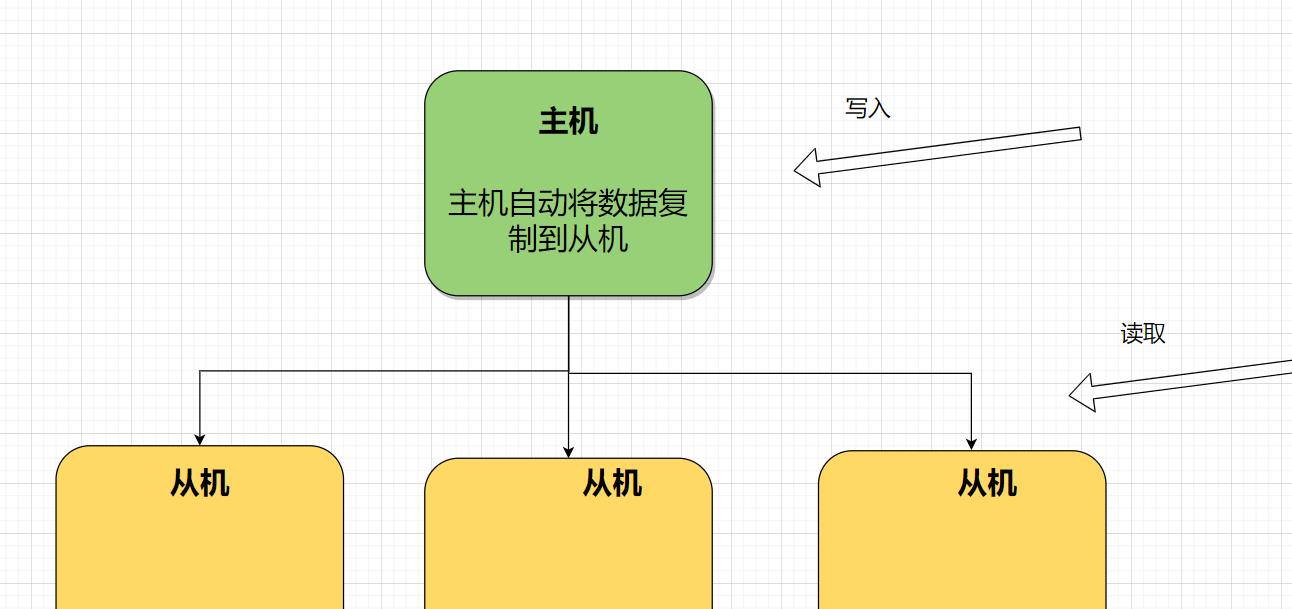
主从复制,是指将一台 Redis 服务器的数据,复制到其他的 Redis 服务器。前者称为主节点(master),后者称为从节点(slave),数据的复制是单向的,只能由主节点到从节点。
使用一个 Redis 实例作为主机,其余的作为备份机。主机和备份机的数据完全一致,主机支持数据的写入和读取等各项操作,而从机则只支持与主机数据的同步和读取。也就是说,客户端可以将数据写入到主机,由主机自动将数据的写入操作同步到从机。主从模式很好的解决了数据备份问题,并且由于主从服务数据几乎是一致的,因而可以将写入数据的命令发送给主机执行,而读取数据的命令发送给不同的从机执行,从而达到读写分离的目的。
当主机挂掉时,会在从机中选举出一位作为暂时主机;
当主机恢复后,暂时主机恢复从机身份
主要作用:
- 数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
- 故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余。
- 负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写 Redis 数据时应用连接主节点,读 Redis 数据时应用连接从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高 Redis 服务器的并发量。
- 高可用(集群)基础:除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是 Redis 高可用的基础。
配置:
主从复制时只需要配置从库即可,其默认为主库模式.
打开 redis 客户端登录,使用命令 info replication 查看. 主从复制可以搭建真集群,也可以搭建伪集群.真集群就是有多台主机,每台主机安装一个 redis.伪集群就是在一台主机上复制多份配置,修改其端口,运行多个redis 实例.配置方式两者相同.

主机配置
bind 0.0.0.0 #任何 ip 都可以访问
daemonize yes 后台运行
pidfile /var/run/redis_6379.pid #进程号文件
logfile "6379.log" #日志文件 注意文件名修改只是为了区分
dbfilename dump6379.rdb #数据文件
requirepass root #主机密码
从机配置
#bind 注释
daemonize yes 后台运行
pidfile /var/run/redis_6380.pid #进程号文件
logfile "6380.log" #日志文件 注意文件名修改只是为了区分
dbfilename dump6380.rdb #数据文件
replicaof <masterip>主机 ip <masterport>主机端口
masterauth <master-password>主机密码
实际操作
注意从机需要改端口port


在从机中配置主机IP端口 ;以及主机密码

进入客户端,使用 info replication 命令即可查看主从机的模式
注意:
主机断开连接,从机依旧连接到主机的,但是没有写操作,这个时候,主机如果 回来了,从机依旧可以直接获取到主机写的信息!
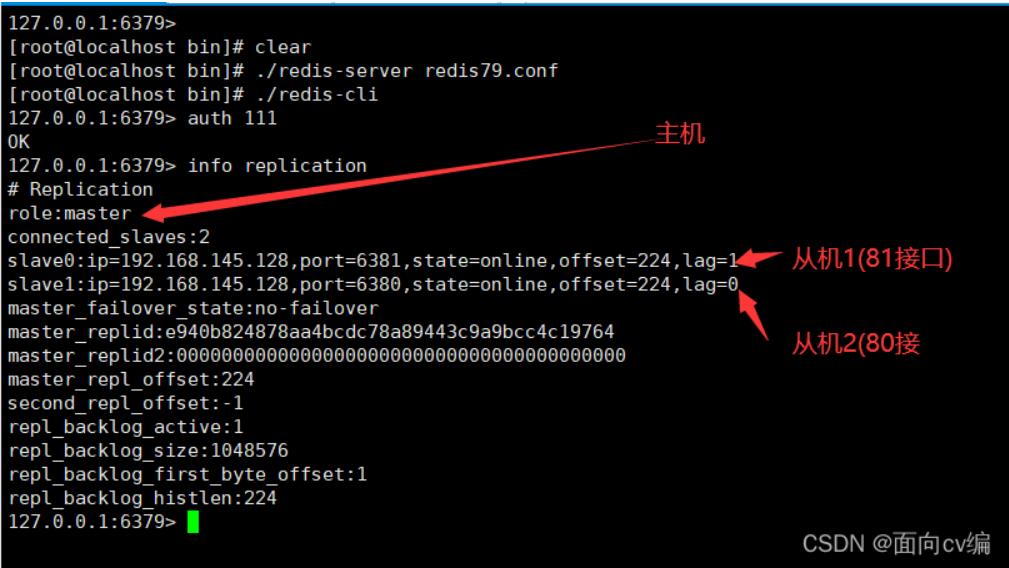
进入客户端,使用 info replication 命令查看模式:
查看主机(79接口)
从机(80接口)
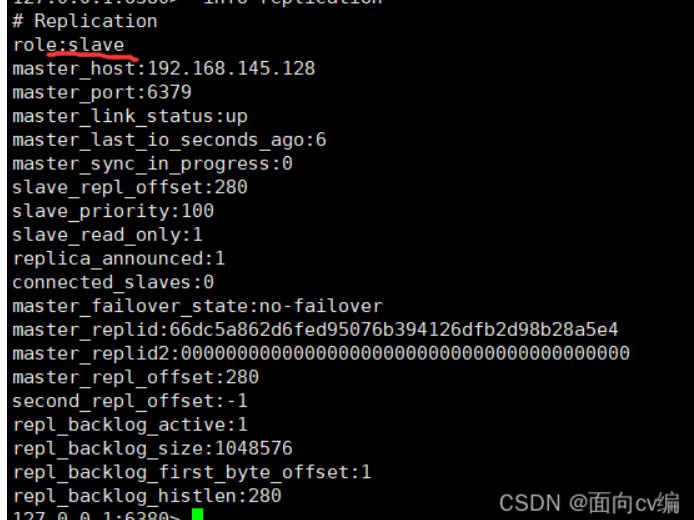
从机(81接口)
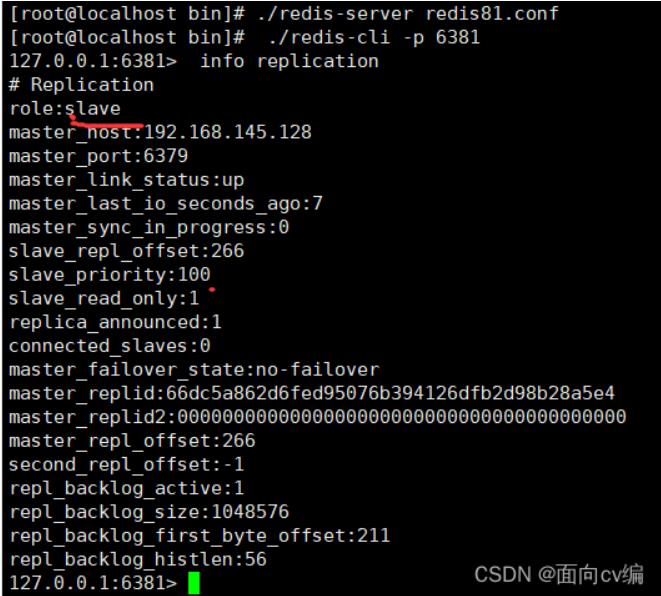
测试主写从读
之前安装redis时忘了没有说, ps -ef | grep redis 这个可以查看redis的状态.
kill -9 进程号 这个可以结束进程为某的redis服务
接下来我们测试主写从读:
主机set:
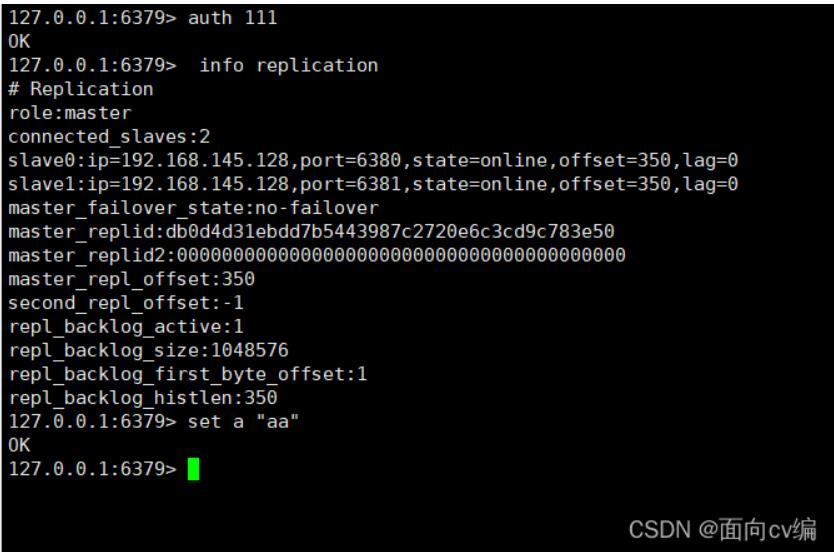
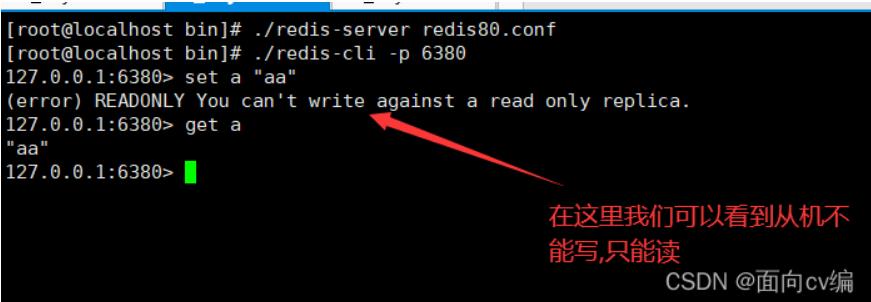
从机读(从机只能读,不能写):
从机(80接口):
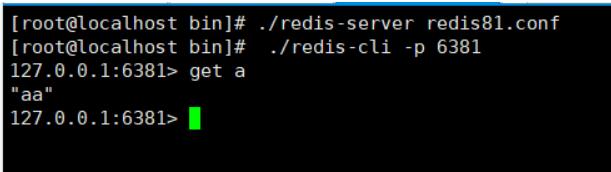
从机(81接口):
哨兵机制
哨兵模式是一种特殊的模式,首先 Redis 提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它会独立运行。其原理是哨兵通过发送命令,等待 Redis 服务器响应,从而监控运行的多个 Redis 实例。
单哨兵

哨兵集群

缓存穿透、缓存击穿、缓存雪崩
缓存处理流程
前台请求,后台先从缓存中取数据,取到直接返回结果,取不到时从数据库中取,
数据库取到更新缓存,并返回结果,数据库也没取到,那直接返回空结果。
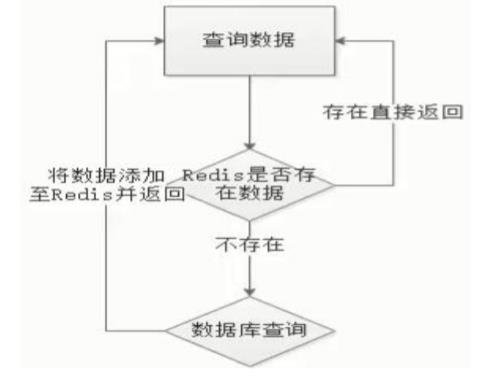
缓存穿透 数据库没有,缓存没有.
key 对应的数据在数据库中并不存在,每次针对此 key 的请求从缓存获取不到,请求都会到数据库,从而可能压垮数据库。比如用一个不存在的用户 id 获取用户信息,不论缓存还是数据库都没有,若黑客利用此漏洞进行攻击可能压垮数据库。

解决办法:
1.使用布隆过滤器(BloomFilter)或者压缩 filter 提前拦截.
2.将这个空对象设置到缓存里边去。下次再请求的时候,就可以从缓存里边获取了。这种情况我们一般会将空对象设置一个较短的过期时间.
3.对参数进行校验,不合法参数进行拦截.
缓存击穿
某个 key 对应的数据库中存在,但在 redis 中的某个时间节点过期了,此时若有大量并发请求过来,这些请求发现缓存过期,都会从后端 DB 加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端 DB 压垮。
解决办法:
1.热点数据设置永不过期
2.加互斥锁:上面的现象是多个线程同时去查询数据库的这条数据,那么可以在第一个查询数据的请求上使用一个互斥锁来锁住它其他的线程走到这一步拿不到锁就等着,等第一个线程查询到了数据,然后将数据放到 redis 缓存起来。后面的线程进来发现已经有缓存了,就直接走缓存.
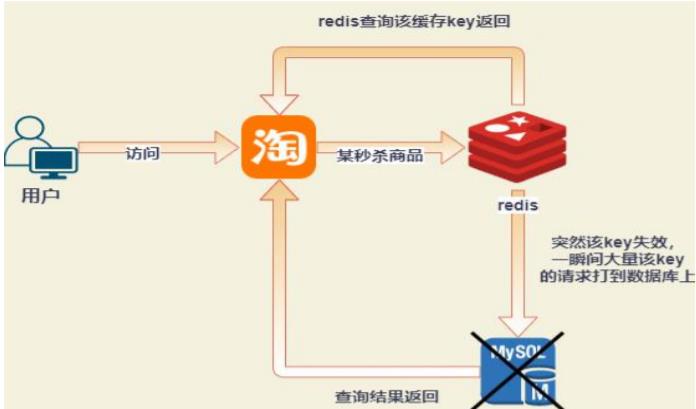
缓存雪崩
在高并发情况下,大量的缓存失效,或者缓存层出现故障。于是所有的请求都会达到数据库,数据库的调用量会暴增,造成数据库也会挂掉的情况。

解决方式
- 1.随机设置 key 失效时间,避免大量 key 集体失效。
setRedis(Key,value,time + Math.random() * 10000); - 2.若是集群部署,可将热点数据均匀分布在不同的 Redis 库中也能够避免 key
全部失效问题 - 3.不设置过期时间
- 4.跑定时任务,在缓存失效前刷进新的缓存
雪崩是大面积的key缓存失效;穿透是redis里不存在这个缓存key;击穿是redis
某一个热点 key 突然失效,最终的受害者都是数据库。
对于“Redis 宕机,请求全部走数据库”这种情况,我们可以有以下的思路:
事发前:实现 Redis 的高可用(主从架构+Sentinel(哨兵),尽量避免 Redis
挂掉这种情况发生。
事发中:万一 Redis 真的挂了,我们可以设置本地缓存(ehcache)+限流,尽量
避免我们的数据库被干掉(起码能保证我们的服务还是能正常工作的)
事发后:redis 持久化,重启后自动从磁盘上加载数据,快速恢复缓存数据。
版权声明:本文转载自为CSDN博主「面向cv编」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/m0_49797779/article/details/122346308
以上是关于redis主从复制,哨兵机制,缓存穿透缓存击穿缓存雪崩的主要内容,如果未能解决你的问题,请参考以下文章