初始 http网络
Posted 一朵花花
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了初始 http网络相关的知识,希望对你有一定的参考价值。
前言: 生活中,我们在上网时,打开一个网页,就可以看到网址,如下:
https://blog.csdn.net/m0_47988201?spm=1011.2124.3001.5343
访问网站使用的协议类型:https(基于 http 实现的,只不过在 http 基础上引入一个加密层)
http 和 https 都是应用层协议
应用层的协议都需要程序猿来手动指定(自己定制协议)
http 协议是基于 tcp 来实现的
URL
平时我们俗称的 “网址” ,其实就是说的URL
表示网络上的唯一一个资源的标识符
URL 是 http 协议的重要组成部分,但不是 http 协议的专属,它可以搭配很多协议来使用

URL中,对应的 path 不同的时候,获取到的页面也不同
URL 中的服务器的IP来确定一个服务器
URL 中的服务器端口来确定这个主机上的哪个进程
URL 中的 path 来确定这个进程中所管理的哪个资源 / 文件
最终一次 http 请求得到的 “网页” ,本质上就是一个文件
urlencode 和 urldecode
先看一个例子:
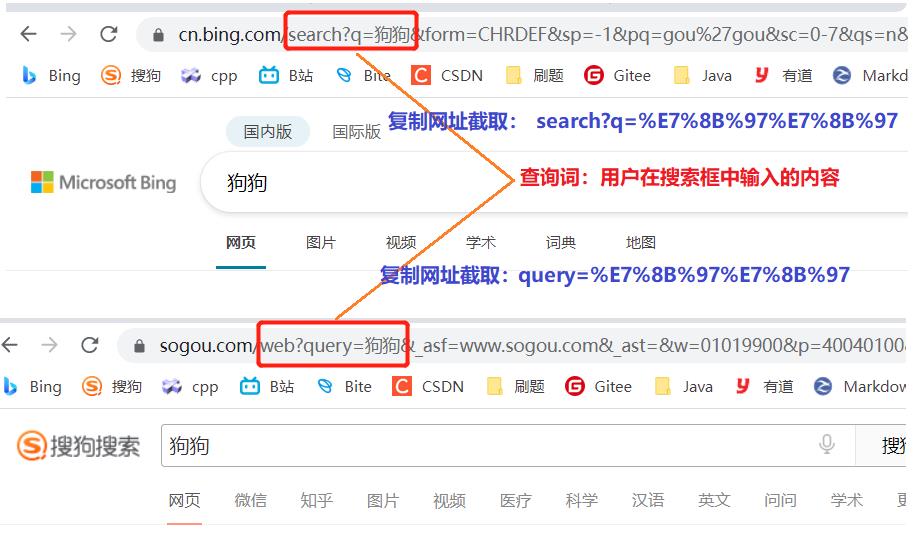
上述就是进行了 urlencode
把 url 中包含的中文和特殊符号,进行了转义,转义成 % + 十六进制数字的形式
转义理由: url 中本身包含了一些特殊用途的符号,例如 :/ & ? # … 这些特殊符号,不能在 url 的查询字符串中出现(有可能导致浏览器解析出错)
将上述结果还原回去,就是 urldecode,也就是是 urlencode 的逆过程
http 协议格式
学习 http协议主要理解协议报文格式
可以借助专门的"抓包"工具,就可以分析 http 具体的协议内容(fiddler)
fiddler 相当于是一个"代理" —— “代购”
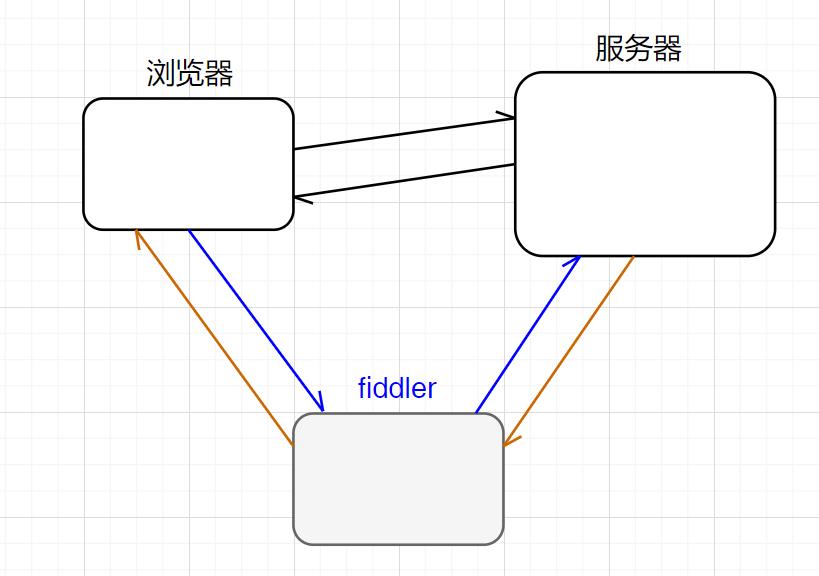
fiddler 一般不会对传输的数据进行修改、加工,只是把传输的数据截获了下来,让用户能直接看到
fiddler 界面上主要有三个部分
左侧:抓到的包的列表,选中你要查看的某个包
右上:这个包的请求内容
右下:这个包的响应内容
http 请求
Raw:点击 Raw 之后,可以看到请求的原始数据
例如:
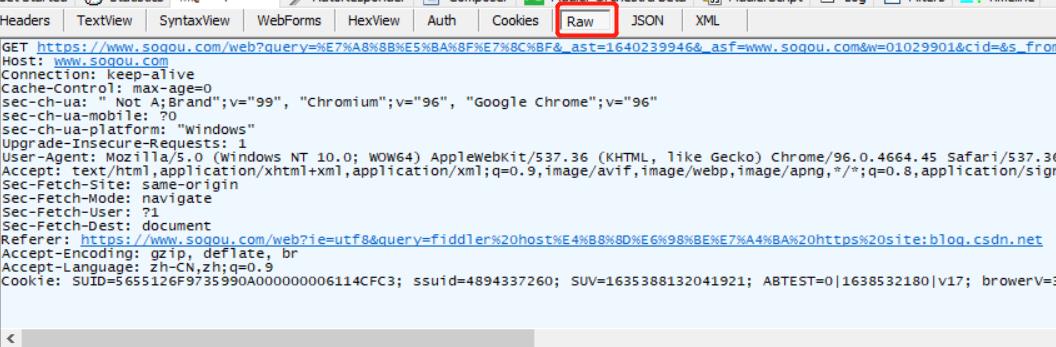
上述的请求数据,内容基本可以看懂,说明这是"文本数据"
http 协议,本质上就是一个文本格式的协议
1.首行:
GET https://www.sogou.com/web?query=%E7%A8%8B%E5%BA%8F%E7%8C%BF
&_ast=1640239946
&_asf=www.sogou.com
&w=01029901&cid=
&s_from=result_up
&sut=1762
&sst0=1640239997761
&lkt=0%2C0%2C0
&sugsuv=1635388132041921
&sugtime=1640239997761 HTTP/1.1
①方法 (GET)
②URL (上述:从 GET 后开始,到 HTTP 之前结束)
③版本号
上述三个内容以空格隔开,可以复制到记事本中查看
2.协议头(header):
协议头:首行之后的所有内容
Host: www.sogou.com
Connection: keep-alive
Cache-Control: max-age=0
sec-ch-ua: " Not A;Brand";v="99", "Chromium";v="96", "Google Chrome";v="96"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "Windows"
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/96.0.4664.45 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Sec-Fetch-Site: same-origin
Sec-Fetch-Mode: navigate
Sec-Fetch-User: ?1
Sec-Fetch-Dest: document
Referer: https://www.sogou.com/web?ie=utf8&query=fiddler%20host%E4%B8%8D%E6%98%BE%E7%A4%BA%20https%20site:blog.csdn.net
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Cookie: SUID=5655126F9735990A000000006114CFC3; ssuid=4894337260; SUV=1635388132041921; ABTEST=0|1638532180|v17; browerV=3; osV=1; IPLOC=CN6101; cd=1639966211&0e4d216636a31ba117585c10d865a88f; rd=4yllllllll2PsMYjYb@ulLp@ikJPsMYRbeQe4kllll9llllxVllll5@@@@@@@@@@; SNUID=C7DCE79AF5F3253E7F642F5DF6600772; usid=3229126F6F3E990A0000000061C409E7; ld=tkllllllll2PsMYjYb@ulL499TdPsMYRbeQe4klllltlllllVZlll5@@@@@@@@@@; sst0=761
header:若干个键值对,键和值之间使用: (冒号+空格)来分割
此处的键值对可以是用户自定义的,但是大部分都是 http 中已有的,具有特定含义的内容
截取部分截图:

3.空行:
header 的结束标记
4.正文(body):
可能为空(GET)
可能非空(POST)
body 的长度取决于 Content-Lenth
body 的数据格式取决于 Content-Type
body 格式类似于 URL 中的查询字符串
使用 & 符号分割成多个键值对,每个键值对内部使用= 来分割键和值
http 响应
Raw:点击 Raw 之后,可以看到响应的原始数据
例如:
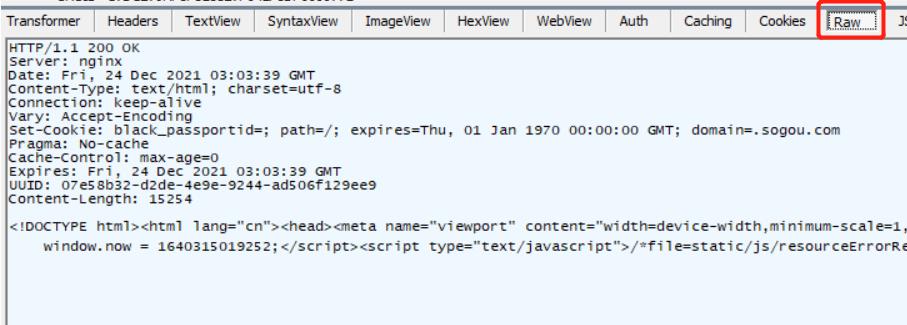
1.首行:
HTTP/1.1 200 OK
①版本号
②状态码 (上述200,表成功)
③状态码描述信息
2.协议头(header):
每一行是一个键值对,键和值之间使用: (冒号+空格)来分割
3.空行:
header 的结束标记
4.正文(body):
响应正文来说,最常见的数据格式就是 html,表示了一个网页的具体内容是啥样的
http的方法
GET,POST,PUT,HEAD,DELETE,OPTIONS,TRACE,CONNECT,LINK,UNLINK
其中最常用的就是 GET 和 POST
POST 和 GET 的区别???
GET 一般把数据放到 url 中
POST 一般把数据放到 body 中
http的状态码
状态码有很多,为了方便理解,分成了几个大类
| 类别 | 原因短语 | |
|---|---|---|
| 1XX | Informational (信息性状态码) | 接收的请求正在处理 |
| 2XX | Success (成功状态码) | 请求正常处理完毕 |
| 3XX | Redirection (重定向状态码) | 需要进行附加操作以完成请求 |
| 4XX | Client Error (客户端错误状态码) | 服务器无法处理请求 |
| 5XX | Server Error (服务器错误状态码) | 服务器处理请求出错 |
重定向: 访问一个页面的时候,自动跳转到另一个页面
最常见的状态码, 比如 200(OK), 404(Not Found),403(Forbidden),302(Redirect 重定向),504(Bad Gateway)
404(Not Found) —— 客户端尝试请求的资源非法
403(Forbidden) —— 访问没有权限
http常见header
- Content-Type: 数据类型(text/html等)
- Content-Length: Body的长度 (以字节为单位)
- Host: 客户端告知服务器,所请求的资源是在哪个主机的哪个端口上
- User-Agent: 声明用户的操作系统和浏览器版本信息
- referer: 当前页面是从哪个页面跳转过来的
有些请求是没有 referer 的,例如:直接在浏览器中输入 url;点击收藏夹打开的网站 - location: 搭配 3xx 状态码使用,告诉客户端接下来要去哪里访问;
- Cookie: 用于在客户端存储少量信息,通常用于实现会话(session)的功能
(比较复杂,后边会写)
下篇,会结合本篇知识,来实现一个简单的 HTTP 服务器

以上是关于初始 http网络的主要内容,如果未能解决你的问题,请参考以下文章