Pytorch实现文本情感分类流程
Posted WXiujie123456
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pytorch实现文本情感分类流程相关的知识,希望对你有一定的参考价值。
基本概念介绍
tokenization:分词,每个词语就是一个token
分词方法:
- 转化为单个字(常见)
- 切分词语
N-gram:准备词语特征的方法,N-gram一组一组的词语,其中N表示能够一起使用的词的数量(可以使用jieba类,需要用到再去查)
文本的向量化:
-
one-hot:使用稀疏的向量表示文本,占用空间多,每一个token使用一个长度为N的向量表示,N表示词典的数量
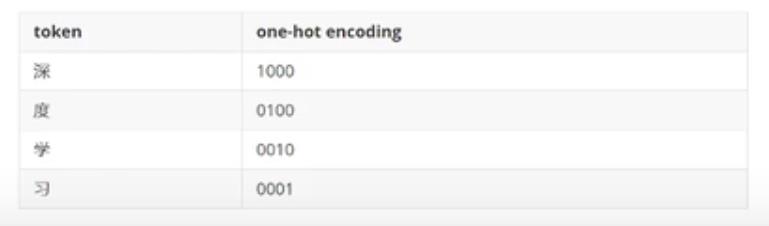
-
Word embedding:
a. 浮点型的稠密矩阵表示token
b. 向量中的每一个值都是一个超参数,其初始值是随机生成的,之后会在训练的过程中进行学习而获得
c. api:torch.nn.Embedding(词典的数量,embedding的维度)
d. 形状的变化:[batch_size,seq_len] —> [batch_size,seq_len,embedding_dim]
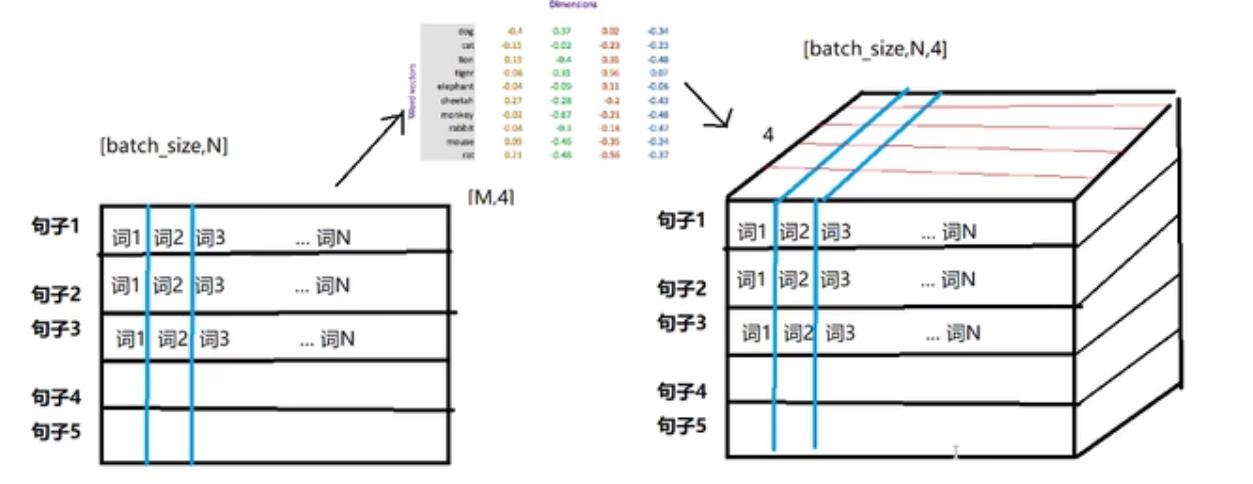
文本情感分类
准备数据集
from torch.utils.data import DataLoader ,Dataset
import os
import re
def tokenlize(content):
'''
对内容进行一些正则化操作 去掉一些无关符号
:param content:
:return:
'''
content = re.sub(r'<.*?>',' ',content)
filters = ['\\t','\\n','\\x97','\\x96','#','$','%','&',':']
#re.sub()方法用于替换字符串中的匹配项
# sub(pattern, repl, string)
# pattern:该参数表示正则中的模式字符串;
# repl:该参数表示要替换的字符串(即匹配到pattern后替换为repl),也可以是个函数;
# string:该参数表示要被处理(查找替换)的原始字符串;
content = re.sub("|".join(filters)," ",content)
#去除单词后的句号、逗号
content = re.sub(r'[*\\.]',' ',content)
content = re.sub(r'[*\\,]',' ',content)
tokens = [i.strip() for i in content.split()]
return tokens
#准备数据集
class ImdbDataset(Dataset):
def __init__(self,train = True):
#设置训练路径和测试路径
self.train_data_path = r'F:\\Learn_pytorch\\aclImdb\\train'
self.test_data_path = r'F:\\Learn_pytorch\\aclImdb\\test'
data_path = self.train_data_path if train else self.test_data_path
#把所有的文件名放入列表
temp_data_path = [os.path.join(data_path,'pos'),os.path.join(data_path,'neg')]
self.total_file_path = []
for path in temp_data_path:
#以列表的形式加载路径
file_name_list = os.listdir(path)
#过滤文件,只有后缀是.txt的文件才符合
file_path_list = [os.path.join(path,i) for i in file_name_list if i.endswith('.txt')]
self.total_file_path.extend(file_path_list)
def __getitem__(self, index):
#当前index对应的文件位置
file_path = self.total_file_path[index]
# 获取lable,路径特点 F:\\Learn_pytorch\\aclImdb\\train\\pos\\0_9.txt
# print(file_path)
label_str = file_path.split('\\\\')[-2]#按照\\进行分割,取倒数第二个
# print(label_str)
#label:0:neg 1:pos
label = 0 if label_str == 'neg' else 1
#获取内容,使用tokenlize方法对句子进行分词操作:
tokens = tokenlize(open(file_path).read())
return tokens,label
def __len__(self):
#这里在调试的时候,一定要预设一个返回值且为整型,否则DataLoader调用Dataset时会报错
return 1
#准备dataloader
def get_dataLoader(train=True):
imdbdataset = ImdbDataset(train)
# print(imdbdataset[0])
data_loader = DataLoader(imdbdataset,batch_size=2,shuffle=True)
return data_loader
if __name__ == '__main__':
# my_str = 'Bromwell High is a cartoon comedy. It ran at the same time as some other programs about school life, such as "Teachers". My 35 years in the teaching profession lead me to believe that Bromwell High\\'s satire is much closer to reality than is "Teachers". The scramble to survive financially, the insightful students who can see right through their pathetic teachers\\' pomp, the pettiness of the whole situation, all remind me of the schools I knew and their students. When I saw the episode in which a student repeatedly tried to burn down the school, I immediately recalled ......... at .......... High. A classic line: INSPECTOR: I\\'m here to sack one of your teachers. STUDENT: Welcome to Bromwell High. I expect that many adults of my age think that Bromwell High is far fetched. What a pity that it isn\\'t!'
# print(tokenlize(my_str))
get_dataLoader(True)
#观察数据输出结果
for idx,(input,target) in enumerate(get_dataLoader()):
print(idx)
print(input)
print(target)
break
输出结果如下:
0
[('Bromwell',), ('High',), ('is',), ('a',), ('cartoon',), ('comedy',), ('It',), ('ran',), ('at',), ('the',), ('same',), ('time',), ('as',), ('some',), ('other',), ('programs',), ('about',), ('school',), ('life',), ('such',), ('as',), ('"Teachers"',), ('My',), ('35',), ('years',), ('in',), ('the',), ('teaching',), ('profession',), ('lead',), ('me',), ('to',), ('believe',), ('that',), ('Bromwell',), ("High's",), ('satire',), ('is',), ('much',), ('closer',), ('to',), ('reality',), ('than',), ('is',), ('"Teachers"',), ('The',), ('scramble',), ('to',), ('survive',), ('financially',), ('the',), ('insightful',), ('students',), ('who',), ('can',), ('see',), ('right',), ('through',), ('their',), ('pathetic',), ("teachers'",), ('pomp',), ('the',), ('pettiness',), ('of',), ('the',), ('whole',), ('situation',), ('all',), ('remind',), ('me',), ('of',), ('the',), ('schools',), ('I',), ('knew',), ('and',), ('their',), ('students',), ('When',), ('I',), ('saw',), ('the',), ('episode',), ('in',), ('which',), ('a',), ('student',), ('repeatedly',), ('tried',), ('to',), ('burn',), ('down',), ('the',), ('school',), ('I',), ('immediately',), ('recalled',), ('at',), ('High',), ('A',), ('classic',), ('line:',), ('INSPECTOR:',), ("I'm",), ('here',), ('to',), ('sack',), ('one',), ('of',), ('your',), ('teachers',), ('STUDENT:',), ('Welcome',), ('to',), ('Bromwell',), ('High',), ('I',), ('expect',), ('that',), ('many',), ('adults',), ('of',), ('my',), ('age',), ('think',), ('that',), ('Bromwell',), ('High',), ('is',), ('far',), ('fetched',), ('What',), ('a',), ('pity',), ('that',), ('it',), ("isn't!",)]
tensor([1])
输出效果并不是很理想,,类似于进行了zip()的操作,将token打包成一个元组。
出现问题的原因在于Dataloader中的参数collate_fn
def __init__(self, dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None, multiprocessing_context=None)
collate_fn的默认值为None(反正我自己的电脑写的是None,但是教程上的默认方法是default_collate),不做处理。
dataset的运行机制:
在dataloader按照batch进行取数据的时候, 是取出大小等同于batch size的index列表; 然后将列表列表中的index输入到dataset的getitem()函数中,取出该index对应的数据; 最后, 对每个index对应的数据进行堆叠, 就形成了一个batch的数据.
解决问题的思路:
手段1:考虑先把数据转化为数字序列,观察其结果是否符合要求,之前使用DataLoader并未出现类似错误
手段2:考虑自定义一个collate_fn,观察结果
这里使用手段2:
def collate_fn(batch):
'''
:param batch: (一个getitem的结果,一个getitem的结果,···)即([token,label],[token,label],...]
:return:
'''
content,label = list(zip(*batch))
print(content)
print(label)
return content,label
data_loader = DataLoader(imdbdataset,batch_size=2,shuffle=True,collate_fn=collate_fn)
输出如下:
(['bromwell', 'high', 'is', 'a', 'cartoon', 'comedy', 'it', 'ran', 'at', 'the', 'same', 'time', 'as', 'some', 'other', 'programs', 'about', 'school', 'life', 'such', 'as', 'teachers', 'my', '35', 'years', 'in', 'the', 'teaching', 'profession', 'lead', 'me', 'to', 'believe', 'that', 'bromwell', "high's", 'satire', 'is', 'much', 'closer', 'to', 'reality', 'than', 'is', 'teachers', 'the', 'scramble', 'to', 'survive', 'financially', 'the', 'insightful', 'students', 'who', 'can', 'see', 'right', 'through', 'their', 'pathetic', "teachers'", 'pomp', 'the', 'pettiness', 'of', 'the', 'whole', 'situation', 'all', 'remind', 'me', 'of', 'the', 'schools', 'i', 'knew', 'and', 'their', 'students', 'when', 'i', 'saw', 'the', 'episode', 'in', 'which', 'a', 'student', 'repeatedly', 'tried', 'to', 'burn', 'down', 'the', 'school', 'i', 'immediately', 'recalled', 'at', 'high', 'a', 'classic', 'line', 'inspector', "i'm", 'here', 'to', 'sack', 'one', 'of', 'your', 'teachers', 'student', 'welcome', 'to', 'bromwell', 'high', 'i', 'expect', 'that', 'many', 'adults', 'of', 'my', 'age', 'think', 'that', 'bromwell', 'high', 'is', 'far', 'fetched', 'what', 'a', 'pity', 'that', 'it', "isn't"], 1)
文本的序列化
word embedding流程: 文本 —> 数字—>向量
如何实现上述过程呢?
我们可以考虑把文本中的每个词语和其对应的数字使用字典保存,同时实现方法把句子通过字典映射为包含数字的列表。
实现文本序列化之前,考成以下几点
- 如何使用字典把词语和数字进行对应
- 不同的词语出现的次数不尽相同,是否需要对高频或者低频词语进行过滤,以及总的词语数量是否需要进行限制
- 得到词典之后,如何把句子转化为数字序列,如何把数字序列转化为句子
- 不同句子长度不相同,每个 batch的句子如何构造成相同的长度(可以对短句子进行填充,填充特殊字符)
- 对于新出现的词语在词典中没有出现怎么办(可以使用特殊字符代理)
思路分析:
1. 对所有句子进行分词
2. 词语存入字典,根据次数对词语进行过滤,并统计次数
3. 实现文本转数字序列的方法
4. 实现数字序列转文本的方法
'''
实现:构建词典,实现方法把句子转化为数字序列,以及从数字序列转化为句子
dict 中存放word:序号
inverse_dict中存放序号:word
count中存放word:词频
'''
class Word2Sequence:
UNK_TAG = 'UNK' #
PAD_TAG = 'PAD' #
UNK = 0
PAD = 1
def __init__(self):
self.dict =
self.UNK_TAG:self.UNK,
self.PAD_TAG:self.PAD
self.count = #统计词频
def fit(self,sentence): #每次使用该类时需要先调用这个传入单个的词
'''
把单个句子保存到dict中
:param sentence: [word1,word2,word3,....]
:return:
'''
for word in sentence:
self.count[word] = self.count.get(word,0) + 1 #统计当前词语在句子中的出现频率
def build_vocab(self,min = 5,max = None,max_features = None):
'''
生成词典
:param min: 最小出现的次数
:param max: 最大出现的次数
:param max_features: 一共保存多少个词语
:return:
'''
#删除count中词频小于min的Word
if min is not None:
self.count = word:value for word,value in self.count.items() if value>min
#删除count中词频大于max的Word
if max is not None:
self.count = word:value for word,value in self.count.items() if value<max
#根据max_features,限制保留词语数
if max_features is not None:
temp = sorted(self.count.items(),key=lambda x:x[-1],reverse=True)[:max_features]#实现按照频率排序并且取前max_features个,此处可以去简短程序里验证一下
self.count = dict(temp)
# print(self.count)
for word in self.count.keys():#self.count.keys()=self.count
# print(word)
self.dict[word] = len(self.dict) #不清楚
#得到一个翻转的dict的字典
self.inverse_dict = dict(zip(self.dict.values(),self.dict.keys())) #启发:直接翻转字典key:value
def transform(self,sentence,max_len=None):
'''
把句子转化为序列
:param sentence: [word1,word2,word3,....]
:param max_len: int,对句子进行填充或者裁剪
:return:
'''
if max_len is not None:
if max_len > len(sentence):
sentence = sentence + [self.PAD_TAG]*(max_len - len(sentence)) #填充
if max_len < len(sentence):
sentence = sentence[:max_len] #裁剪
return [self.dict.get(word,self.UNK) for word in sentence] #等同于self.dict[word],但是以防找不到Word,所以用get方法,第二个参数为word取不到时采取的默认值
def inverse_transform(self,indices):
'''
把序列转化为句子
:param indices:[1,2,3,4,...]
:return:
'''
return [self.inverse_dict.get(idx) for idx in indices]
if __name__ == '__main__':
ws = Word2Sequence()
ws.fit(['我','是','谁'])
ws.fit(['我', '是', '我'])
ws.build_vocab(min=0)
print(ws.dict)
ret = ws.transform(['我','爱','frank'],max_len=10)
print(ret)
ret = ws.inverse_transform(ret)
print(ret)
输出结果:
'UNK': 0, 'PAD': 1, '我': 2, '是': 3, '谁': 4
[2, 0, 0, 1, 1, 1, 1, 1, 1, 1]
['我', 'UNK', 'UNK', 'PAD', 'PAD', 'PAD', 'PAD', 'PAD', 'PAD', 'PAD']
ws的保存:
import pickle
import os
from realize_Imdb import tokenlize
from tqdm import tqdm #进度条
from word_sequence import Word2Sequence# 在此导入Word2Sequence是因为需要调用pickle处理,保证在别处调用是一致的
if __name__ == '__main__':
#实例化ws
ws = Word2Sequence()
path = r'F:\\Learn_pytorch\\aclImdb\\train'
#获取pos和neg文件的路径
temp_data_path = [os.path.join(path, 'pos'), os.path.join(path, 'neg')]
#data_path 有两条
for data_path in temp_data_path:
#加载pos和neg文件夹下所有文件存放在file_path中
file_paths = [os.path.join(data_path,file_name) for file_name in os.listdir(data_path) if file_name.endswith('.txt')]
#按进度条显示加载每个文件中的句子信息,并进行fit处理,把单个句子保存到dict中
for file_path in tqdm(file_paths):#有进度条显示
sentence = tokenlize(open(file_path,encoding='UTF-8').read())#增加encoding='UTF-8',提高程序健壮性
ws.fit(sentence)
ws.build_vocab(min=10,max_features=10000)#生成词典
pickle.dump(ws,open('./model/ws.pkl','wb')) #写入文件中
print(len(ws))
输出如下:
99%|█████████▊| 12321/12500 [00:09<00:00, 1205.09it/s]100%|█████████▉| 12459/12500 [00:09<00:00, 1252.77it/s]100%|██████████| 12500/12500 [00:09<00:00, 1252.84it/s]
100%|█████████▉| 12492/12500 [00:09<00:00, 1375.99it/s]100%|██████████| 12500/12500 [00:09<00:00, 1361.00it/s]
10002
ws的加载:
import pickle
ws = pickle.load(open('./model/ws.pkl','rb'))
构建模型
这里我们只练习使用word embedding,所以模型只有一层,即
- 数据经过word embedding
- 数据经过全连接层返回结果,计算log_softmax
'''
定义模型
'''
import torch.nn as nn
from lib import ws,max_len
import torch.nn.functional as F
class ImdbModel(nn.Module):
def __init__(self):
super(ImdbModel,self).__init__()
self.embedding = nn.Embedding(num_embeddings=len(ws),embedding_dim=200,padding_idx=ws.UNK) #torch.nn.Embedding(词典的数量,embedding的维度)
self.fc = nn.Linear(max_len * 200,2)
def forward(self,input):
input_embeded = self.embedding(input)
input_embeded_viewed = input_embeded.view(input_embeded.size(0),-1) #变形
out = self.fc(input_embeded_viewed)#全连接
return F.log_softmax(out,dim=-1)
模型的训练与评估
训练代码如下:
from model import ImdbModel
from torch.optim import Adam
from dataset import get_dataLoader
import torch.nn.functional as F
from tqdm import tqdm
model = ImdbModel()
optimizer = Adam(model.parameters(),0.001)
def train(epoch):
train_dataloader = get_dataLoader(train=True)
bar = tqdm(train_dataloader,total=len(train_dataloader))
for idx,(input,target) in enumerate(bar):
optimizer.zero_grad()
output = model(input)
loss = F.nll_loss(output,target)
loss.backward()
optimizer.step()
bar.set_description("epcoh: idx: loss::.6f".format(epoch,idx,loss.item()))
if __name__ == '__main__':
for i in range(10):
train(i)
运行结果:
epcoh:0 idx:49 loss:0.683408: 100%|██████████| 50/50 [07:40<00:00, 9.20s/it]
epcoh:1 idx:49 loss:0.595776: 100%|██████████| 50/50 [00:44<00:00, 1.12it/s]
epcoh:2 idx:49 loss:0.540234: 100%|██████████| 50/50 [00:37<00:00, 1.35it/s]
训练过程如下:
from model import ImdbModel
from torch.optim import Adam
from dataset import get_dataLoader
import torch.nn.functional as F
import torch
model = ImdbModel()
optimizer = Adam(model.parameters(),0.001)
def test():
test_loss = 0
correct = 0
mode = False
model.eval()
test_dataloader = get_dataLoader(mode)
with torch.no_grad():
for input,target in test_dataloader:
out_put = model(input)
test_loss += F.nll_loss(out_put,target,reduction='sum')
pred = torch.max(out_put,dim=-1,keepdim=False)[-1]
correct = pred.eq(target.data).sum()
test_loss = test_loss / len(test_dataloader.dataset)
print('loss:',test_loss,' Accuracy:',correct)
if __name__ == '__main__':
test()
运行结果:
loss: tensor(0.7623) Accuracy: tensor(187)
这里我们仅仅使用了一层全连接层,其分类效果不会太好,这里重点理解常见的模型流程和 Word embedding的使用方法。
完整代码
dataset.py
'''
准备数据
'''
from torch.utils.data import DataLoader ,Dataset
import os
import torch
from utils import tokenlize
from lib import ws,max_len,test_batch_size,train_batch_size
#准备数据集
class ImdbDataset(Dataset):
def __init__(self,train = True):
#设置训练路径和测试路径
self.train_data_path = r'F:\\Learn_pytorch\\aclImdb\\train'
self.test_data_path = r'F:\\Learn_pytorch\\aclImdb\\test'
data_path = self.train_data_path if train else self.test_data_path
#把所有的文件名放入列表
temp_data_path = [os.path.join(data_path,'pos'),os.path.join(data_path,'neg')]
self.total_file_path = []
for path in temp_data_path:
#以列表的形式加载路径
file_name_list = os.listdir(path)
#过滤文件,只有后缀是.txt的文件才符合
file_path_list = [os.path.join(path,i) for i in file_name_list if i.endswith('.txt')]
#保存所有的文件路径
self.to以上是关于Pytorch实现文本情感分类流程的主要内容,如果未能解决你的问题,请参考以下文章