数据结构与算法之深入解析“不同的二叉搜索树II”的求解思路与算法示例
Posted Forever_wj
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据结构与算法之深入解析“不同的二叉搜索树II”的求解思路与算法示例相关的知识,希望对你有一定的参考价值。
一、题目要求
- 给你一个整数 n ,请你生成并返回所有由 n 个节点组成且节点值从 1 到 n 互不相同的不同二叉搜索树,可以按 任意顺序 返回答案。
- 示例 1:
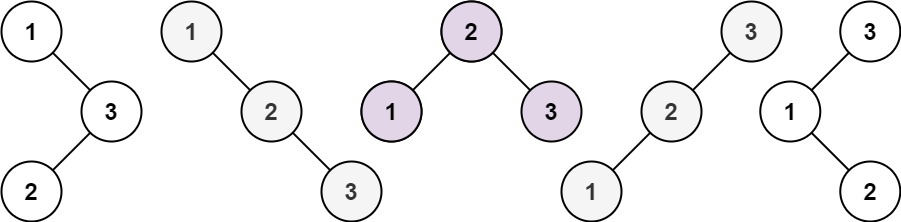
输入:n = 3
输出:[[1,null,2,null,3],[1,null,3,2],[2,1,3],[3,1,null,null,2],[3,2,null,1]]
- 示例 2:
输入:n = 1
输出:[[1]]
二、求解算法
① 递归
- 可以利用一下查找二叉树的性质:左子树的所有值小于根节点,右子树的所有值大于根节点,所以如果求 1…n 的所有可能。
- 只需要把 1 作为根节点,[ ] 空作为左子树,[ 2 … n ] 的所有可能作为右子树;
- 2 作为根节点,[ 1 ] 作为左子树,[ 3…n ] 的所有可能作为右子树;
- 3 作为根节点,[ 1 2 ] 的所有可能作为左子树,[ 4 … n ] 的所有可能作为右子树,然后左子树和右子树两两组合;
- 4 作为根节点,[ 1 2 3 ] 的所有可能作为左子树,[ 5 … n ] 的所有可能作为右子树,然后左子树和右子树两两组合…
- n 作为根节点,[ 1… n ] 的所有可能作为左子树,[ ] 作为右子树。
- 至于,[ 2 … n ] 的所有可能以及 [ 4 … n ] 以及其他情况的所有可能,可以利用上边的方法,把每个数字作为根节点,然后把所有可能的左子树和右子树组合起来即可。
- 如果只有一个数字,那么所有可能就是一种情况,把该数字作为一棵树。而如果是 [ ],那就返回 null。
- Java 示例:
public List<TreeNode> generateTrees(int n)
List<TreeNode> ans = new ArrayList<TreeNode>();
if (n == 0)
return ans;
return getAns(1, n);
private List<TreeNode> getAns(int start, int end)
List<TreeNode> ans = new ArrayList<TreeNode>();
// 此时没有数字,将 null 加入结果中
if (start > end)
ans.add(null);
return ans;
// 只有一个数字,当前数字作为一棵树加入结果中
if (start == end)
TreeNode tree = new TreeNode(start);
ans.add(tree);
return ans;
// 尝试每个数字作为根节点
for (int i = start; i <= end; i++)
// 得到所有可能的左子树
List<TreeNode> leftTrees = getAns(start, i - 1);
// 得到所有可能的右子树
List<TreeNode> rightTrees = getAns(i + 1, end);
// 左子树右子树两两组合
for (TreeNode leftTree : leftTrees)
for (TreeNode rightTree : rightTrees)
TreeNode root = new TreeNode(i);
root.left = leftTree;
root.right = rightTree;
// 加入到最终结果中
ans.add(root);
return ans;
② 动态规划 1
- 大多数递归都可以用动态规划的思想重写,举个例子,n = 3:
数字个数是 0 的所有解
null
数字个数是 1 的所有解
1
2
3
数字个数是 2 的所有解,我们只需要考虑连续数字
[ 1 2 ]
1
\\
2
2
/
1
[ 2 3 ]
2
\\
3
3
/
2
如果求 3 个数字的所有情况。
[ 1 2 3 ]
利用解法①递归的思路,就是分别把每个数字作为根节点,然后考虑左子树和右子树的可能
1 作为根节点,左子树是 [] 的所有可能,右子树是 [ 2 3 ] 的所有可能,利用之前求出的结果进行组合。
1
/ \\
null 2
\\
3
1
/ \\
null 3
/
2
2 作为根节点,左子树是 [ 1 ] 的所有可能,右子树是 [ 3 ] 的所有可能,利用之前求出的结果进行组合。
2
/ \\
1 3
3 作为根节点,左子树是 [ 1 2 ] 的所有可能,右子树是 [] 的所有可能,利用之前求出的结果进行组合。
3
/ \\
1 null
\\
2
3
/ \\
2 null
/
1
- 然后利用上边的思路基本上可以写代码了,就是求出长度为 1 的所有可能,长度为 2 的所有可能 … 直到 n。但是注意到,求长度为 2 的所有可能的时候,我们需要求 [ 1 2 ] 的所有可能,[ 2 3 ] 的所有可能,这只是 n = 3 的情况。如果 n 等于 100,我们需要求的更多了 [ 1 2 ] , [ 2 3 ] , [ 3 4 ] … [ 99 100 ] 太多了,那么能不能优化呢?
- 仔细观察,可以发现长度是为 2 的所有可能其实只有两种结构:
x
/
y
y
\\
x
- 看之前推导的 [ 1 2 ] 和 [ 2 3 ],只是数字不一样,结构是完全一样的:
[ 1 2 ]
1
\\
2
2
/
1
[ 2 3 ]
2
\\
3
3
/
2
- 所以 n = 100 的时候,求长度是 2 的所有情况的时候,没必要把 [ 1 2 ] , [ 2 3 ] , [ 3 4 ] … [ 99 100 ] 所有的情况都求出来,只需要求出 [ 1 2 ] 的所有情况即可。
- 推广到任意长度 len,其实只需要求 [ 1 2 … len ] 的所有情况就可以了。下一个问题随之而来,这些 [ 2 3 ] , [ 3 4 ] … [ 99 100 ] 没求的怎么办呢?
- 举个例子:n = 100,此时我们求把 98 作为根节点的所有情况,根据之前的推导,需要长度是 97 的 [ 1 2 … 97 ] 的所有情况作为左子树,长度是 2 的 [ 99 100 ] 的所有情况作为右子树。
- [ 1 2 … 97 ] 的所有情况刚好是 [ 1 2 … len ] ,已经求出来了。但 [ 99 100 ] 怎么办呢?我们只求了 [ 1 2 ] 的所有情况,答案很明显了,在 [ 1 2 ] 的所有情况每个数字加一个偏差 98,即加上根节点的值就可以了。
[ 1 2 ]
1
\\
2
2
/
1
[ 99 100 ]
1 + 98
\\
2 + 98
2 + 98
/
1 + 98
即
99
\\
100
100
/
99
- 所以需要一个函数,实现树的复制并且加上偏差:
private TreeNode clone(TreeNode n, int offset)
if (n == null)
return null;
TreeNode node = new TreeNode(n.val + offset);
node.left = clone(n.left, offset);
node.right = clone(n.right, offset);
return node;
- 通过上边的所有分析,代码可以写了,总体思想就是求长度为 2 的所有情况,求长度为 3 的所有情况直到 n。而求长度为 len 的所有情况,只需要求出一个代表 [ 1 2 … len ] 的所有情况,其他的话加上一个偏差,加上当前根节点即可:
public List<TreeNode> generateTrees(int n)
ArrayList<TreeNode>[] dp = new ArrayList[n + 1];
dp[0] = new ArrayList<TreeNode>();
if (n == 0)
return dp[0];
dp[0].add(null);
// 长度为 1 到 n
for (int len = 1; len <= n; len++)
dp[len] = new ArrayList<TreeNode>();
// 将不同的数字作为根节点,只需要考虑到 len
for (int root = 1; root <= len; root++)
int left = root - 1; // 左子树的长度
int right = len - root; // 右子树的长度
for (TreeNode leftTree : dp[left])
for (TreeNode rightTree : dp[right])
TreeNode treeRoot = new TreeNode(root);
treeRoot.left = leftTree;
// 克隆右子树并且加上偏差
treeRoot.right = clone(rightTree, root);
dp[len].add(treeRoot);
return dp[n];
private TreeNode clone(TreeNode n, int offset)
if (n == null)
return null;
TreeNode node = new TreeNode(n.val + offset);
node.left = clone(n.left, offset);
node.right = clone(n.right, offset);
return node;
- 值得注意的是,所有的左子树我们没有 clone ,也就是很多子树被共享了,在内存中就会是下边的样子:

- 也就是左子树用的都是之前的子树,没有开辟新的空间。
③ 动态规划 2
- 解法 ② 的动态规划 1 完全是模仿了解法二递归的思想,再分享一种动态规划的思想:
考虑 [] 的所有解
null
考虑 [ 1 ] 的所有解
1
考虑 [ 1 2 ] 的所有解
2
/
1
1
\\
2
考虑 [ 1 2 3 ] 的所有解
3
/
2
/
1
2
/ \\
1 3
3
/
1
\\
2
1
\\
3
/
2
1
\\
2
\\
3
- 仔细分析,可以发现一个规律。首先我们每次新增加的数字大于之前的所有数字,所以新增加的数字出现的位置只可能是根节点或者是根节点的右孩子,右孩子的右孩子,右孩子的右孩子的右孩子等等,总之一定是右边。其次,新数字所在位置原来的子树,改为当前插入数字的左孩子即可,因为插入数字是最大的。
对于下边的解
2
/
1
然后增加 3
1.把 3 放到根节点
3
/
2
/
1
2. 把 3 放到根节点的右孩子
2
/ \\
1 3
对于下边的解
1
\\
2
然后增加 3
1.把 3 放到根节点
3
/
1
\\
2
2. 把 3 放到根节点的右孩子,原来的子树作为 3 的左孩子
1
\\
3
/
2
3. 把 3 放到根节点的右孩子的右孩子
1
\\
2
\\
3
- 以上就是根据 [ 1 2 ] 推出 [ 1 2 3 ] 的所有过程,可以写出示例代码了,由于求当前的所有解只需要上一次的解,所有只需要两个 list,pre 保存上一次的所有解, cur 计算当前的所有解:
public List<TreeNode> generateTrees(int n)
List<TreeNode> pre = new ArrayList<TreeNode>();
if (n == 0)
return pre;
pre.add(null);
// 每次增加一个数字
for (int i = 1; i <= n; i++)
List<TreeNode> cur = new ArrayList<TreeNode>();
// 遍历之前的所有解
for (TreeNode root : pre)
// 插入到根节点
TreeNode insert = new TreeNode(i);
insert.left = root;
cur.add(insert);
// 插入到右孩子,右孩子的右孩子...最多找 n 次孩子
for (int j = 0; j <= n; j++)
TreeNode root_copy = treeCopy(root); // 复制当前的树
TreeNode right = root_copy; // 找到要插入右孩子的位置
int k = 0;
// 遍历 j 次找右孩子
for (; k < j; k++)
if (right == null)
break;
right = right.right;
// 到达 null 提前结束
if (right == null)
break;
// 保存当前右孩子的位置的子树作为插入节点的左孩子
TreeNode rightTree = right.right;
insert = new TreeNode(i);
right.right = insert; // 右孩子是插入的节点
insert.left = rightTree; //插入节点的左孩子更新为插入位置之前的子树
//加入结果中
cur.add(root_copy);
pre = cur;
return pre;
private TreeNode treeCopy(TreeNode root)
if (root == null)
return root;
TreeNode newRoot = new TreeNode(root.val);
newRoot.left = treeCopy(root.left);
newRoot.right = treeCopy(root.right);
return newRoot;
④ 回溯法(LeetCode 官方解法)
- 二叉搜索树关键的性质是根节点的值大于左子树所有节点的值,小于右子树所有节点的值,且左子树和右子树也同样为二叉搜索树。因此在生成所有可行的二叉搜索树的时候,假设当前序列长度为 n,如果我们枚举根节点的值为 i,那么根据二叉搜索树的性质我们可以知道左子树的节点值的集合为 [1…i−1],右子树的节点值的集合为 [i+1…n],而左子树和右子树的生成相较于原问题是一个序列长度缩小的子问题,因此可以想到用回溯的方法来解决这道题目。
- 定义 generateTrees(start, end) 函数表示当前值的集合为 [start,end],返回序列 [start,end] 生成的所有可行的二叉搜索树。按照上文的思路,考虑枚举 [start,end] 中的值 i 为当前二叉搜索树的根,那么序列划分为了 [start,i−1] 和 [i+1,end] 两部分。我们递归调用这两部分,即 generateTrees(start, i - 1) 和 generateTrees(i + 1, end),获得所有可行的左子树和可行的右子树,那么最后一步我们只要从可行左子树集合中选一棵,再从可行右子树集合中选一棵拼接到根节点上,并将生成的二叉搜索树放入答案数组即可。
- 递归的入口即为 generateTrees(1, n),出口为当 start>end 的时候,当前二叉搜索树为空,返回空节点即可。
- Java 示例:
class Solution
public List<TreeNode> generateTrees(int n)
if (n == 0)
return new LinkedList<TreeNode>();
return generateTrees(1, n);
public List<TreeNode> generateTrees(int start, int end)
List<TreeNode> allTrees = new LinkedList<TreeNode>();
if (start > end)
allTrees.add(null);
return allTrees;
// 枚举可行根节点
for (int i = start; i <= end; i++)
// 获得所有可行的左子树集合
List<TreeNode> leftTrees = generateTrees(start, i - 1);
// 获得所有可行的右子树集合
List<TreeNode> rightTrees = generateTrees(i + 1, end);
// 从左子树集合中选出一棵左子树,从右子树集合中选出一棵右子树,拼接到根节点上
for (TreeNode left : leftTrees)
for (TreeNode right : rightTrees)
TreeNode currTree = new TreeNode(i);
currTree.left = left;
currTree.right = right;
allTrees.add(currTree);
return allTrees;
三、博客之星助力
- 今年是我第一次参加博客之星,需要各位大佬的支持,麻烦百忙之中,抽出一点宝贵的时间,给我投一下票:https://bbs.csdn.net/topics/603955258 给我一个五星(列表会一一全部回复),不胜感激!
以上是关于数据结构与算法之深入解析“不同的二叉搜索树II”的求解思路与算法示例的主要内容,如果未能解决你的问题,请参考以下文章