交易系统开发技能及面试之低延迟编程技术
Posted BBinChina
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了交易系统开发技能及面试之低延迟编程技术相关的知识,希望对你有一定的参考价值。
概要
关于低延迟相关技术,需要我们掌握cpu cache工作原理、kernel bypass、非阻塞编程、编译优化、硬件优化( CPU pipelines,FPGA)、软件优化(高效算法和数据结构)
CPU Caches
Cacheline(缓存行):内存与缓存的交互总是以cachelline大小进行拷贝。比如:cpu传输一个整型变量时(4或8字节),采用的是一个cacheline大小(主流cpu是64字节)进行传输,可以理解cacheline为最小缓存单位。
缓存的类型:指令缓存(程序指令),数据缓存(程序数据),虚拟内存与物理内存的映射缓存。
缓存等级:cpu寄存器 -> L1缓存 -> L2 缓存 -> L3缓存 -> 主存, 越靠近cpu寄存器的位置速度越快。
缓存一致性:对在不同的缓存和主存之间的数据一致性处理。
时间局部性 Temporal Locality:指最近使用的数据更有可能再被使用。
空间局部性 Spatial Locality:如果内存中某个位置的数据正在被cpu所使用,那么靠近这个内存位置的内存数据很可能在不久的将来被引用。
缓存预热 :当数据第一次被cpu引用时,数据被从主存放置到缓存中。缓存预热是为了增加缓存命中,而预测即将使用的数据并把其加载到缓存中。
**CPU 绑定,pinning **: 指将进程和某个或者某几个 CPU 关联绑定,绑定后的进程只能在所关联的 CPU 上运行,可提高缓存命中率。
Q1 分析代码段性能
分别采用行、列访问数据的方式:
// row major order
std::vector<double> v(n * n);
double sum0.0;
for (std::size_t i = 0; i < n; i++)
for (std::size_t j = 0; j < n ; j++)
sum += v[i * n + j];
// column major order
std::vector<double> v(n * n);
double sum0.0;
for (std::size_t j = 0; j < n; j++)
for (std::size_t i = 0; i < n ; i++)
sum += v[i * n + j];
根据空间局部性和Cacheline,采用行式访问数据性能更好,因为cpu读取数据时采用cacheline大小将内存空间上线性数据加载到缓存中。即采用行方式遍历数据时,下一个数据已在Cache中,提高了Cache的命中率。
Q2 采用alignas进行性能优化
观察以下代码:
struct Data
char c;
char d;
;
Data data;
void thread1_func()
int sum = 0;
for (int i = 0; i < 100000000; ++i)
sum += data.c;
void thread2_func()
int sum = 0;
for (int i = 0; i < 100000000; ++i)
data.d = i % 256;
采用两个线程并发执行以上两个函数,因为Data结构的c\\d都是1个字节,而cacheline普遍为64个字节,所以当执行data.d的更新时,cpu会采用cacheline大小更新缓存到主存的数据,导致data.c无法命中缓存。因为data.d需要更新,那么我们可以设置缓存只更新data.d大小(1个字节),所以可以使用alignas制定内存对齐大小。
struct alignas(1) Data
char c;
char d;
;
Q3 缩小锁粒度
long long sum = 0;
void sumUp()
long long tmp = 0;
for (int i = 0; i < 10000; ++i)
tmp += 1;
std::lock_guard<std::mutex> lockGuard(myMutex);
sum += tmp;
当有多个线程对全局变量sum进行操作时,可以在对sum进行操作时才进行锁,而sum的累计先采用本地变量tmp进行计算后才更新sum变量。
kernel bypass
Kernel bypass是一种绕过OS与网络栈或者其他硬件进行数据交互的技术,通过减少用户态与内核态的数据拷贝(也叫零拷贝zero-copy)来提升性能。
非阻塞编程
通常将的NIO方式,比如sockets 或者 设计一套异步事件响应系统,在生产中常用Actor模型。
这一块的知识在前篇系列文章都有讲到过。
编程技巧
1、 避免动态内存分配
采用内存池(对象池),减少内存的分配释放以及内存碎片的产生。
2、 采用位运算替换数值运算
比如 n/2 可以采用 n >> 1的方式性能更高。
3、利用cacheline,让即将使用到的数据更紧凑的在同一个cacheline大小范围内,提高cache命中率。
4、交易系统场景里需要使用到浮点数值来表示数据,比如股票价格10.01,而优化的方式是使用整型:1010(price),小数点位为 2(factor)这种形式。
5、因为cacheline预加载cache,当数据量少时,采用线性查找比二分查找性能更好
6、
编译优化
采用__builtin_expect做分支预测。它是gcc编译器引入的一个指令,允许程序员将代码中最有可能执行的分支告诉编译器。具体的写法
__builtin_expect(EXP,N) // 其中EXP可以为变量,也可以为表达式
意思是,EXP==n的概率很大。
//预测x更大几率为false
if (__builtin_expect(x, 0))
foo();
...
else
bar();
...
以上代码生成汇编:
cmp $x,0
jne _foo
_bar:
call bar
...
jmp after_if
_foo:
call foo
...
after_if:
简化版的cpu流水线(cpu pipeline)
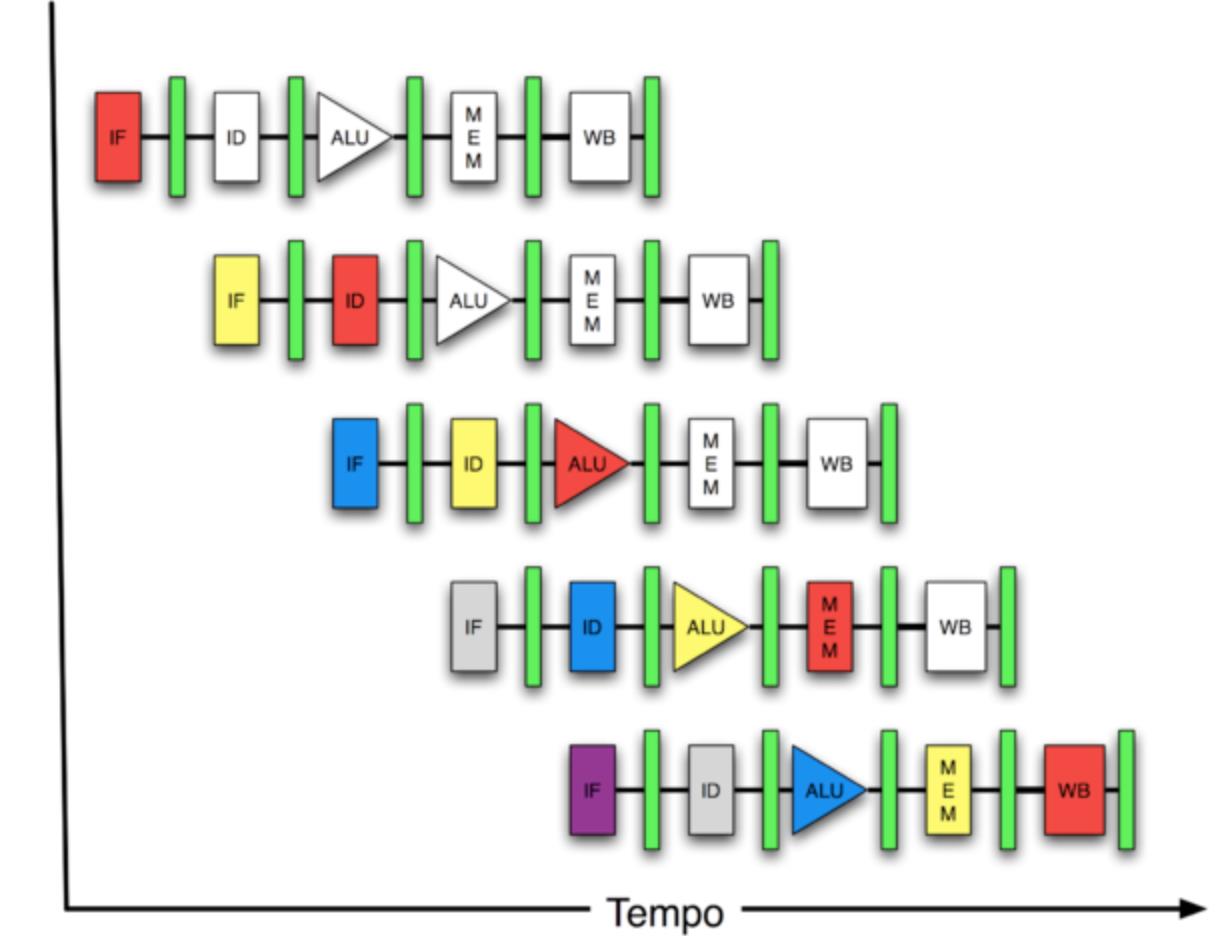
分支预测器位于整个CPU核心流水线的差不多最前端部分,靠近IF的级。从指令缓存里面读取指令时,需要由分支预测器来判断从哪里读取。
所以采用分支预测实际上是优化了分支预测期的缓存。
Q4 分析性能
随机初始化数组值,然后统计随机数中大于等于128的值
const unsigned arraySize = 32768;
int data[arraySize];
for (unsigned c = 0; c < arraySize; ++c)
data[c] = std::rand() % 256;
clock_t start = clock();
long long sum = 0;
for (unsigned i = 0; i < 100000; ++i)
//primary loop
for (unsigned c = 0; c < arraySize; ++c)
if (data[c] >= 128)
sum += data[c];
double elapsedTime = static_cast<double>(clock() - start) / CLOCKS_PER_SEC;
std::cout << elapsedTime << endl;//17.979
初始化完数值后,先进行排序,再统计大于等于128的值
const unsigned arraySize = 32768;
int data[arraySize];
for (unsigned c = 0; c < arraySize; ++c)
data[c] = std::rand() % 256;
//先进行排序
std::sort(data, data + arraySize);
clock_t start = clock();
long long sum = 0;
for (unsigned i = 0; i < 100000; ++i)
//primary loop
for (unsigned c = 0; c < arraySize; ++c)
if (data[c] >= 128)
sum += data[c];
double elapsedTime = static_cast<double>(clock() - start) / CLOCKS_PER_SEC;
std::cout << elapsedTime << endl; //5.909
排序后的执行性能提升了至少3倍,而且你使用vscode2019的诊断工具时,可以看到cpu有个跃式的进度跳动。
排序后的性能高是因为现代cpu都采用了长流水线工作方式,也即是前文讲到的cpu pipeline,在执行指令时会采用分支预测方式,在统计数值时:
if (data[c] >= 128)
sum += data[c];
而如果没有排序的话,分支预测的错误性更高且随机,那么指令缓存毫无意义,排序后使分支预测为常态。
漫谈
如果是高频交易系统的话,最好采用集中式服务,比如让数据、计算都在一个进程,让数据跟计算更紧凑,而不是采用当前的互联网微服务开发思维。
还有就是当前越来越重要的FPGA矩阵编程,可以饶过CPU在FPGA上进行市场数据分析
以上是关于交易系统开发技能及面试之低延迟编程技术的主要内容,如果未能解决你的问题,请参考以下文章