Linux文本处理三剑客之一——awk详解——awk看这两篇就够啦~PS:文末有练习,来练练手吧
Posted xiaoxie_coding
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux文本处理三剑客之一——awk详解——awk看这两篇就够啦~PS:文末有练习,来练练手吧相关的知识,希望对你有一定的参考价值。
目录
awk流程控制语句
1.条件判断语句
单分支
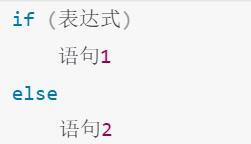
# if(condition) statement1
awk -F: 'if($3>500)print $1;$7' /etc/passwd
# if(condition) statement1 ; else statement2
awk -F: 'if($3>500)print $1;else print$3' /etc/passwdawk分支结构允许嵌套,大致格式如下:


每条命令语句后面使用分号;结尾
awk -F: 'if($1=="root")print $1;else if($1=="ftp")print $2;else if($1=="mail")print $3;else print NR' /etc/passwd
cat /etc/passwd |awk -F: 'BEGINnum1=0;num2=0 if (length($2)<=2) print $1;num1++ else num2++;print $1ENDprint "有"num1"个用户没有设置密码,有"num2"个用户设置了密码"'2.循环语句
while语句
 示例如下:
示例如下:
awk 'BEGIN
total=100;x=0;
while(i<=total)
x+=i;
i++;
print x;
'
5050
for循环

代码示例如下:
# 定义数组,for循环取出数组里的值
awk -F: 'BEGINa[0]a[$3]=$1ENDfor (i in a) print a[i] ' /etc/passwd
# 利用for的条件循环
awk 'BEGIN for (i = 1; i <= 10; i++) print i '
do...while语句
 代码示例如下
代码示例如下
awk 'BEGIN
total=0;i=0;
do total+=i;i++; while(i<=100)
print total;
'
5050
3.其他语句
- break 一般用于 while 或 for 语句,退出程序循环。
- continue continue 语句用于 while 或 for 语句,在循环体内部结束本次循环,从而直接进入下一次循环迭代。
- exit
[root@kafka01 ~]# cat /etc/passwd|awk -F: 'print $1;print$2;exit;print $3'
root
x
[root@kafka01 ~]# cat /etc/passwd|awk -F: 'BEGINprint "start";exit;NR==1print $0ENDprint "end"'
start
end
因为跳出了awk命令,所以后面的 print 语句不再执行.当 awk 语句中有 “exit” 和 “ENDcommands 语句块” 的时候,exit 并不是表示退出awk命令;而是表示直接执行 ENDcommands 语句块中的内容。
-
next 读取下一条记录;awk循环逐行匹配时,如果遇到next,就会跳过当前行,直接忽略下面语句进行下一行匹配。如果我们有一行内容不需要 awk 处理,那么我们就可以使用 “next” 来告诉 awk 哪一行内容不需要处理
# 当行号除以2余1,就跳过当前行。
[root@kafka01 1-6awk]# cat url.txt |awk 'NR%2==1nextprint NR,$0'
2 http://www.sina.com
4 http://www.12306.cn
6 feng@qq.com
8 meng.xianhui@yahoo.cn
10 10001@qq.com
awk数组
首先我们介绍一下数组
数组语法格式
array_name[index]=value
- array_name:数组的名称
- index:数组索引
- value:数组中元素所赋予的值
数字和字符串都可以做数组的索引(下标)
for循环读取数组的值
awk -F: 'BEGINa[0]a[$3]=$1ENDfor (i in a) print a[i] ' /etc/passwdBEGINa[0]定义一个数组a, a[0]是数组初始化的操作
a[$3]=$1把uid做key,用户名做value
for (i in a) print a[i] 使用for循环取出a数组里的key,然后输出对应的value, i对应a数组里的key
for…in循环输出时候,默认打印出来是无序数组。
cat number.txt
81 90
62 30
43 85
34 53
15 77
# 默认打印出来的是无序数组
awk 'a[$1]=$2ENDfor (i in a) print i,a[i]' number.txt
15 77
34 53
43 85
62 30
81 90
数组相关函数
1.length 统计数组的长度
awk -F: 'BEGINa[0]a[$3]=$1ENDfor (i in a) print a[i];print length(a) ' /etc/passwd
length返回字符串以及数组长度,split分割字符串info,动态创建数组A,返回值也是数组长度。
awk 'BEGINinfo="it is a test";lens=split(info,A," ");print length(A),lens,A[2];'
4 4 is
2. 排序函数
asort 对 value 排序,返回数组元素的个数,排序后,数组下标改为从1到数组的长度。
asorti 对 key 排序,返回数组元素的个数。
对上面的例子,我们对它分别使用asort和asorti排序:
asort排序
awk 'a[$1]=$2ENDt=asort(a,b);for (i=1;i<=t;i++) print i"\\t"a[i]"\\t"b[i]' number.txt
1 30
2 53
3 77
4 85
5 90
END语句中 asort 对数组a的值进行排序,把排序后的下标存入新生成的数组b中,丢弃数组a下标值,再返回数组a的长度,将其赋值给变量t。
b[1]=30
b[2]=53
b[3]=77
b[4]=85
b[5]=90
a 数组原封未动,b数组首先拷贝自 a 数组,然后在 b 数组上排序。
例子中无法输出 a 数组的原因是,a 的索引为与传入的 1,2,3,4,5 不匹配,故没有内容输出
数组的值是无法直接输出的,如果想要得到排序的结果,则必需使用 for(i=1;i<length;i++) 的形式,因为 for(i in a) 的形式不能有序输出结果。
asorti排序
awk 'a[$1]=$2ENDt=asorti(a,b);for (i=1;i<=t;i++) print i,b[i],a[b[i]]' number.txt
1 15 77
2 34 53
3 43 85
4 62 30
5 81 90
b[1]=15
b[2]=34
b[3]=43
b[4]=62
b[5]=81 b[i]中存的是索引值
END中 asorti 对数组a的下标进行排序,并把排序后的下标存入新生成的数组b中,并把数组a的长度赋值给变量t。asorti(a,b),得到排序后的索引,再将其代入未改变的 a,即a[b[i]],则可以得到索引对应的值。
多维数组
awk在存储上并不支持多维数组,不过我们可以很容易地使用一维数组模拟实现多维数组,awk提供了逻辑上模拟二维数组的方式,比如,array[0,0]这样的方式是允许的
如下示例为一个 3x3 的二维数组:
100 200 300 400 500 600 700 800 900
以上实例中,array[0][0] 存储 100,array[0][1] 存储 200 ,依次类推。为了在 array[0][0] 处存储 100, 我们可以使用如下语法: array["0,0"] = 100。
我们使用了 0,0 作为索引,但是这并不是两个索引值,而是一个字符串索引 0,0
# 定义多维数组
awk 'BEGIN
array["0,0"] = 100;
array["0,1"] = 200;
array["0,2"] = 300;
array["1,0"] = 400;
array["1,1"] = 500;
array["1,2"] = 600;
# 输出数组元素
print "array[0,0] = " array["0,0"];
print "array[0,1] = " array["0,1"];
print "array[0,2] = " array["0,2"];
print "array[1,0] = " array["1,0"];
print "array[1,1] = " array["1,1"];
print "array[1,2] = " array["1,2"];
'数组的相关应用
1.某一列有重复的值,而对应的另一列内容不一样,想实现一个累加功能,如:计算以下每个学生的总分(chinese+math的成绩),输出以下格式
cat student.txt
name course grade
rose chinese 80
jack math 90
rose math 89
jack chinese 99
tom chinese 60
tom math 83
jons math 82
# 输出以下格式(名字输出顺序随意)
rose 169
jack 189
tom 143
jons 82
# 答案
cat student.txt | awk 'NR>1name[$1]+=$3ENDfor (i in name) print i,name[i]'
2.多维数组实现九九乘法
awk 'BEGIN
for(i=1;i<=9;i++)
for(j=1;j<=9;j++)
x[i,j]=i*j; print i,"*",j,"=",x[i,j];
'awk内置函数
挑几个自己常用的来写一下,具体大家可以 man awk 有许多内置函数
1.length 计算字符数目的函数 可以直接计算出字符串的数目很方便
# 检查有无空口令用户
awk -F: 'length($2)<3 print $1' /etc/shadow
# 上次我们说过密码字段为*、!!表示没有设置密码
# 显示文件中超过60个字符的行
awk 'length($0)>60 print NR,$0' /etc/passwd
2.system函数 执行shell命令
批量创建和删除文件、用户等很方便
[root@kafka01 ~]# cat list
xixi 123
haha 456
hehe 789
[root@kafka01 ~]# awk 'system("useradd "$1)' list
[root@kafka01 ~]# ls /home
haha hehe hello xixi
[root@kafka01 ~]# awk 'system("userdel -r "$1)' list
[root@kafka01 ~]# ls /home
hello
# 思考如何利用system函数给上述用户配置密码3.substr 截取字符串 可以指定截取位置的字符串
# 切片第一个字母到第三个
cat /etc/passwd|awk -F: 'print substr($1,1,3)' awk还内置了算数函数、字符串函数和时间函数等,还有很多有意思的函数等你去探索!
练习
1.求出3个人累计消费的金额,按照金额的大小排降序
[root@kafka01 0426test]# cat money.txt
username money
feng 100
feng 200
feng 350
li 200
li 239
li 890
zhang 100
zhang 350
# 答案
[root@kafka01 0426test]# awk 'NR>1 a[$1]+=$2ENDfor (i in a) print i,a[i]' money.txt |sort -k 2
li 1329
feng 650
zhang 450
2.利用awk的if多分支判断用户的类型,uid为0显示为"管理员",如果是uid在1~999之间,为"程序用户",uid大于等于1000,为'普通用户",并统计他们的数量,最后输出时,格式如下:
xxx 是 xxx;xxx 是 xxx;xxx 是 xxx.....
管理员有x个;程序用户有x个;普通用户有x个;总共有x个用户 或输出
管理员有:xxx,... 数量有: ,程序用户有:xxx... 数量有: ,普通用户有:xxx... 数量有:

cat /etc/passwd|awk -F: 'BEGINa=0;b=0;c=0if ($3==0)print $1"是管理员";a++else if ($3>1 && $3<=999)print $1"是程序用户";b++else print $1"是普通用户";c++ENDprint "总共有",a+b+c,"个用户"' 用数组的方式来写:
# 利用数组
# 将三种类别分为三个组 value存储的是三种类别的用户名 然后利用字符串拼接起来
awk -F: 'BEGINsuper=0;admin=0;user=0;admin1="";user1=""
if($3==0)super=super+1;A[super]=$1
else if($3>0&&$3<=999)admin=admin+1;B[admin]=$1
else user=user+1;C[user]=$1
END
for (k in A)print "管理员有",A[k],"数量是",super;
for (k in B)admin1=admin1 " " B[k];print "程序用户有",admin1,"数量是",admin;
for (k in C)user1=user1 " " C[k];print "普通用户有",user1,"数量是",user;
print "总共有",admin+super+user,"个用户"' /etc/passwd
直接用字符串拼接不使用数组
awk -F: 'BEGINsuper=0;admin=0;user=0;a="";b="";c=""
if ($3==0)super++;a=a" "$1
else if($3>0 && $3<1000)admin++;b=b" "$1
else user++;c=c" "$1;
ENDprint "管理员有:",a,"数量为:",super,
"\\n程序用户有:",b,"数量为:",admin,
"\\n普通用户有:",c,"数量为:",user,
"\\n总共有",super+admin+user"个用户"' /etc/passwd
3.利用awk的system命令在/tmp下建立和删除/etc/passwd中与用户名同名的目录
awk -F: 'system("mkdir /tmp/"$1)' /etc/passwd
awk -F: 'system("rm -rf /tmp/"$1)' /etc/passwd
4.awk进行行求和
echo 1 2 3 4 5|awk 'for (i=1;i<=NF;i++) sum+=$i;print sum'
15
seq -s ' ' 100 | awk 'for(i=1;i<=NF;i++) sum+=$i; print sum'
5050
其他类似于:统计出ftp下载量最大的5个ip地址累计下载的总大小(以M为单位);进行下载流量排序;统计每个URL的每分钟的频率等常见面试题其实都是要用到数组的,要熟练使用
awk系列就到这里了,经过这两天的学习我了解到awk是一个很强大的命令,我们所知道的只是它的一小部分,但单单一小部分就够我们使用了,其实Linux中每一个命令都很强大,都值得我们去认真学习!所以,一起加油吧!
PS:文章要有写的不太对的地方欢迎评论私信我一起交流呀!
以上是关于Linux文本处理三剑客之一——awk详解——awk看这两篇就够啦~PS:文末有练习,来练练手吧的主要内容,如果未能解决你的问题,请参考以下文章