MongoDB学习笔记总结(含报错问题技巧)
Posted X胖胖虎
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MongoDB学习笔记总结(含报错问题技巧)相关的知识,希望对你有一定的参考价值。
环境
OS:Ubuntu20.04
MongoDB:v5.0.2
一.MongoDB简介
MongoDB是一个开源文档数据库,提供高性能,高可用性和自动扩展,旨在为WEB应用提供可扩展的高性能数据存储解决方案。
MongoDB 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。
文档的数据结构和JSON基本一样。所有存储在集合中的数据都是BSON格式。
MongoDB中的记录是一个文档,它是由字段和值(key=>value)对组成的数据结构。 MongoDB文档与JSON对象相似。 字段的值可能包括其他文档,数组和文档数组。
在mongodb中基本的概念是文档(document)、集合(collection)、数据库(database)。
| SQL术语/概念 | MongoDB术语/概念 | 解释/说明 |
|---|---|---|
| database | database | 数据库 |
| table | collection | 数据库表/集合 |
| row | document | 数据记录行/文档 |
| column | Field | 数据字段/域 |
| index | Index | 索引 |
| table joins | 表连接,MongoDB不支持 | |
| primary key | primary key | 主键,MongoDB自动将_id字段设置为主键 |
二.ubuntu安装MongoDB 5.0
1.导入MongoDB公共GPG Key(推荐去官网(官网地址:https://www.mongodb.com/)看最新的GPG Key)
wget -qO - https://www.mongodb.org/static/pgp/server-5.0.asc | sudo apt-key add -

返回OK即操作成功,如果提示gnupg 未安装则先安装gnupg
sudo apt-get install gnupg
2.创建/etc/apt/sources.list.d/mongodb-org-5.0.list文件
不同ubuntu系统版本通过不同命令创建,可以查看当前ubuntu系统的版本:
lsb_release -dc
ubuntu20
echo "deb [ arch=amd64,arm64 ] https://repo.mongodb.org/apt/ubuntu focal/mongodb-org/5.0 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-5.0.list
3.更新apt-get
sudo apt-get update
4.安装MongoDB
安装指定版本(可去官网看最新的稳定版本并做安装):
sudo apt-get install -y mongodb-org=5.0.2 mongodb-org-database=5.0.2 mongodb-org-server=5.0.2 mongodb-org-shell=5.0.2 mongodb-org-mongos=5.0.2 mongodb-org-tools=5.0.2
安装最新版本(可能会下载到较老的版本,因为ubuntu源无更新的原因):
sudo apt-get install -y mongodb-org
查看MongoDB版本:首先切换到mongodb安装目录下–>输入命令:
./mongo --version
5.禁用自动升级,防止意外情况
echo "mongodb-org hold" | sudo dpkg --set-selections
echo "mongodb-org-database hold" | sudo dpkg --set-selections
echo "mongodb-org-server hold" | sudo dpkg --set-selections
echo "mongodb-org-shell hold" | sudo dpkg --set-selections
echo "mongodb-org-mongos hold" | sudo dpkg --set-selections
echo "mongodb-org-tools hold" | sudo dpkg --set-selections
6.启动运行
安装后会默认创建数据目录和日志目录如下:
默认数据目录:/var/lib/mongodb,默认日志目录:/var/log/mongodb
可以通过修改配置文件把数据和日志保存到其他目录(修改后需重启mongodb生效):
vim /etc/mongod.conf
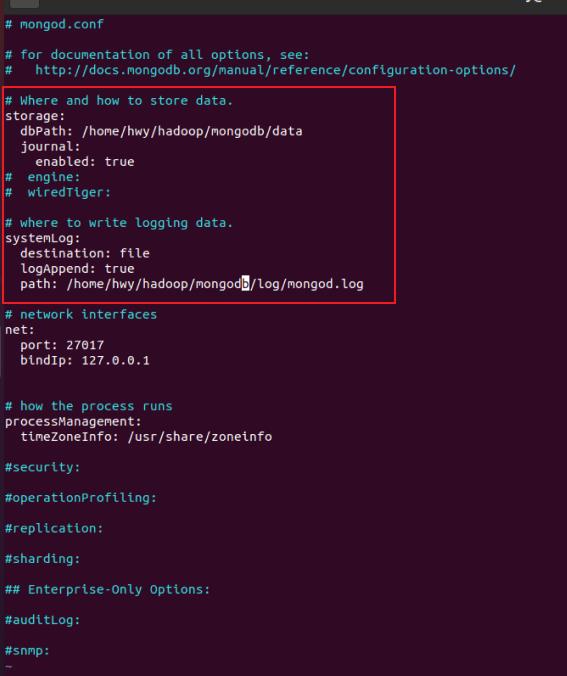
mongodb默认是以mongodb这个用户运行的,如果修改了数据和日志目录需要创建对应的data和log目录并赋予用户mongodb对应的权限,没有data和log目录或者权限不够时启动会失败
sudo chown -R mongodb /home/hadoop/mongodb
启动mongodb:
sudo systemctl start mongod
停止mongodb:
sudo systemctl stop mongod
重启mongodb:
sudo systemctl restart mongod
查看是否启动成功:
sudo systemctl status mongod
启动成功的显示
启动失败的显示:
7.卸载MongoDB
停止服务:
sudo systemctl stop mongod 或 sudo service mongod stop
移除安装包:
sudo apt-get purge mongodb-org*
移除数据和日志目录(以下为默认安装目录,需要修改成自己配置的实际目录):
sudo rm -r /var/log/mongodb
sudo rm -r /var/lib/mongodb
8.进入MongoDB shell命令模式
mongo
或指定端口
mongo -host 127.0.0.1:27017
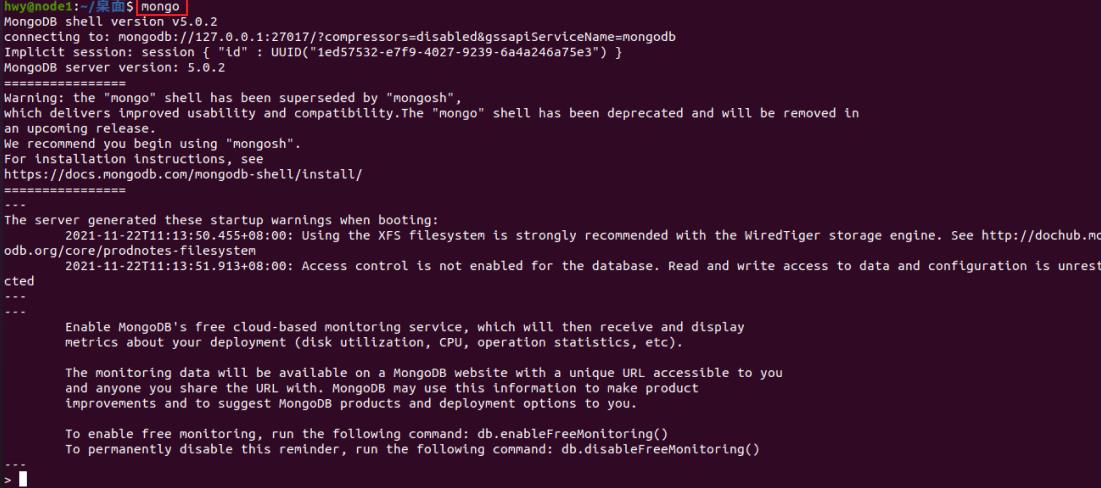
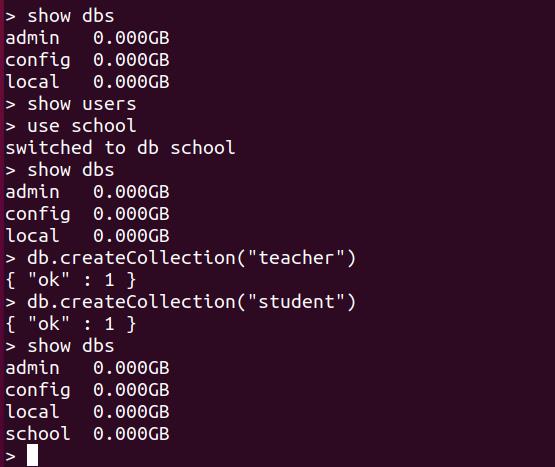
进入shell界面就可以查看数据库和创建数据库、集合等等
问题总结
问题1:在更新apt-get(sudo apt-get update)时大部分包都忽略或错误
解决方法一:(容易)
1、找到设置 2、软件和更新 3、选择其他站点 4、选择最佳服务器 5、重新在终端执行命令。(以下为在ubuntu20,ubuntu16在桌面右上角可找到设置及软件和更新)

等进度条完成之后
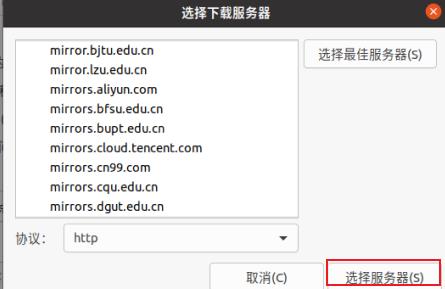
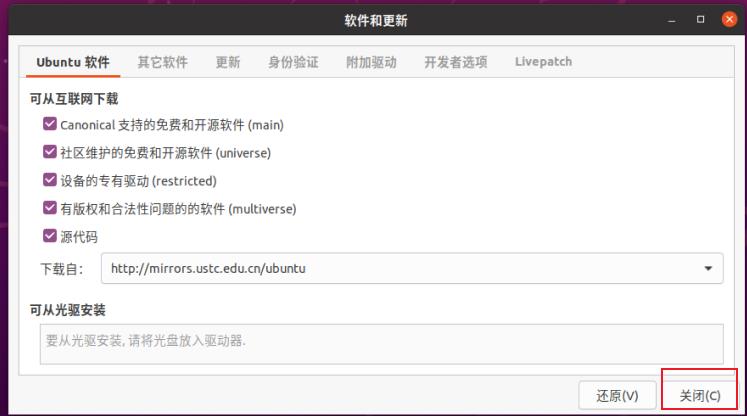
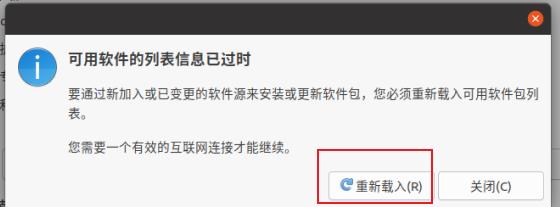
然后重新在终端执行命令即可。
解决办法二:换源
如果还不行的话,可以尝试手动换源(推荐清华源和阿里云源)
阿里巴巴开源镜像站:https://developer.aliyun.com/mirror/

换源步骤:(这里以阿里云源为例子)
首先备份源列表
sudo cp /etc/apt/sources.list /etc/apt/sources.list_backup
打开sources.list文件修改,在文件最前面添加阿里云镜像源:
sudo vim /etc/apt/sources.list
在文件的最前面加入:(按红圈中标志复制全部)

刷新列表
sudo apt-get update
sudo apt-get upgrade
sudo apt-get install build-essential
还有可能是Ubuntu版本较老的原因,因为ubuntu16已经不维护了,可考虑省级ubuntu18和20,
但记得做好快照,以防万一发生意外可以恢复原状。
问题2:

或者

**原因:**文件权限问题,用户mongod没有对必需文件的写权限,导致数据库服务不能启动。
解决办法:
sudo systemctl stop mongod
sudo chown -R mongodb /home/hadoop/mongodb (赋予权限)
sudo systemctl start mongod
即可解决
如果操作完还是解决不了,可尝试重启linux,再启动mongodb
reboot
sudo systemctl start mongod
问题3:
如果出现报错:Failed to start mongod.service: Unit mongod.service not found.
解决方法:
-
首先执行:
sudo systemctl daemon-reload -
然后再启动,还是报错可以按以下步骤继续处理
sudo vim /etc/systemd/system/mongodb.service
添加以下内容保存后再重启mongodb
[Unit]
Description=High-performance, schema-free document-oriented database
After=network.target
[Service]
User=mongodb
ExecStart=/usr/bin/mongod --quiet --config /etc/mongod.conf
[Install]
WantedBy=multi-user.target
问题4:
执行apt install/update时出现E: Could not get lock /var/lib/dpkg/lock - open (11: Resource temporarily unavailable)
解决方法:
首先确认是否有更新任务在运行,如果有等待其他更新任务完成或结束更新任务,否则执行以下命令:
sudo rm /var/lib/dpkg/lock
sudo dpkg --configure -a
sudo apt update
三.方法的名称、参数说明、作用、使用时的注意事项
首先进入mongodb shell
启动mongodb:
sudo systemctl start mongod
查看是否启动成功:
sudo systemctl status mongod
进入mongodb shell:
mongo
MongoDB数据库、集合与文档的基本操作
MongoDB中的记录是一个文档,它是由字段和值(key=>value)对组成的数据结构。 MongoDB文档与JSON对象相似。 字段的值可能包括其他文档,数组和文档数组。

1.特点
- 文档中的键值对是有序的:
“sport”:“football”,“address”:“北京”,“phone”:“13989622814” “sport”:“football”,“phone”:“13989622814”,“address”:“北京” - 值区分字符串和数字:
“name”:“json”,“age”:“18”
“name”:“json”,“age”:18 - 键区分大小写:
“name”:“json”,“age”:18
“Name”:“json”,“age”:18
2.文档键(field)命名规则
文档键(field)的命名需要注意以下几点:
- _id是系统保留的关键字。
- 不能包含\\0或空字符。
- 不能以$开头。
- 不能包含.(点号)。
- 区分大小写的且不能重复(同一个文档中)
3.基本数据类型
- null:表示空值或者不存在的字段。
“x”:null - 布尔(boolean):“true”和“false”
“x”:true - 数字:MongoDB支持的数字类型比较广泛,包括32位整数、64位整数、64位浮点数。
“x”:3.14 - 字符串:UTF-8字符串都可以表示为字符串类型的数据:
“x”:“HelloWorld!” - 数组:值的集合或者列表可以表示成数组:
“x”:[“a”,“b”,“c”] - 对象:对象Object:
“x”: Object()
4._id和ObjectId
- 自动生成_id:如果插入文档的时候没有指定“_id”值,系统会自动帮你创建一个,每个文档都有唯一的“id”值。
- _ObjectId:ObjectId是“_id”的默认类型。
5.日期
MongoDB中支持Date作为键的一个值
例如:“name”:“jack”,“date”:new Date()
文档中,date属性值为:new Date()
new Date() 创建了一个Date对象,返回日期的字符串表示。
6.内嵌文档
就是把整个MongoDB文档当做另一个文档中一个键的一个值。
“name”:“jack”,
“address”:
“street”:“Zoo Park Street”,
“city”:“Landon”,
进入mongodb shell
执行
mongo
或
mongosh
命令进入mongodb shell(注意这里mongod的服务已经启动)
MongoDB 创建数据库的语法格式如下:
use "DATABASE_NAME"
如果数据库不存在,则创建数据库,否则切换到指定数据库。
例如:以下示例创建了数据库 Employee:
use Employee
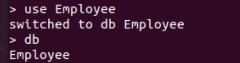
查看所有数据库:
show dbs
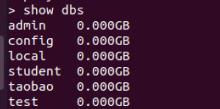
刚创建的数据库 Employee 并不在数据库的列表中, 要显示它,需要向 Employee 数据库插入一些数据。
db.Employee.insert("name":"google")
show dbs
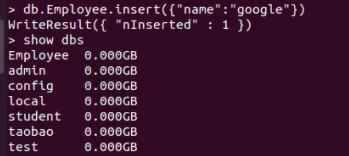
MongoDB 中默认的数据库为 test,如果没有创建新的数据库,集合将存放在 test 数据库中。
7.统计数据库信息
db.stats()
“db” : “test”, //数据库名
“collections” : 0, //集合数量
“objects” : 0, //文档数量
“avgObjSize” : 0, //平均每个文档的大小
“dataSize” : 0, //数据占用空间大小,不包括索引,单位为字节
“storageSize” : 0, //分配的存储空间
….
MongoDB 删除数据库
MongoDB 删除数据库的语法格式如下:
db.dropDatabase()
删除当前数据库,默认为 test,可以使用 db 命令查看当前数据库名。
db
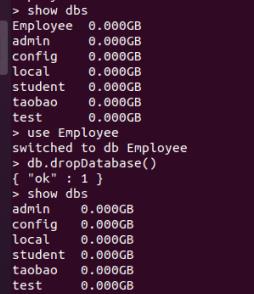
首先,使用show dbs查看所有数据库,然后用use切换到数据库Employee,再进行删除操作,最后使用show查看数据库是否删除成功,操作步骤如图所示:
show dbs
use Employee
db.dropDatabase()
show dbs
8.集合操作
命令格式:
db.createCollection(name, options)
例如在myDB数据库下创建myCollection集合,
执行以下命令:
use myDB
db.createCollection("myCollection")
查询数据库中所有的集合使用:
show collections
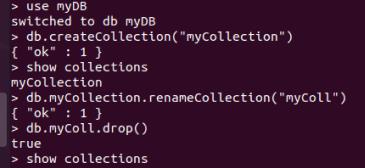
对集合重命名使用renameCollection方法,如下图所示:
db.myCollection.renameCollection("myColl")
查看集合详细信息
db.getCollectionInfos()
[
“name” : “myColl”,
“type” : “collection”,
“options” :
,
"info" :
"readOnly" : false
,
"idIndex" :
"v" : 2,
"key" :
"_id" : 1
,
"name" : "_id_",
"ns" : "myDB.myColl"
]
删除集合使用drop方法,如下图所示:
db.myColl.drop()
show collections
定长集合
db.createCollection( "myCollection", capped:true,size:10000 )
capped:是否定长,true为定长
size:集合中文档数量大小
定长集合中容量循环使用,用于实时监控
db.myCollection.isCapped() //判断集合是否定长。
插入文档
MongoDB 使用 insert() 或 save() 方法向集合中插入文档,语法如下:
db.COLLECTION_NAME.insert(document)
示例:向数据库student的stuinfo集合插入以下数据
- 使用数据库student
use student
- insert方法插入单个文档
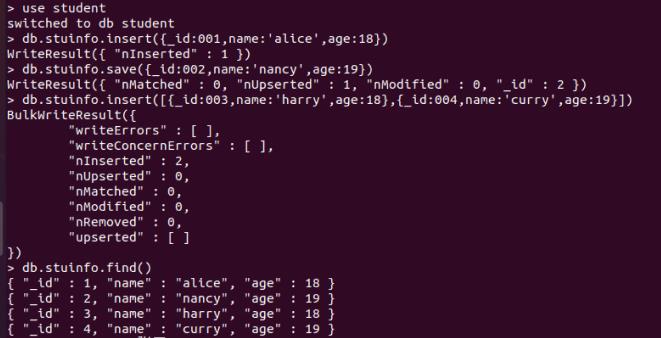
db.stuinfo.insert(_id:001,name:'alice',age:18)
- save方法插入单个文档
db.stuinfo.save(_id:002,name:'nancy',age:19)
- 插入多个文档
db.stuinfo.insert([_id:003,name:'harry',age:18,_id:004,name:'curry',age:19])
文档插入完成后,使用find()查看集合数据,具体操作步骤如下图所示:
注意: _id和ObjectId
- id 是文档的唯一标示,
- _ObjectId是_id的缺省产生办法
例:
db.myCollection.insert("x":"10") //不指定_id的值,自动创建
db.myCollection.insert("_id":"user001","y":"10") //指定_id的值,取指定值
db.myCollection.find()
查询结果:
"_id" : ObjectId("5c5ff402eb5725b5d8961b45"), "x" : "10"
"_id" : "user001", "y" : "10"
以上示例中stuinfo是我们的集合名,如果该集合不在该数据库中, MongoDB 会自动创建该集合并插入文档。
还可以可以先将文档定义为一个变量,再进行插入:
s=_id:5,name:'张三',age:19
db.stuinfo.insert(s)
操作结果如下图所示:
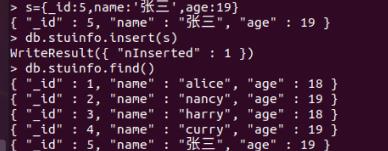
插入多条nancy的记录:
db.stuinfo.insert([_id:006,name:'nancy',age:17,_id:007,name:'nancy',age:21])
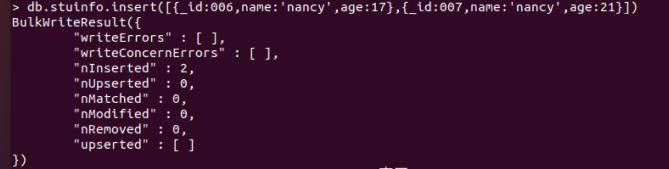
9.固定集合创建与删除
-
MongoDB中有一种特殊类型的集合,值得我们特别留意,那就是固定集合(capped collection)。
-
固定集合可以声明collection的容量大小,其行为类似于循环队列。数据插入时,新文档会被插入到队列的末尾,如果队列已经被占满,那么最老的文档会被之后插入的文档覆盖。
-
固定集合特性:固定集合很像环形队列,如果空间不足,最早的文档就会被删除,为新的文档腾出空间。一般来说,固定集合适用于任何想要自动淘汰过期属性的场景。
-
固定集合应用场景:比如日志文件,聊天记录,通话信息记录等只需保留最近某段时间内的应用场景,都会使用到MongoDB的固定集合。
-
固定集合的优点:
1.写入速度提升。固定集合中的数据被顺序写入磁盘上的固定空间,所以,不会因为其他集合的一些随机性的写操作而“中断”,其写入速度非常快(不建立索引,性能更好)。
2.固定集合会自动覆盖掉最老的文档,因此不需要再配置额外的工作来进行旧文档删除。设置Job进行旧文档的定时删除容易形成性能的压力毛刺。
固定集合非常实用与记录日志等场景。 -
固定集合的创建:不同于普通集合,固定集合必须在使用前显式创建。
例如,创建固定集合coll_testcapped,大小限制为1024个字节。db.createCollection("coll_testcapped",capped:true,size:1024); -
固定集合的创建:除了大小,创建时还可以指定固定集合中文档的数据量。
例如,创建固定集合coll_testcapped,大小限制为1024个字节,文档数量限制为100。db.createCollection("coll_testcapped2",capped:true,size:1024,max:100); -
注意事项:
1.固定集合创建之后就不可以改变,只能将其删除重建。
2.普通集合可以使用convertToCapped转换固定集合,但是固定集合不可以转换为普通集合。
3.创建固定集合,为固定集合指定文档数量限制时(指参数max),必须同时指定固定集合的大小(指参数size)。不管先达到哪一个限制,之后插入的新文档都会把最老的文档移除集合。4.使用convertToCapped命令将普通集合转换固定集合时,既有的索引会丢失,需要手动创建。并且,此转换命令没有限制文档数量的参数(即没有max的参数选项)。
5.不可以对 固定集合 进行分片。
6.对固定集合中的文档可以进行更新(update)操作,但更新不能导致文档的Size增长或缩小,否则更新失败。
假如集合中有一个key,其value 对应的数据长度为100个字节,如果要更新这个key 对应的value,更新后的值也必须为100个字节,大于100个字节不可以,小于100个字节也不可以。7.不可以对固定集合执行删除文档操作,但可以删除整个集合。
8.还有一定需要注意,对集合估算size时,不要依据集合的storageSize ,而是依据集合的size。storageSize是wiredTiger存储引擎采用高压缩算法压缩后的。
更新文档(区分update和save的区别)
MongoDB 使用 update() 和 save() 方法来更新集合中的文档。
- update() 方法用于更新已存在的文档。语法格式如下:
db.collection.update(<criteria>,<objNew>,upsert,multi,writeConcern)
参数说明:
query : update的查询条件,类似sql update查询内where后面的。
objNew : update的对象和一些更新的操作符(如 , , ,inc…)等,也可以理解为sql update查询内set后面的
upsert : 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。
multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。
writeConcern :可选,抛出异常的级别。
示例
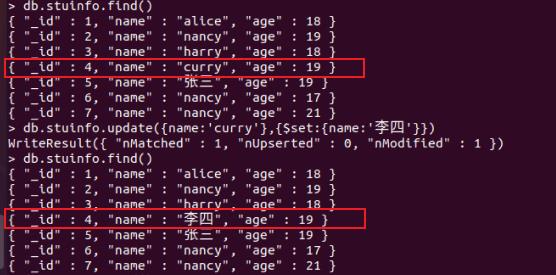
通过 update() 方法来更新上述文档的姓名(name): 将姓名(name)为curry的文档 更新为了 “李四”。
执行命令:
db.stuinfo.update(name:'curry',$set:name:'李四')
通过find()查看修改是否成功,具体操作步骤如下所示:
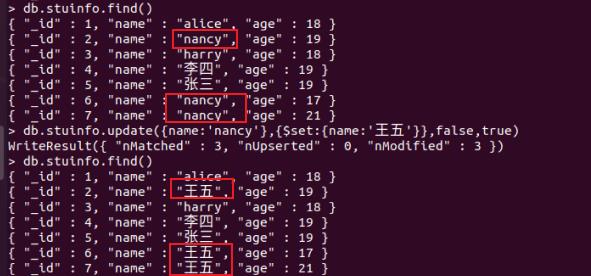
以上语句只会修改第一条发现的文档,如果要修改多条相同的文档,则需要设置 multi 参数为 true。
如将name为“nancy”所有文档更新为“王五”
db.stuinfo.update(name:'nancy',$set:name:'王五',false,true)
操作结果如下图所示:
- save() 方法通过传入的文档来替换已有文档。语法格式如下:
db.collection.save(<document>,writeConcern:<document>)
参数说明:
document : 文档数据。
writeConcern :可选,抛出异常的级别。
该方法在4.2版本开始已废弃
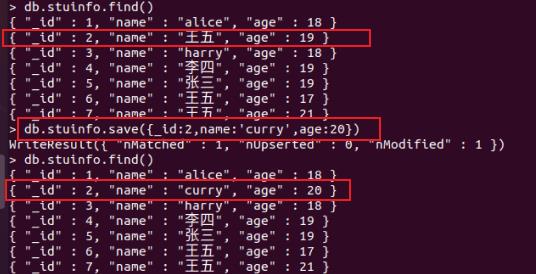
示例:替换 _id 为2的文档的数据:
db.stuinfo.save(_id:2,name:'curry',age:20)
操作步骤如下图所示:
10.更新文档——文档替换
用一个新文档代替匹配的文档
将
"_id" :ObjectId("5c6005ea0fc42acdb75f74a6"),
"name" : "foo",
"nickname" : "bar",
"friends" : 12,
"enemies" : 2
变成
"_id" : ObjectId("5c6005ea0fc42acdb75f74a6"),
"nickname" : "bar",
"relations" :
"friends" : 12,
"enemies" : 2
,
"username" : "foo"
修改步骤:
> var u=db.user.findOne("name":"foo") //将要修改的文档存到对象u中
> u.relations="friends":u.friends,"enemies":u.enemies//对象u中新增字段relations
"friends" : 12, "enemies" : 2 //relations嵌套文档
> u.username=u.name
foo
> delete u.friends
true
> delete u.enemies
true
> delete u.name
true
> db.user.update("name":"foo",u) //更新文档
WriteResult( "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 )
11.更新文档——修改器
- $inc (增加和减少,只能针对数字类型)
插入一个文档
> db.myColl.insert(title:"first",visites:107)
> db.myColl.find()
"_id" : ObjectId("5c887166713719923acc4c92"), "title" : "first", "visites" : 107
修改参观次数增加1
> db.myColl.update(title:"first",$inc:visites:1)
> db.myColl.find()
"_id" : ObjectId("5c887166713719923acc4c92"), "title" : "first", "visites" : 108
修改参观次数减少2
> db.myColl.update(title:"first",$inc:visites:-2)
> db.myColl.find()
"_id" : ObjectId("5c887166713719923acc4c92"), "title" : "first", "visites" : 106
- $set (可以完成特定需求的修改)
> db.author.findOne()
"_id" : ObjectId("5c600dbb0fc42acdb75f74a7"),
"name" : "foo",
"age" : 20,
"gender" : "male",
"intro" : "student"
使用$set进行修改:
> db.author.update("name":"foo",$set:"intro":"teacher")
> db.author.findOne()
"_id" : ObjectId("5c600dbb0fc42acdb75f74a7"),
"name" : "foo",
"age" : 20,
"gender" : "male",
"intro" : "teacher"
$set不仅仅可以修改变量,还可以修改数据类型:
db.author.update(name:"foo",$set:intro:["teacher","programmer"]) //String变成了数组
- $push修改器 (可以完成数组的插入)
原数据:
"_id" : ObjectId("5a1656e656d8db3756cafce8"),
"title" :"a blog",
"content" :"...",
"author" : "foo"
使用$push插入数组:
db.posts.update(title:"a blog",
$push:comments:name:"leon",email:"leon.email.com",content:"leon replay")
修改结果:
"_id" :ObjectId("5a1656e656d8db3756cafce8"), "title" : "a blog",
"content" :"...",
"author" : "foo",
"comments" : [ "name" : "leon",
"email" : "leon.email.com",
"content" : "leon replay"]
- $ addToSet修改器
原数据:
"_id" : ObjectId("5a1659a756d8db3756cafce9"),
"name" : "foo",
"age" :12,
"email" :[foo@example.com,foo@163.com]
向email数组中添加一个email信息:
Db.user.update(name:“foo”,$addToSet:Email:“foo@qq.com”)
修改结果:
"_id" : ObjectId("5a1659a756d8db3756cafce9"),
"name" : "foo",
"age" :12,
"email" :[foo@example.com,foo@163.com, foo@qq.com]
例子:
原数据:
"_id" :ObjectId("59f00d4a2844ff254a1b68f7"), "x" :1
"_id" :ObjectId("59f00d4a2844ff254a1b68f8"), "x" : 1
"_id" :ObjectId("59f00d4a2844ff254a1b68f9"), "x" : 1
"_id" :ObjectId("59f00d4a2844ff254a1b68fa"),"x" :2
要求:把所有x为1的数据改为99
采用命令:
db.集合名.update(x:1,$set:x:99,multi: true)
修改结果:
"_id" :ObjectId("59f00d4a2844ff254a1b68f7"),"x" :99
"_id" :ObjectId("59f00d4a2844ff254a1b68f8"), "x" :99
"_id" :ObjectId("59f00d4a2844ff254a1b68f9"), "x" :99
"_id" :ObjectId("59f00d4a2844ff254a1b68fa"),"x" : 2
更多示例:
生成多条记录:
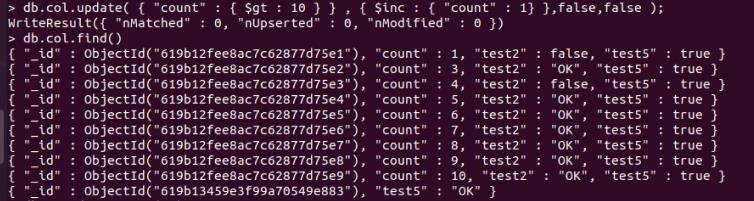
for(var i=1;i<10;i++) db.col.insert(count:i,test2:false,test5:true)


更新按条件查出来的第一条记录:
db.col.update( "count" : $gt : 1 , $set : "test2" : "OK" );
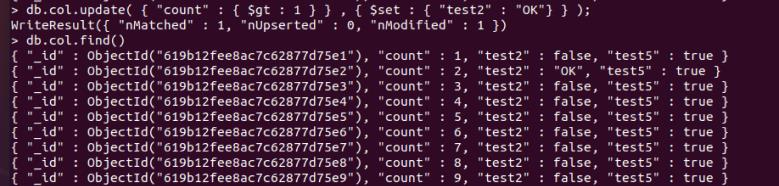
更新按条件查出来的全部条记录:
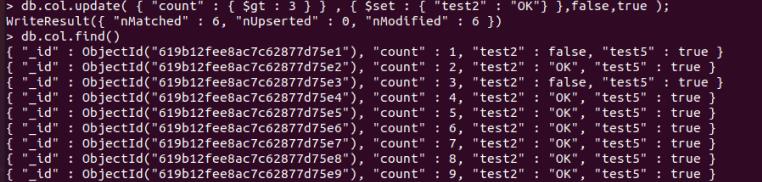
db.col.update( "count" : $gt : 3 , $set : "test2" : "OK" ,false,true );
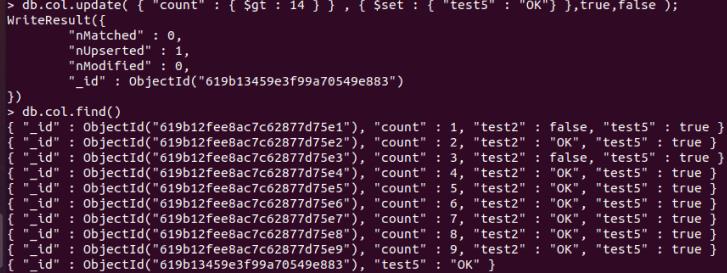
不存在update的记录,会添加一条:
db.col.update( "count" : $gt : 14 , $set : "test5" : "OK" ,true,false );
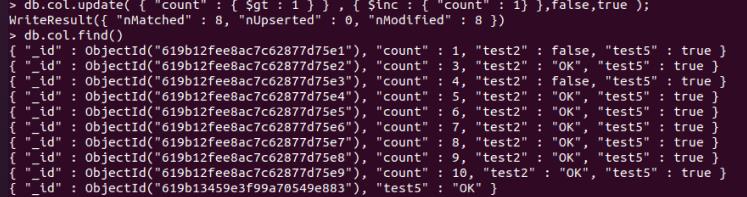
更新按条件查出来的全部条记录:
db.col.update( "count" : $gt : 1 , $inc : "count" : 1 ,false,true );
更新按条件查出来的第一条记录:
db.col.update( "count" : $gt : 10 , $inc : "count" : 1 ,false,false );
删除文档(注意区分remove和delete)
remove(),deleteOne() 和 deleteMany() 方法可以用来移除集合中的数据。
- 删除集合col下全部文档
db.col.deleteMany()
或
db.col.remove()
具体如下图所示

- 删除指定条件的文档
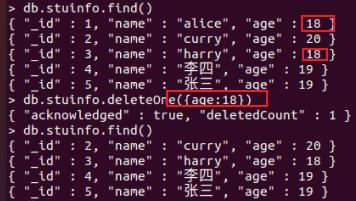
删除集合stuinfo中name等于王五的全部文档:
db.stuinfo.deleteMany(name:'王五')
删除 age等于 18 的一个文档:
db.stuinfo.deleteOne(age:18)
步骤如图:

四.MongoDB数据库查询与聚合操作
1.使用 find() 方法进行文档基本查询
语法格式如下:
db.collection.find(query, projection)
参数说明:
query :可选,使用查询操作符指定查询条件
projection :可选,使用投影操作符指定返回的键。查询时返回文档中所有键值, 只需省略该参数即可(默认省略)。指定键的值为0,不返回该键值对;为1时返回。
2.文档查询条件的使用

3.特定类型查询
针对特定类型的文档进行查询,如查询键为NULL的空文档
4.聚合查询
MongoDB中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果。db.collection.aggregate()是基于数据处理的聚合管道,每个文档通过一个由多个阶段(stage)组成的管道,可以对每个阶段的管道进行分组、过滤等功能,然后经过一系列的处理,输出相应的结果。
1.mongo查询
1.启动mongo
Mongo
2.使用test数据库,并新建items集合,保存订单相关信息。
use test
db.createCollection("items")

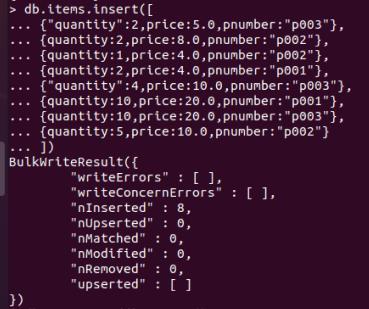
3.插入文档数据:
每个文档对应订单中某个商品相关信息,包括:
pnumber:商品编号
quantity:商品数量
price:商品单价
插入如下商品信息:
db.items.insert([
"quantity":2,price:5.0,pnumber:"p003",
quantity:2,price:8.0,pnumber:"p002",
quantity:1,price:4.0,pnumber:"p002",
quantity:2,price:4.0,pnumber:"p001",
"quantity":4,price:10.0,pnumber:"p003",
quantity:10,price:20.0,pnumber:"p001",
quantity:10,price:20.0,pnumber:"p003",
quantity:5,price:10.0,pnumber:"p002"
])
4.查询插入结果:
pretty() 方法以格式化的方式来显示所有文档
db.items.find().pretty()
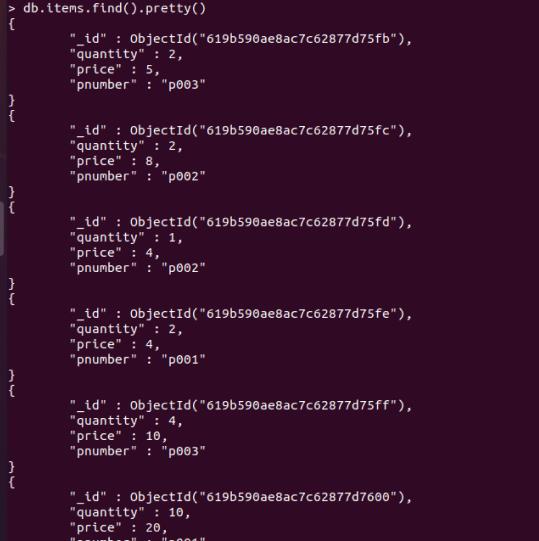
空的查询文档会匹配集合的全部内容。若是不指定查询文档,默认就是。例如:
db.user.find() //即查询user集合中的全部内容
db.user.find(“age”:18) //查找所有的“age”的值为18的文档
db.user.find(“name”:“jack”) //想匹配一个字符串,“name”的值为“jack”的
db.user.find(“name”:“jack”,“age”:18)//查询所有用户名为“jack”且年龄为18的用户
5.统计items共有多少个文档数据
db.items.count()

6.查询价格大于5的商品数据
大于使用gt操作符,另外操作符前面要带上$符号
db.items.find(price:$gt:5)

7.多条件查询
例:查询quantity为10且价格大于等于5的商品数据
db.items.find(quantity:10,price:$gte:5)

8.使用or来进行条件查询,格式如下:
db.col.find($or:[key1: value1, key2:value2])
例:查询quantity为10或价格大于等于5的商品数据
db.items.find($or:[quantity:10,price:$gte:5])

9.AND 和 OR 联合使用
例:查询pnumber为“p003”且quantity为10或价格大于等于5的商品数据
db.items.find(pnumber:"p003",$or:[quantity:10,price:$gte:5])

10.查询条件——包含( i n ) 或 不 包 含 ( in)或不包含( in)或不包含(nin)
例:
-
查询国籍是中国或者美国的学生信息
db.persons.find(country:$in:[“USA”,“China”]) -
查询国籍不是中国或美国的学生信息。
db.persons.find(country:$nin:[“USA”,“China”])
11.查询条件——” o r ” 查 询 与 “ or”查询与“ or”查询与“not”查询
$or 查询
查询语文成绩大于90或者英语成绩大于85的学生信息:
db.personsr.find($or:[c:$gte:85,e:$gte:90])
$not 查询
查询出名字中不存在“foo”的学生的信息:
db.persons.find(name:$not:/foo/)
12.特定类型查询——查询数组
数据:db.food.insert("fruit":["apple","banana","peach"])
接下来是具体的查询:
每一个元素都是整个键(数组的键)的值
db.food.find(fruit:"banana")
$all查询:需要多个元素来匹配数组时
如:要找到既有“apple”又有“banana”的文档
db.food.find(fruit:$all:["banana","apple"])
使用key.index语法指定数组的下标进行精准查询
db.food.find("fruit.2":"peach")
$size查询:查询指定数组的大小的文档
db.food.find("fruit":"$size":3)
查询结果都为:
"_id" :ObjectId("5b1dd90d1f23e9c34fc030a8"),
"fruit" :[ "apple","banana", "peach"]
13.游标
db.collection.find()方法返回一个游标,对于文档的访问,我们需要进行游标迭代。
游标使用过程如下:
-
声明游标:
var cursor = db.collectioName.find(query,projection); -
打开游标:
cursor.hasNext() //判断游标是否已经取到尽头。
-
读取数据:
cursor.Next() //取出游标的下一个文档。 -
关闭游标:
cursor.close() //此步骤可省略,通常为自动关闭,也可以显示关闭。 //我们用while循环来遍历游标示例: var mycursor = db.user.find() while(mycursor.hasNext()) printjson(mycursor.next()); -
游标——输出结果集
db.collection.find()方法返回一个游标,对于文档的访问,我们需要进行游标迭代。
1.使用print输出游标结果集:
var cursor = db.user.find() while (cursor.hasNext()) print(tojson(cursor.next()))2.使用printjson输出游标结果集:
var cursor = db.user.find() while (cursor.hasNext()) printjson(cursor.next())) -
游标——迭代
1.迭代函数:游标有一个迭代函数允许我们自定义回调函数来逐个处理每个单元。 cursor.forEach(回调函数),步骤如下:定义回调函数、打开游标、迭代。
数据源:
"_id" :ObjectId("5b1dd90d1f23e9c34fc030a8"), "fruit" :[ "apple","banana","peach" ] "_id" :ObjectId("5b1dddc51f23e9c34fc030a9"), "fruit" :[ "apple","kumquat","orange" ] "_id" :ObjectId("5b1ddddc1f23e9c34fc030aa"), "fruit" :[ "cherry","banana","apple" ]-
先定义一个函数(获取文档fruit数组)
var getFruit=function(obj) print(obj.fruit) -
打开游标:
var cursor=db.food.find(); -
迭代:
cursor.forEach(getFruit);
输出结果:
apple,banana,peach apple,kumquat,orange cherry,banana,apple2.基于数组迭代
数据源:
"_id" :ObjectId("5b1dd90d1f23e9c34fc030a8"), "fruit" :[ "apple","banana","peach" ] "_id" :ObjectId("5b1dddc51f23e9c34fc030a9"), "fruit" :[ "apple","kumquat","orange" ] "_id" :ObjectId("5b1ddddc1f23e9c34fc030aa"), "fruit" :[ "cherry","banana","apple" ]具体操作:
var cursor=db.food.find(); var documentArray =cursor.toArray(); printjson (documentArray);输出结果:
[ "_id" :ObjectId("5b1dd90d1f23e9c34fc030a8"), "fruit" :[ "apple","banana","peach" ] "_id" :ObjectId("5b1dddc51f23e9c34fc030a9"), "fruit" :[ "apple","kumquat","orange" ] "_id" :ObjectId("5b1ddddc1f23e9c34fc030aa"), "fruit" :[ "cherry","banana","apple" ] ] -
14.使用聚合aggregate
MongoDB 中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果。
语法:
db.collection.aggregate(pipeline, options)
例:
db.orders.aggregate([
$match: status: "A" ,
$group: _id: "$cust_id", total: $sum: "$amount"
])
第一阶段: m a t c h 阶 段 , 过 滤 查 询 结 果 第 二 阶 段 : match阶段,过滤查询结果 第二阶段: match阶段,过滤查询结果第二阶段:group阶段,对文档进行分组计算


例:统计订单中所有商品的数量,即统计quantity的总和。
db.items.aggregate([$group:_id:null,total:$sum:"$quantity"])

例:通过产品类型来进行分组,然后在统计卖出的数量
db.items.aggregate([$group:_id:"$pnumber",total:$sum:"$quantity"])

例:通过相同的产品类型来进行分组,然后查询相同产品类型卖出最多的订单详情。
db.items.aggregate([$group:_id:"$pnumber",max:$max:"$quantity"])

例:通过相同的产品类型来进行分组,然后查询每个订单详情相同产品类型卖出的平均价格
db.items.aggregate([$group:_id:"$pnumber",price:$avg:"$price"])

15.管道的使用
例:通过相同的产品类型来进行分组,统计各个产品数量,然后获取最大的数量。
db.items.aggregate([$group:_id:"$pnumber",total:$sum:"$quantity",$group:_id:null,max:$max:"$total"])

2.索引
提高查询效率最有效的手段。是解决查询速度缓慢而推出的一种特殊的数据结构,以易于遍历的形式存储部分数据内容;索引数据存储在内存当中,同样加快了索引查找数据的效率。
索引特点:
- 通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录
- 可以加快查询,但是同时降低了修改插入等性能
- 是特殊的数据结构,索引是对数据库表中一列或多列的值进行排序的一种结构
- 默认是用btree来组织索引文件
创建索引:
命令格式:
db.collection.createIndex( <keys>,<options> )
例:按age字段创建升序索引:
db.person.createIndex(age:1)
keys:希望创建索引的名称及排序方式,1 代表按升序排列;-1 代表按降序排列。
options:可选参数,表示建立索引的设置。可选值如下:
| Parameter | Type | Description |
|---|---|---|
| background | Boolean | 在后台建立索引,以便建立索引时不阻止其他数据库活动,默认值为false。 |
| unique | Boolean | 创建唯一索引,默认值 false |
| name | string | 索引的名称。假设未指定,MongoDB的通过连接索引的字段名和排序顺序生成一个索引名称。 |
| partialFilterExpression | Boolean | 如果指定,MongoDB只会给满足过滤表达式的记录建立索引。 |
| sparse | Boolean | 对文档中不存在的字段数据不启用索引,默认值是 false。 |
| expireAfterSeconds | integer | 指定索引的过期时间 |
| storageEngine | document | 允许用户配置索引的存储引擎 |
索引的类型
-
默认索引
对于每一个集合,默认会在_id字段上创建索引,而且这个特别的索引不能删除。_id字段是强制唯一的,由数据库维护。
-
单键索引
在一个键上创建的索引就是单键索引,单键索引是最常见的索引,如MongoDB默认创建的_id的索引就是单键索引
db.collection.createIndex(key, options) db.getCollection('test').createIndex( “name”:1 ) db.getCollection('test').createIndex( “name”:-1 ) ensureIndex()
在后台创建索引:
db.values.createIndex(open: 1, close: 1, background: true) -
复合索引
在多个键上建立的索引就是复合索引
db.getCollection('test').createIndex( “name”:1,”phone”:-1 )name是正序排列,phone是逆序排列的。
//find操作 db.getCollection('test').find(name:"qiiq") db.getCollection('test').find(name:"qiiq",phone:12512135) //这两种操作是能走联合索引。 //下面两种操作时不能走联合索引 db.getCollection('test').find(phone:12512135,name:"qiiq") db.getCollection('test').find(phone:12512135) -
多key索引/多键索引(Multikey Index)
如果文档中含有array类型字段,可以直接对其名称建立索引,这样MongoDB就会为内嵌数组中的每个元素建立一个独立的索引
注意:多键索引不等于在多列字段上创建索引(复合索引)
-
复合多键索引
对于一个复合多键索引,每个索引最多可以包含一个数组。
在多于一个数组的情形下来创建复合多键索引不被支持。假定存在如下集合
_id: 1, a: [ 1, 2 ], b: [ 1, 2 ], category: "AB - both arrays"创建索引db.COLLECTION_NAME.createIndex(a:1,b:1)是不允许的,因为a和b都是数组。
-
文本索引
-
地理位置索引
-
哈希索引
删除索引
主要有两种方式:
1.会删除当前集合中的所有索引(_id上的默认索引除外)。
db.集合名.dropIndexes()
2.可以根据指定的索引名称或索引文档删除索引(_id上的默认索引除外)。
db.集合名.dropIndex(index)
例:删除刚才创建的age索引:
db.person.dropIndex(age:1)
唯一索引
唯一索引可以确保集合的每一个文档的指定键都有唯一值。
语法如下:
db.collection.createIndex(索引名称或索引文档, unique:true);
例如,如果想保住文档的“name”键都有不一样的值,创建一个唯一索引就好了:
db.people.createIndex(“name”:1,“unique”:true)
即:people集合中创建按name键的值升序排列的唯一索引
-
消除重复
例如,删除“name”键重复的索引值:db.people.createIndex(“name”:1,“unique”:true,“dropDups”:true) -
复合唯一索引
复合索引:就是建立在多个字段上的索引。例如:
db.person.createIndex(“age”:1,“name”:1)复合唯一索引:
db.person.createIndex(“age”:1,“name”:1,"unique":true)
索引管理
-
查询索引
查询索引大小:db.集合名.totalIndexSize();(即索引所占空间大小)如:
-
修改索引
Mongodb没有单独的修改索引的方法,如果需要修改某个索引,需要先删除旧有的索引,再创建新的索引。db.集合名.dropIndex("索引名称")
五.python程序导入数据(python操作MongoDB)
pymongo是python访问MongoDB的模块,该模块定义了一个操作MongoDB的类PyMongoClient,包含了连接管理、集合管理、索引管理、增删改查、文件操作、聚合操作等方法。
1.python操作MongoDB例1:
数据准备
1.新建python文件
vim pydtf.py

2.导入数据
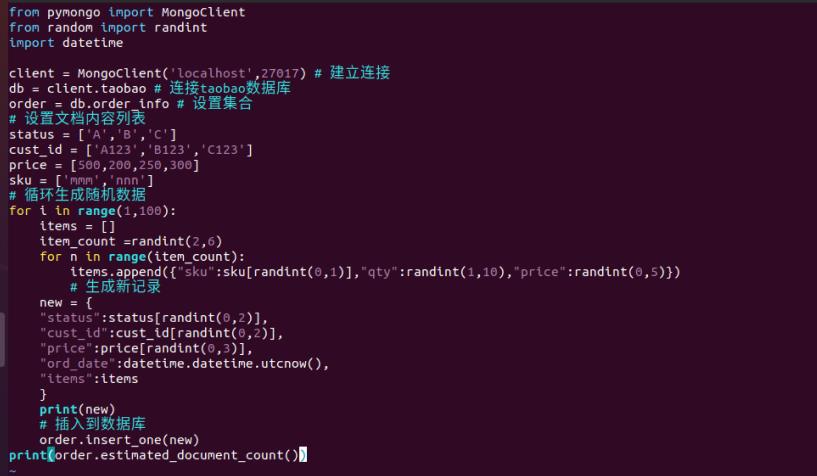
- 编写python程序导入数据至数据库淘宝,集合为order_info
from pymongo import MongoClient
from random import randint
import datetime
client = MongoClient('localhost',27017) # 建立连接
db = client.taobao # 连接taobao数据库
order = db.order_info # 设置集合
# 设置文档内容列表
status = ['A','B','C']
cust_id = ['A123','B123','C123']
price = [500,200,250,300]
sku = ['mmm','nnn']
# 循环生成随机数据
for i in range(1,100):
items = []
item_count =randint(2,6)
for n in range(item_count):
items.append("sku":sku[randint(0,1)],"qty":randint(1,10),"price":randint(0,5))
# 生成新记录
new =
"status":status[randint(0,2)],
"cust_id":cust_id[randint(0,2)],
"price":price[randint(0,3)],
"ord_date":datetime.datetime.utcnow(),
"items":items
print(new)
# 插入到数据库
order.insert_one(new)
print(order.estimated_document_count())
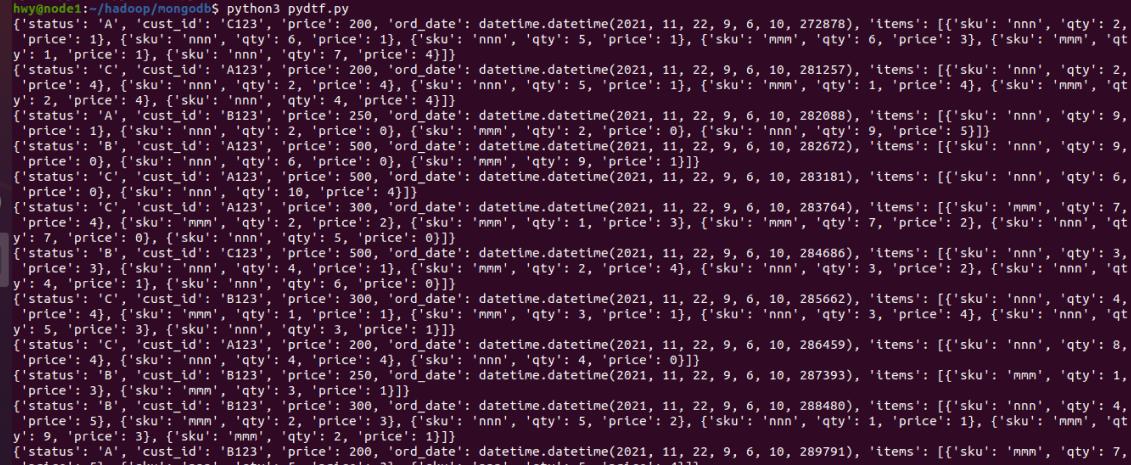
- 运行pydtf.py,导入数据。
python3 pydtf.py
MongoDB 聚合函数MapReduce
MongoDB 有两种聚合函数:aggregate 与 mapreduce
mapreduce函数提供的是mapreduce(编程模型)的聚合操作,它的工作流程如下图所示:
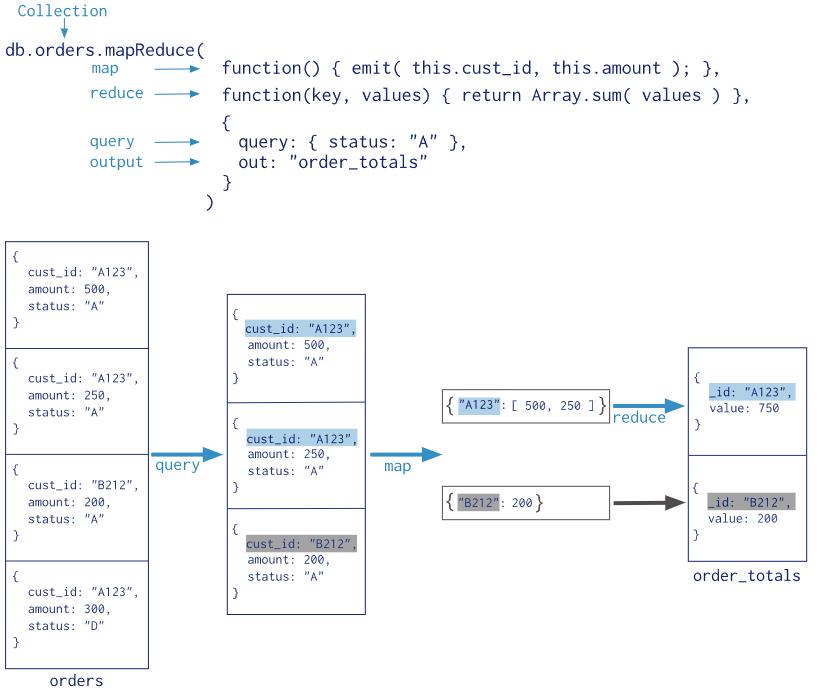
MongoDB中的MapReduce主要有以下几阶段:
-
Map:把一个操作Map到集合中的每一个文档
-
Shuffle: 根据Key分组对文档,并且为每
以上是关于MongoDB学习笔记总结(含报错问题技巧)的主要内容,如果未能解决你的问题,请参考以下文章