文本分类Recurrent Convolutional Neural Networks for Text Classification
Posted 征途黯然.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文本分类Recurrent Convolutional Neural Networks for Text Classification相关的知识,希望对你有一定的参考价值。
·摘要:
从模型的角度,本文作者将RNN(Bi-LSTM)和max_pooling结合使用,提出RCNN模型,应用到了NLP的文本分类任务中,提高了分类精度。
·参考文献:
[1] Recurrent Convolutional Neural Networks for Text Classification 论文链接:http://www.aaai.org/ocs/index.php/AAAI/AAAI15/paper/download/9745/9552
[1] 摘要
· 使用循环神经网络来捕获上下文信息;
· 采用最大池化层,自动判断哪些词在文本分类中起关键作用,捕获文本中的关键成分。
[2] 概述
2.1、传统机器学习的特征表征
有词袋模型(bag-of-words)、tfidf等等,传统的特征表示方法往往忽略了文本中的上下文信息或词序信息,不能很好地捕捉词语的语义。
2.2、使用RNN做特征表征
· 模型逐字分析文本,并将之前所有文本的语义存储在一个固定大小的隐藏层(hidden)中,能够更好地捕获上下文信息。通常使用最后一个时刻的隐藏层,作为最好的特征。
· RNN是一个有偏差的模型,后面的单词比前面的单词更占优势(类似于梯度爆炸、梯度消失)。因此,当使用它来捕获整个文档的语义时,因为关键信息可能出现在文档中的任何位置,而不是在文档的末尾。
2.3、提出新模型RCNN
首先用双向循环神经网络Bi-LSTM,以在学习单词表示时最大限度地捕捉上下文信息,在学习文本表示时可以保留较大范围的语序。其次,利用最大池化层max_pooling自动判断哪些特征在文本分类中起关键作用,以捕获文本中的关键成分。最后,结果全连接层进行分类。
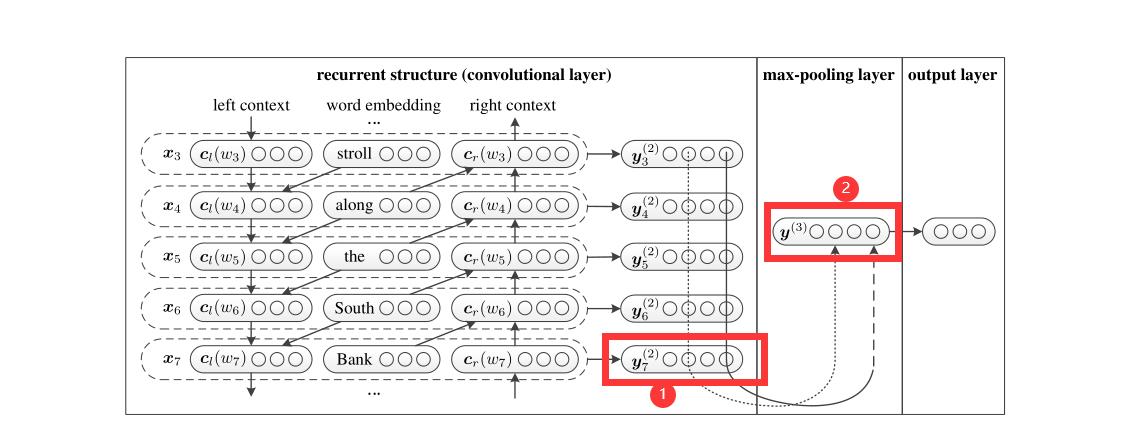
模型如上图所示:
1、左边: 是一个双向循环神经网络,xi为Bi-LSTM的输入,yi为Bi-LSTM的隐藏层。通常,在RNN中,我们会使用最后一个y,也就是循环神经网络中最后一个时刻的隐藏层,作为循环神经网络的输出,然后输入到全连接层分类。
2、中间: 是一个最大池化层,它把所有的y集合中的每个维度求MAX,构成最终池化后的隐藏层。
3、右边: 是一个全连接层,分类。
【思考一】池化的原理是取最大,在这里普通的句子已经被表征的面目全非了,很难粗略的断定,取最大是好是坏。得要数学证明。
【思考二】可以把embedding层的结果==[batch_size, seq_len, embeding]==,联合Bi-LSTM层的结果 [batch_size, seq_len, hidden_size * 2] 一起喂到最大池化层。因为它们的维度是一样的。
[3] 代码复现
贴出基础模型:
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
if config.embedding_pretrained is not None:
self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)
else:
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)
self.lstm = nn.LSTM(config.embed, config.hidden_size, config.num_layers,
bidirectional=True, batch_first=True, dropout=config.dropout)
self.maxpool = nn.MaxPool1d(config.pad_size)
self.fc = nn.Linear(config.hidden_size * 2 + config.embed, config.num_classes)
def forward(self, x):
x, _ = x
embed = self.embedding(x) # [batch_size, seq_len, embeding] = [128, 32, 300]
out, _ = self.lstm(embed) # [batch_size, seq_len, hidden_size * 2] = [128, 32, 512]
out = torch.cat((embed, out), 2) # [batch_size, seq_len, hidden_size * 2 + embeding] = [128, 32, 812]
out = F.relu(out) # [batch_size, seq_len, hidden_size * 2 + embeding] = [128, 32, 812]
out = out.permute(0, 2, 1) # [batch_size, hidden_size * 2 + embeding, seq_len] = [128, 812, 32]
out = self.maxpool(out).squeeze() # [batch_size, hidden_size * 2 + embeding] = [128, 812]
out = self.fc(out)
return out
实验结果(baseline):
| 数据集 | RNN | RCNN |
|---|---|---|
| THUCNews | 90.73% | 91.21% |
【思考三】本文是Bi-LSTM+max_pooling,可以尝试Bi-LSTM+conv+max_pooling等等。
[4] 获取本项目的源代码
如果需要本项目的源代码,请扫描关注我的公众号,回复“论文源码”。

以上是关于文本分类Recurrent Convolutional Neural Networks for Text Classification的主要内容,如果未能解决你的问题,请参考以下文章