当使用Flink 获取HDFS上的文件作为表进行计算时报错 file not found。
Posted 青冬
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了当使用Flink 获取HDFS上的文件作为表进行计算时报错 file not found。相关的知识,希望对你有一定的参考价值。
序
在进行Flink 开发的时候,使用的是Flink 1.13.2版本,当前版本对Flink SQL支持已经比较不错了,所以想用纯Flink SQL进行开发。
业务
消费Kafka 中的数据作为主表,获取HDFS路径上的某一个配置dim表进行关联然后输出到Kafka中。
SQL 实现
这里仅仅使用少量的sql做个演示,
创建主表SQL:
CREATE TABLE main_table (
`length` int, `local_province` int, `local_city` int, `owner_province` int
,`event_time` TIMESTAMP(3) METADATA FROM 'timestamp'
,WATERMARK FOR event_time AS event_time
) WITH (
'connector' = 'kafka',
'property-version' = 'universal',
'topic' = 'outTopicName',
'properties.bootstrap.servers' = 'ip:9093,ip:9093',
'properties.group.id' = 'ourGroupName',
'format' = 'csv',
'csv.field-delimiter' = '|',
'csv.ignore-parse-errors' = 'true'
)
;
创建dim表SQL:
CREATE TABLE `cfg_city`(
`provincecode` int, `city_id` int, `city_name` string, `province_name` string,
)
WITH (
'connector'='filesystem',
'path'='hdfspath://cfg_city',
'format' = 'csv',
'csv.field-delimiter' = ',',
'csv.ignore-parse-errors' = 'true'
)
;
关联Join操作
select * from main_table inner join cfg_city;
如果需要插入到Kafka等操作的话,直接一样创建表就可。
问题
如果你跟我一样使用上述的filesystem作为connector的话,那么可能就会报错。
原因是:使用了SQL FileSystem 后 该任务会变成Bounded(一次性读取,不会更新),并且会有一个BUG,当path中的文件名称 发生改变后(如:新增的文件无法被获取,老的文件删除会直接报错),会扔出 file not found的问题。
报错的时机
如果Flink fail 根据重试次数retry 并且 path中的文件被更改了。
报错详细
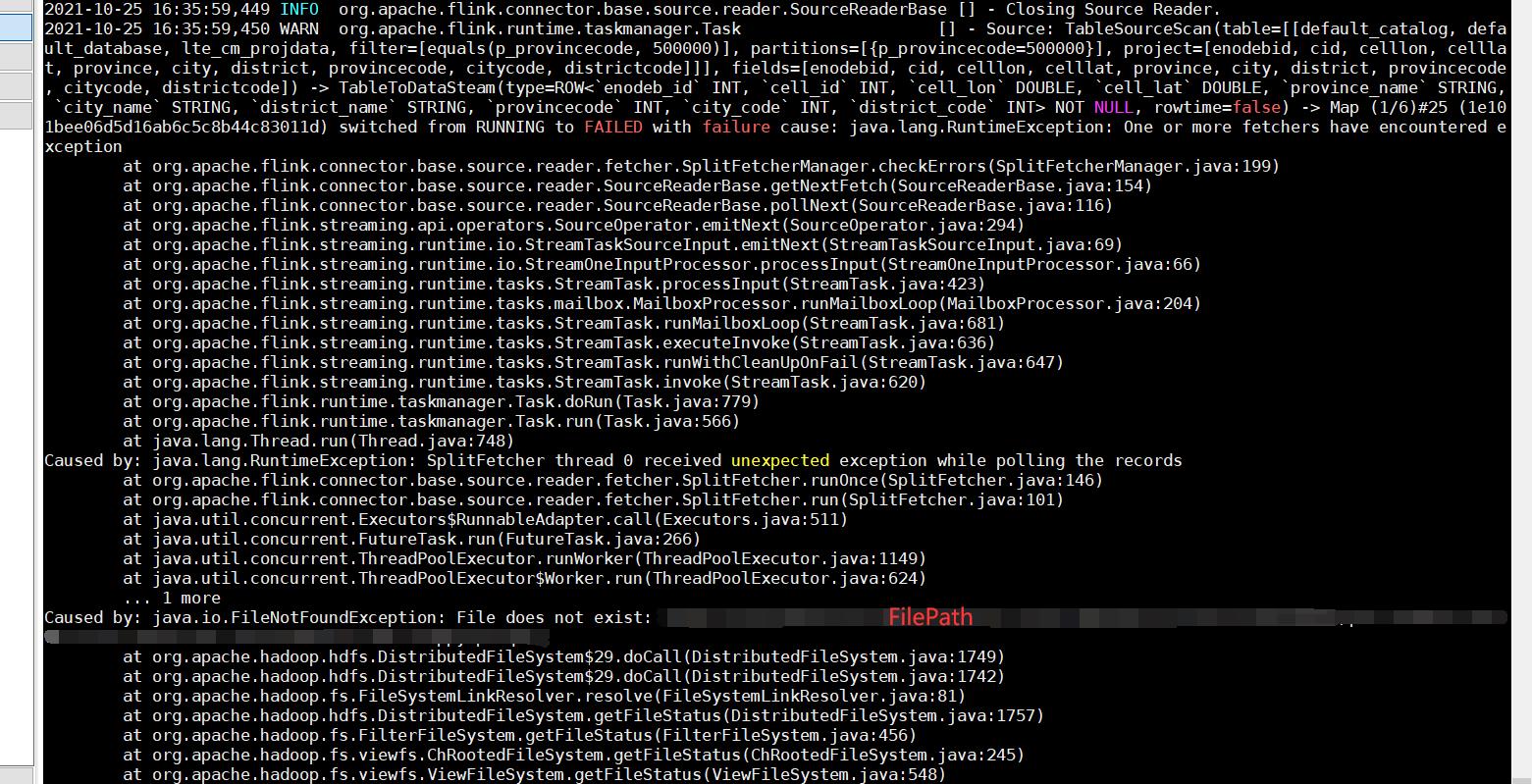
社区回复
在 https://issues.apache.org/jira/browse/FLINK-24641中可以看到,该问题确实存在,且无法被规避。
解决
使用Flink SQL 的 FileSystem时都会遇到这个问题,当前SQL 是不支持这个操作的。
请使用 ParquetRowInputFormat 来进行读取。
也就是说必须写代码了,不过我写了个模板欢迎获取,在主页中 搜索以下内容
Flink 定时获取HDFS上某路径的parquet文件,并作为dim与Kafka中的主表进行关联。
以上是关于当使用Flink 获取HDFS上的文件作为表进行计算时报错 file not found。的主要内容,如果未能解决你的问题,请参考以下文章