kafka一次磁盘故障后消费者无法消费
Posted 九师兄
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafka一次磁盘故障后消费者无法消费相关的知识,希望对你有一定的参考价值。

1.概述
转载:Kafka 运维纪实 – 一次磁盘故障后消费者无法消费

Kafka 自从某个版本加入 isr 等机制后真是越来越复杂了,再也不是原来那个单纯的 The log 了,碰上网络有个什么风吹草动经常耍点小脾气,不过小脾气就是小脾气,过会儿一般自己就好了,最多重启一下 Broker 也能自动恢复。不过这次好像真的生气了,大年初二一大早就看到 RCA 群里热闹非凡,有8台 Broker 嗝屁了。额,shit ,大年初二诶,还让人过年不了。
由于过年回老家,进了山区,左上角的4G图标一直显示成E,群里的消息也是时断时续,后来才知道兄弟们鏖战了两天两夜,Kafka 集群终于被基本驯服,为啥说基本呢,因为还有部分的 consumer 死活不能消费,不管怎么重启 consumer 的应用还是重启 broker 都无法解决问题,表现就是一直报:Attempt to join group xxxx failed due to obsolete coordinator information, retrying. 因为大家对这块都不熟,急着解决问题也没仔细看代码,所以实在不知道怎么办,但是有人实验发现更换 consumer group 名字后有的能恢复了,但也不是一定都能恢复,貌似这个还跟消费者名字相关,但至少找到了一个不是解决办法的解决办法,在长时间故障后,可能有的 consumer 应用方已经绝望了,要求更换 consumer group 的名字,不过所涉及的 topic 众多,牵涉太广了,在给几个 topic 更换 consuemr group 名字后我们还是回到了代码上。
在分析具体代码之前,我们先了解一下 Kafka Consumer 里几个概念。Kafka 跟传统的 JMS 不同,没有分 topic 和 queue 这样的概念,但是它引入了一个Consumer Group 的概念,多个 Consumer Group 名字相同的 Cosumer 组成一个集群,另外 Kafka 的每个 topic 是分 Partition 的(一个 Partition 就理解为一个顺序文件吧),消费的时候 Partition 在一个 Consumer Group 里分配。比如 topic a有3个 partition ,然后有三个 consumer,consumer group 都是g,则这三个 consumer 每个消费一个 partition ,如果 consumer 个数大于 partition 个数,则有的 consumer 空闲,如果 partition 个数大于 consumer 个数,则一个 consumer 会消费多个 parition (为了扩展性,我们一般会分配比 consumer 个数多的 partition )。

那么这里就存在一个 partition 和 consumer 的对应关系的分配问题,这个分配是由一个叫 GroupCoordinator 负责的。 GroupCoordinator 其实就是一台 Broker。每个 consumer group 都有自己的 GroupCoordinator ,当 consumer 开始消费的时候需要发送 GroupCoordinatorRequest 找到自己的 GroupCoordinator ,然后向这个 GroupCoordinator 发起 JoinGroup 的请求。那么哪一台 Broker 可以成为这个 consumer group 的 coordinator 呢?这个也挺有意思的,这涉及另外一个东西。
我们都知道 Kafka 的亮点之一就是用 Offset 来表示消费进度,也就是 consumer 和 broker 都不用记录每一条消息的消费状态,只需要记录一个数字,比如我消费到1000这个位置了只需要记录1000,我消费到了10000这个位置了只需要记录10000,这是非常轻量级的。不过虽然只用一个数字表示消费进度这个数字也是要地方存的,因为如果遇到 consumer 重启等我们还是要恢复之前的消费进度的,在早期的版本中 Kafka 默认把这个进度放到 Zookeeper 上(还记得曾经有一段时间我们 Zookeeper 流量剧增,就是有人把公共的Zookeeper 配给了 Kafka ),但是因为 Zookeeper 这个东西也有各种各样的问题(不说了,又是一把辛酸泪),
后来的版本 Kafka 就将 Offset 作为一个消息发送到一个叫__consumer_offsets 的内部 topic 里保存,这个设计真妙,感觉 Kafka 这帮人已经把 log 玩的溜溜的。__consumer_offsets 的工作机制后面还要说,这里就先回到 coordinator 的选择上来。既然__consumer_offsets 也是一个 topic ,那么它就也分了 Partition ,比如他就分为 n 个 Partition,则 Coordinator的选择方法就是 leader(abs(group.hashcode) % n) , 也就是用 consumer group 的名字的 hashcode 对__consumer_offsets 的分区数取模,得到一个分区编号,然后这个分区的 leader 在哪台 Broker 上,哪台 Broker 就是这个Consumer Group 的 GroupCoordinator 。比如现在__consumer_offsets 分为10个 topic ,然后你的 consumer group name 是 usercenter , hashcode 是2036233184,对10取模为4,4就是__consumer_offsets 的分区 id ,然后__consumer_offsets 的 replicas 是3,假设4这个分区落在1, 2, 3这三台 broker上,然后1是这个分区的 leader ,那么 usercenter 这个 consumer group 的 GroupCoordinator 就是1这一台。
那么现在不能消费的问题就是 Consumer 发送 GroupCoordinatorRequest 请求后, Broker 告诉它 GroupCoordinator 的地址,然后 Consumer 发送 JoinGroupRequest 请求到这个地址,这个 Broker 却不承认它是这个 Consumer Group 的 Coordinator ,见鬼了,这是怎么回事…
翻代码,我们在 GroupMetadataManager 这个类里找到了 Broker 是否承认它是 Coordinator 的代码:
def isGroupLocal(groupId: String): Boolean = loadingPartitions synchronized ownedPartitions.contains(partitionFor(groupId))
那么 ownedPartitions 又是什么呢,是什么时候添加的?继续往下看发现在一个Broker 收到 controller 的 LeaderAndIsrRequest 请求的时候,如果这个 Broker里包含一个__consumer_offsets 的分区,并且这个分区成为分区 leader 的时候则会触发一序列动作,然后在这些动作完成之后会将这个分区 id 添加到ownedPartitions 里(代码在 GroupMetadataManager 的 loadGroupsForPartition里)。
通过翻 state-change.log ,我们确实发现 Broker 收到了 LeaderAndIsrRequest ,并且确认成为 leader ,并且向 ownedPartitions 里添加分区id的逻辑在 finally 里的,即使抛异常都会执行。那么只有一个可能就是这个 loadGroupsForPartition 一直都没执行结束。
于是我们打了一个 jstack ,执行的线程一直是 Runnable 状态,而栈里一直是 messages.readInto(buffer, 0)里的 FileChannel.read ,然后再用 top 看了一下对应线程,占用 CPU 100%。这下应该清楚了,就是这个加载动作一直都没执行完,然后 consumer 不能消费(至于为什么有这种现象我们后面文章再做进一步分析)。
既然找到原因了,我们就准备进行恢复了,首先我们觉得既然问题出在__consumer_offsets 这个分区死活加载不完上面,那我就干脆将这个分区删除掉吧。ok,我们将一台 Broker 上的__consumer_offsets 删除,然后重启 Broker ,然后等待…还是不行,__consumer_offsets 的 replicas 是3,删除一个后 leader 跑到另外一台 Broker 上,并且删掉的这台不断地从 leader 同步。
然后又尝试过很多其他办法都不行,其中甚至想过将__consumer_offsets 这个topic 删除,但是因为集群中还有很多 topic 是正常的,如果删除这个会导致所有 consumer 不正常影响也就太大了。然后又想可不可以将__consumer_offsets 的过期策略设短,让 Kafka 自己删除呢,这虽然是一个可选方案,但是在网上搜了一下并不建议将__consumer_offsets 这个 topic 的保留策略设置为 delete (默认是 compact ),但是当时并没有仔细想为啥不建议,另外这是一个全局的配置,我们目前只是发现部分分区有问题,如果全改会不会有其他问题,当时并不确定。
后来想到,我们之前将整个分区删掉的方法可能有问题,删掉后肯定会从其他地方同步的,如果我们保留这个分区的最新几个 segment ,而将之前的删掉不就行了(其实就是 kafka 自己的 delete 策略,只不过我们只删除有问题的分区)。删除 – 重启 — 等待,不能消费的 consumer 终于又都开始消费了,终于松了一口气,睡觉。
躺在床上,越想越不对劲啊。__consumer_offsets 是用来干什么的呢,是用来保存消费进度的,那么这个__consumer_offsets 里的内容应该类似:

为了简化,上图只是显示了一个 topic(t1),一个 consumer group(g1) 消费一个 partition(p1) 的消费进度(最后的数字是消费进度,即 offset ),其实这个__consumer_offsets 里包含很多各种 topic ,各种 consumer_group 消费各种 partition 的消费进度。
那么对于消费进度来讲,其实只有最新的进度才有意义的,比如我现在已经消费到了100,那么之前的10其实是没有意义的。在上面的例子中,t1 g1 p1出现了三次,那其实只有第三条才有意义。 那么就很奇怪了,__consumer_offsets 的策略是 compact ,经过 compact 后,__consumer_offsets 应该非常小才对,觉得最多也就几十兆吧,为什么我们的__consumer_offsets 每个都有200多G?
看来是 compact 没生效啊,看了下代码发现是有专门的 compact 线程,打一个 jstack ,然后发现压根儿就没对应的线程啊,看来是 compact 线程挂掉了。看看 log clean 的日志,发现输出这样的日志: nnn messages in segment __consumer_offsets/0000000000000.log but offset map can fit only mmmmm. You can increase log.cleaner.dedupe.buffer.size or decrease log.cleaner.threads。
这又是什么鬼呢?看了下代码发现 Kafka 的 compact 的原理是在内存里有一个 map(OffsetMap) ,然后读取一条消息,用一个哈希算法(比如md5)计算这条消息 key 的值,然后插入到 map 里,这个 map 的 value 就是消息的 offset ,这样用大的 offset 替换掉小的,这样就达到去重的效果了。这里有两个参数:log.cleaner.dedupe.buffer.size 和log.cleaner.threads 。
- 前一个参数就是你能总共用多少内存来做去重这件事情
- 第二个参数是你用几个线程来做。
注意前一个参数是总内存,如果你用1G内存,两个线程,那么每个线程就是500M。我们的 Kafka 集群这两个参数都没有动过,前一个是128M,后一个是1。而且这个map 的内存要足够能装下至少一个 segment 里的消息,看起来128M内存是已经够了,因为__consumer_offsets 里有大量的重复的,但是我们预先是不能知道 segment 里的重复比例的,所以这里的计算是用消息条数来计算的。比如我们使用 MD5 算法来计算 key ,MD5 的长度是16,然后 offset 是8,则 map 里每条记录占用24个字节,则128M最多可以装载(5592405)条记录,而__consumer_offsets 里的每条消息都很小,导致每个 segment 里包含大量的消息,根据计算128M装不下了,导致 compact 线程出错退出,所以我们的 Kafka 里的__consumer_offsets 从第一天到现在都没有 compact 过...,而且这么重要的地方竟然没有监控。不过这个问题在 Kafka 后来的版本里做了改进(我们的 Kafka Broker 版本是0.9.0.1),后来版本的 Kafka 可以进行部分 Segment compact ,不要求装载一个完整的 Segment 了(https://issues.apache.org/jira/browse/KAFKA-3894)。下面用一个图来描述一下 Kafka 的 compact 原理:
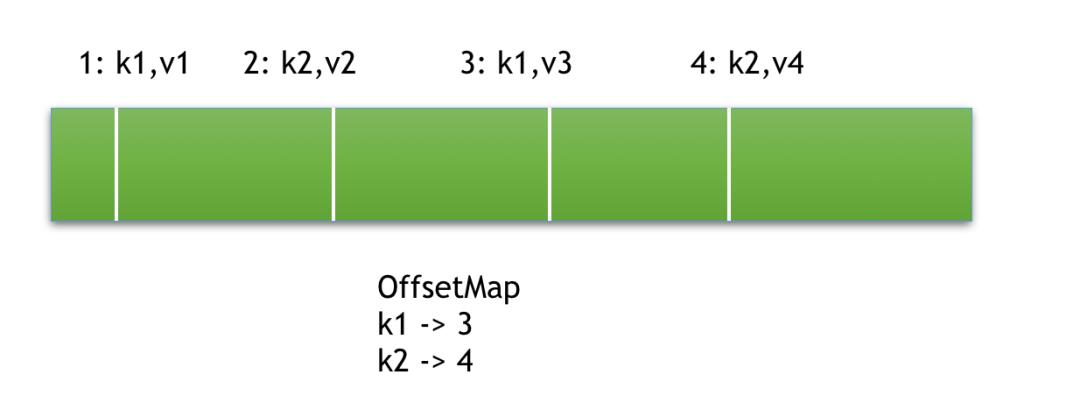
上图有4条消息,前面的数字表示 offset ,最后 OffsetMap 的结果是 offset 3和4保留下来了。
因为 Kafka 启动和__consumer_offsets 分区 leader 变更的时候,需要将__consumer_offsets 读取,然后获取到每个 group 的最新消费进度,所以__consumer_offsets 的大小严重的影响 consumer 可消费的启动速度,而且每次网络出现抖动有可能会引起 leader 变更,这也增加了 Kafka 的不稳定性。所以这个 compact 是否正常工作需要更加完善的监控。
嗯,如果深入使用一个开源系统,还是得很深入代码啊,新年许个愿今年把 Kafka 的代码好好读读,就这样。
参考:https://blog.csdn.net/qq_41049126/article/details/111311816
Kafka 提供了专门的后台线程定期地巡检待 Compact 的主题,看看是否存在满足条件的可删除数据。 这个后台线程叫 Log Cleaner。很多实际生产环境中都出现过位移主题无限膨胀占用过多磁盘空间的问题,如果你的环境中也有这个问题,我建议你去检查一下 Log Cleaner 线程的状态,通常都是这个线程 挂掉了导致的。
以上是关于kafka一次磁盘故障后消费者无法消费的主要内容,如果未能解决你的问题,请参考以下文章