使用python爬取App安卓应用商店评论并生成词云
Posted linchaolong
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用python爬取App安卓应用商店评论并生成词云相关的知识,希望对你有一定的参考价值。
华为应用商店评论爬虫
这里以潮汐APP为例,华为应用商店地址:https://appgallery.huawei.com/app/C10763864
1. 分析网页
使用Chrome打开应用商店地址,按F12打开开发工具分析评论请求数据
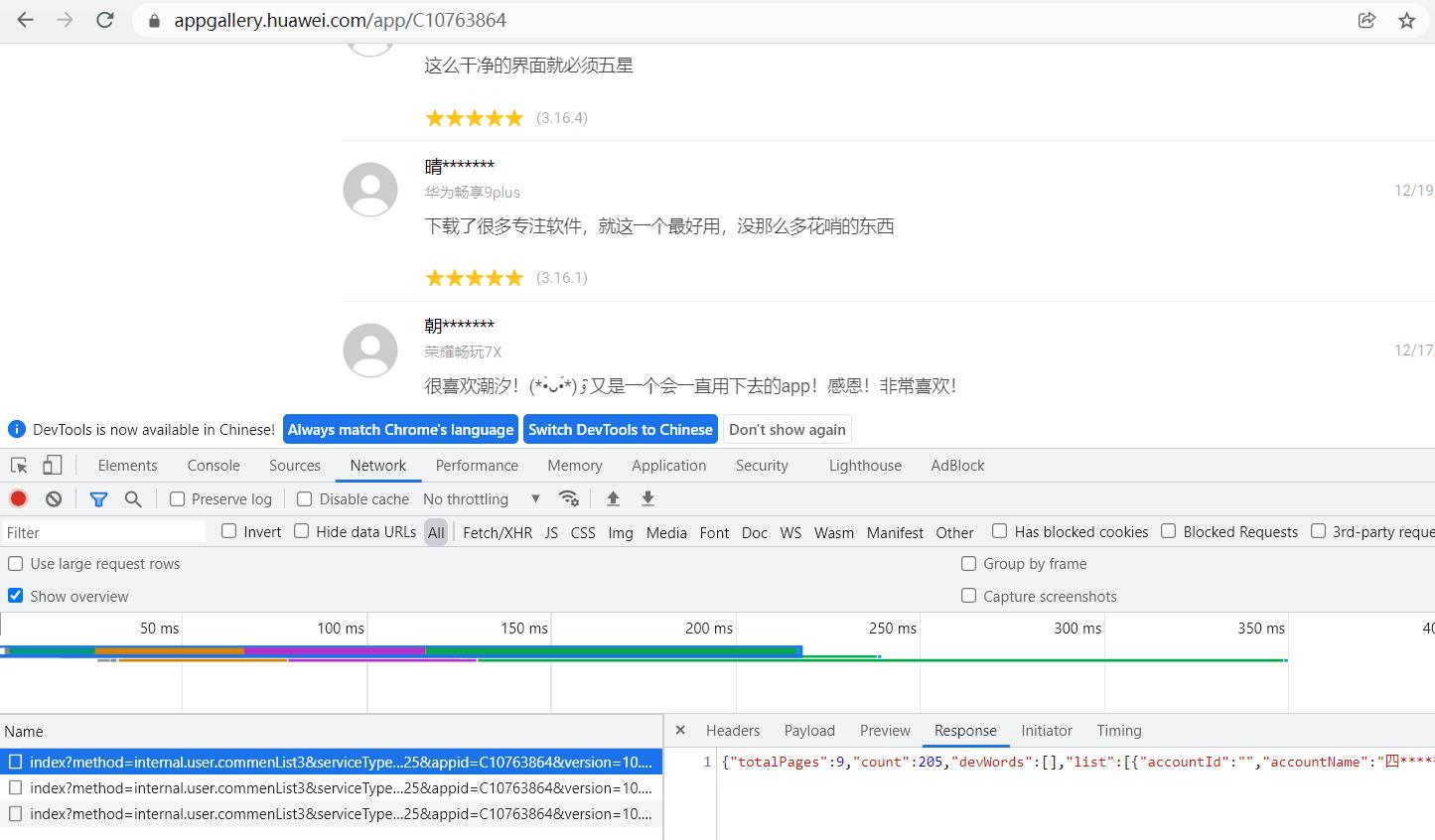
请求地址与参数:
https://web-drcn.hispace.dbankcloud.cn/uowap/index?method=internal.user.commenList3&serviceType=20&reqPageNum=1&maxResults=25&appid=C10763864&version=10.0.0&zone=&locale=zh
返回数据结构:
"devWords": [],
"score": "4.2",
"hotList": [],
"ratingDstList": [
"rating": 1,
"ratingCounts": 12
,
"rating": 2,
"ratingCounts": 5
,
"rating": 3,
"ratingCounts": 10
,
"rating": 4,
"ratingCounts": 23
,
"rating": 5,
"ratingCounts": 90
],
"totalPages": 9,
"count": 205,
"stars": "4.5",
"list": [
"accountId": "",
"accountName": "伊*******",
"approveCounts": 0,
"cipherVersion": "",
"commentAppId": "C10763864",
"commentId": "78f27a9e5efe4f97855dfdc613dfd3bf",
"commentInfo": "总体感觉体验还不错吧!就是能不能音乐声音小点?毕竟有些音乐很嘈杂,让人听起来很不舒服,就是专注不起来。",
"commentType": 0,
"id": "78f27a9e5efe4f97855dfdc613dfd3bf",
"isAmazing": 0,
"isModified": 0,
"levelUrl": "",
"logonId": "",
"nickName": "伊*******",
"operTime": "12/30/2021, 17:59",
"phone": "荣耀V40",
"photoUrl": "",
"rating": "4",
"replyComment": null,
"replyCounts": 0,
"serviceType": "",
"stars": "4",
"title": "",
"versionName": "3.17.0"
],
"rtnCode": 0,
"rspKey": "lmsvfDNs/GAAHkhvuTWg+VQZ84/pTPKdRUvpG7/d3IE="
2. 编码
# -*- coding: utf-8 -*-
from typing import List
import requests
from dataclasses import dataclass
from dataclasses_json import dataclass_json
import pandas as pd
from time import sleep
@dataclass_json
@dataclass
class Comment:
accountId: str
accountName: str
approveCounts: str
cipherVersion: str
commentAppId: str
commentId: str
commentInfo: str
commentType: str
id: str
isAmazing: int
isModified: int
levelUrl: str
logonId: str
nickName: str
phone: str
operTime: str
photoUrl: str
rating: str
replyComment: str
replyCounts: int
serviceType: str
stars: str
title: str
versionName: str
@dataclass_json
@dataclass
class CommentPage:
totalPages: int
count: int
devWords: List[str]
list: List[Comment]
encoding: str = 'utf-8'
class HuaweiSpider:
@staticmethod
def commentPage(page) -> CommentPage:
"""
评论分页
:param page: 页码,从1开始
:return:
"""
url = "https://web-drcn.hispace.dbankcloud.cn/uowap/index?method=internal.user.commenList3&serviceType=20&reqPageNum=%s&maxResults=25&appid=C10763864&version=10.0.0&zone=&locale=zh" % page
print(url)
r = requests.get(url, headers=
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9,ko;q=0.8,und;q=0.7,en;q=0.6,zh-TW;q=0.5,ja;q=0.4',
'Connection': 'keep-alive',
'Host': 'web-drcn.hispace.dbankcloud.cn',
'Referer': 'https://appgallery.huawei.com/',
'sec-ch-ua': '" Not A;Brand";v="99", "Chromium";v="96", "Google Chrome";v="96"',
'sec-ch-ua-mobile': '?0',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'cross-site',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/91.0.4472.114 Safari/537.36',
, verify=False)
r.encoding = r.apparent_encoding
if r and r.status_code == 200:
print(r.content)
content = CommentPage.from_json(r.content)
content.encoding = r.encoding
return content
if __name__ == '__main__':
page = 1
columns = ['用户名', '评论', '评分', '评论时间', '版本号', '设备']
data = []
while True:
commentPage = HuaweiSpider().commentPage(page)
if len(commentPage.list) > 0:
print(commentPage)
for row in commentPage.list:
data.append([row.nickName, row.commentInfo, row.stars, row.operTime, row.versionName, row.phone])
page += 1
sleep(2)
else:
break
df = pd.DataFrame(data, columns=columns)
df.to_excel('华为应用商店评论.xlsx', index=False)
酷传网
由于安卓下面应用商店实在太多,后来发现酷传网上面就可以直接下载应用商店的评论数据,于是就直接在上面下载了。
酷传网网址:https://www.kuchuan.com/
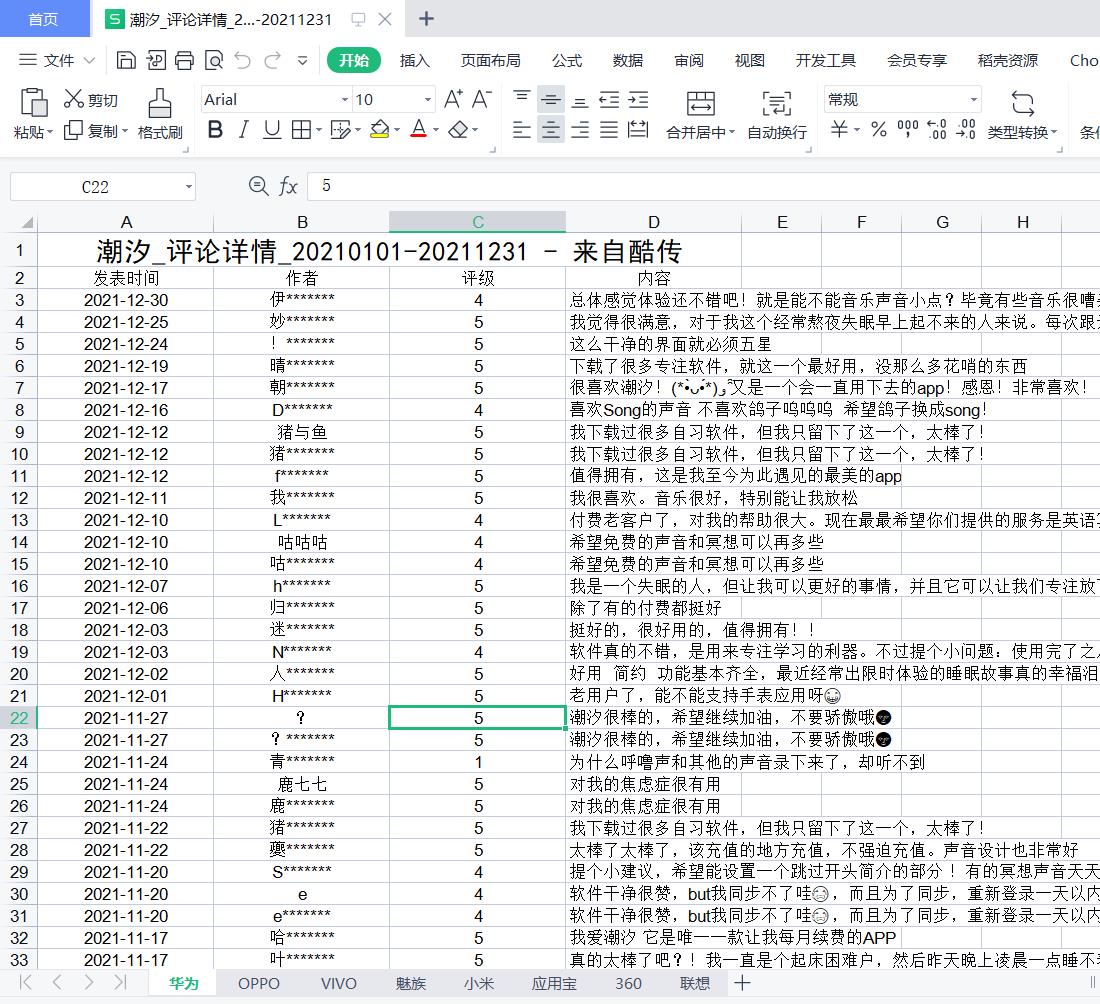
下载下来的应用评论数据如下,不同应用商店的评论数据存放在各自的sheet
词云
词云是文本数据的视觉表示,由词汇组成类似云的彩色图形,用于展示大量文本数据。词汇出现频次越高在词云图中显示越突出,从而让读者快速抓住重点。
词云的本质是点图,是在相应坐标点绘制具有特定样式的文字的结果
1. 词云生成流程:
- 读取评论文件,合并所有应用商店的评论数据
- 将所有评论数据用换行符链接成一个字符串
- 使用jieba分词对评论字符串进行切分
- 去掉无用词汇
- 计算词频
- 渲染词云
2. 编码
import jieba
import collections
import re
from pyecharts.charts import WordCloud
from pyecharts.globals import SymbolType
from pyecharts import options as opts
from pyecharts.globals import ThemeType
import pandas as pd
# 去除分词结果中的无用词汇
def deal_txt(seg_list_exact):
result_list = []
with open('stop_words.txt', encoding='utf-8') as f:
con = f.readlines()
stop_words = set()
for i in con:
i = i.replace("\\n", "") # 去掉读取每一行数据的\\n
stop_words.add(i)
for word in seg_list_exact:
# 设置停用词并去除单个词
if word not in stop_words and len(word) > 1:
result_list.append(word)
return result_list
# 渲染词云
def render_cloud(word_counts_top100, path):
word1 = WordCloud(init_opts=opts.InitOpts(width='1350px', height='750px', theme=ThemeType.MACARONS))
word1.add('词频', data_pair=word_counts_top100, word_size_range=[15, 108], textstyle_opts=opts.TextStyleOpts(font_family='cursive'), shape=SymbolType.DIAMOND)
word1.set_global_opts(title_opts=opts.TitleOpts('评论云图'), toolbox_opts=opts.ToolboxOpts(is_show=True, orient='vertical'), tooltip_opts=opts.TooltipOpts(is_show=True, background_color='red', border_color='yellow'))
# 渲染在html页面上
word1.render(path)
def word_clound_from_string(data: str, path: str):
# 文本预处理 去除一些无用的字符 只提取出中文出来
new_data = re.findall('[\\u4e00-\\u9fa5]+', data, re.S)
new_data = " ".join(new_data)
# jieba分词将整句切成分词
seg_list_exact = jieba.cut(new_data, cut_all=True)
# 去掉无用词汇
final_list = deal_txt(seg_list_exact)
# 筛选后统计
word_counts = collections.Counter(final_list)
# 获取前100最高频的词
word_counts_top100 = word_counts.most_common(100)
# 可以打印出来看看统计的词频
# print(word_counts_top100)
# 渲染词云
render_cloud(word_counts_top100, path)
def word_cloud_form_txt(txt: str, output: str):
"""
解析txt文件并生成词云
:param txt: txt文件路径
:param output: 词云文件输出路径
"""
# 读取弹幕文件
with open(txt, encoding='utf-8') as f:
data = f.read()
word_clound_from_string(data, output)
def word_cloud_form_excel(excel: str, output: str):
"""
解析excel文件并生成词云
:param excel: excel文件路径
:param output: 词云文件输出路径
"""
df = pd.read_excel(excel)
data = '\\n'.join(df["评论"])
word_clound_from_string(data, output)
def word_cloud_form_kuchuan_excel(excel: str, output: str, combined: str = None):
"""
解析酷传网excel文件并生成词云
:param excel: 酷传excel文件路径
:param output: 词云文件输出路径
:param combined: 酷传各应用商店评论数据汇总的文件输出路径
"""
xl = pd.ExcelFile(excel)
df_combined = pd.DataFrame()
# 将不同应用商店的评论数据合并到一个DataFrame
for sheet_name in xl.sheet_names:
df = xl.parse(sheet_name)
# 将列名设置为第一行
cols = df.ix[0, :]
df.columns = cols
# 删除列名
df.drop(index=df.index[0], axis=0, inplace=True)
df['来源'] = sheet_name
df_combined = pd.concat([df_combined, df])
df_combined = df_combined.append(df)
if combined:
df_combined.to_excel(combined, index=False)
comment = df_combined["内容"].astype(str, copy=False)
data = '\\n'.join(comment)
word_clound_from_string(data, output)
if __name__ == '__main__':
# word_cloud_form_excel('../spider/华为应用商店评论.xlsx')
word_cloud_form_kuchuan_excel('../spider/潮汐_评论详情_20210101-20211231.xls', '潮汐词云2021.html', '潮汐安卓应用商店评论汇总2021.xlsx')
3. 词云图
最后会生成一个html格式的词云图,直接用浏览器打开就好了。

以上是关于使用python爬取App安卓应用商店评论并生成词云的主要内容,如果未能解决你的问题,请参考以下文章