MySQL总结
Posted yuwenS.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL总结相关的知识,希望对你有一定的参考价值。
文章目录
1、mysql总结
1.1、SQL的分类
数据查询语言:(DQL)select
数据操纵语言:(DML)insert,delete,update
数据定义语言:(DDL)create,drop,alter
事务控制语言:(TCL)commit,rollback
数据控制语言:(DCL)grant,revoke
1.2、命令导入数据数据
source <sql脚本路径> # source D://a.sql
1.3、简单命令
1.3.1、查看数据库版本
mysql --version
mysql -V
1.3.2、创建数据库
cerate datebase 数据库名; #create database test;
使用数据库
use 数据库名; #use test
1.3.3、查看使用的数据库
select database();
# 查看数据库版本
select version();
1.3.4、查看所有数据库和查看当前库中所有表
show databases; #查看所有数据库
show tables; #查看库中所有表
1.3.5、查看其它库中的表
show tables from 数据库名;
1.3.6、查看表结构
desc 表名;
1.3.7、查看创建表的语句
show create table 表名;
1.4、查询(DQL)
1.4.1、条件查询
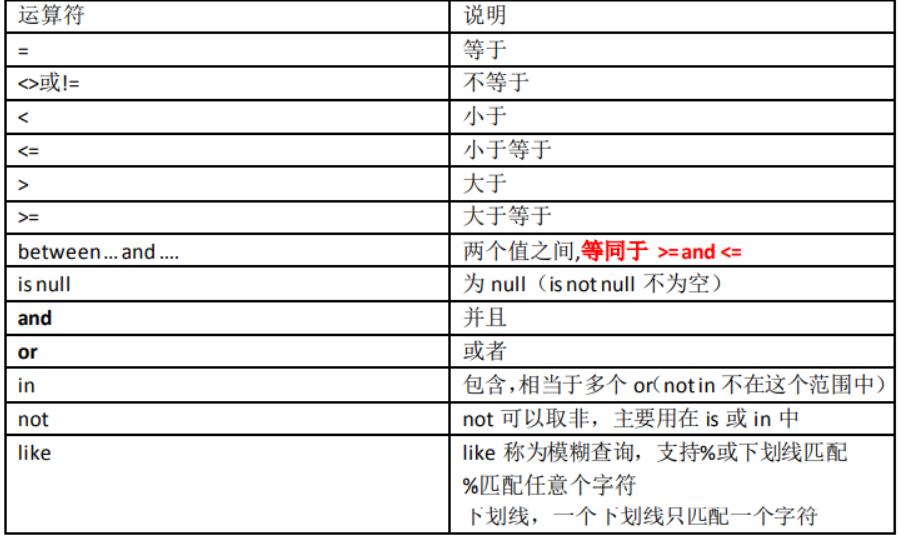
条件查询需要用到 where 语句,where 必须放到 from 语句表的后面 支持如下运算符
distinct 去除重复行
1.4.2、排序数据
单一字段排序: 排序采用 order by 子句,order by 后面跟上排序字段,排序字段可以放多个,多个采用逗号间隔,order by 默认采用升 序,如果存在 where 子句那么 order by 必须放到 where 语句的后面
多个字段排序: order by 后面紧跟哪一个字段就先排哪个字段,依次向下排序
1.4.3、数据处理函数/单行处理函数
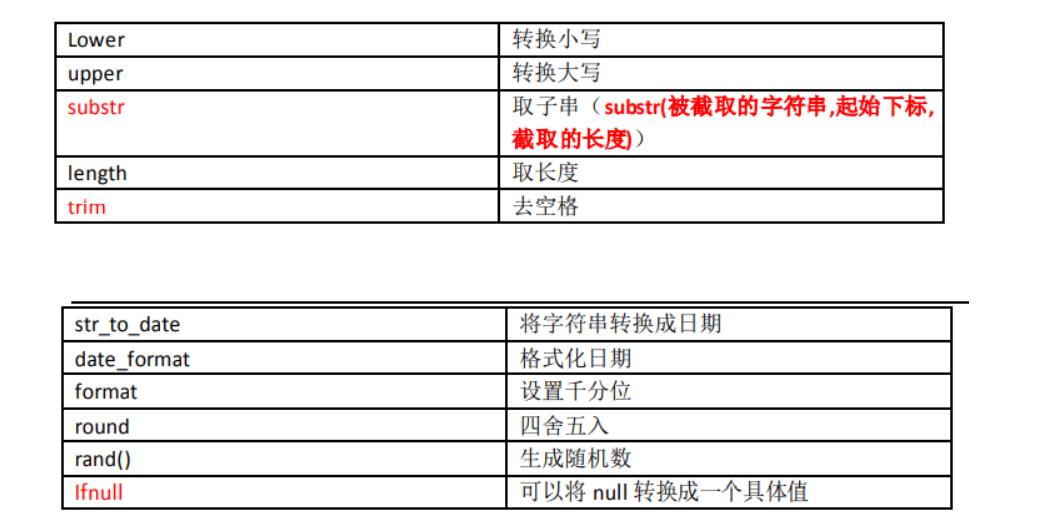
select lower(字段) from 表名; #将该字段查出的数据全部转为小写
1.4.4、case … when … then ……else …end
当员工的工作岗位是MANAGER的时候,工资上调10%,当工作岗位是SALESMAN的时候,工资上调50%,其它正常
注意: 这里不改变数据库值,只改变查询出来的结果
select
ename,
job,
sal as oldsal,
(case job when 'MANAGER' then sal*1.1 when 'SALESMAN' then sal*1.5 else sal end) as newsal
from
emp;
1.4.5、ifnull
select ifnull(字段名,0) from 表名; #表示该字段如果为空就替换为0
在 SQL 语句当中若有 NULL 值参与数学运算,计算结果一定是 NULL 为了防止计算结果出现 NULL,建议先使用 ifnull 空值处理函数预先处理
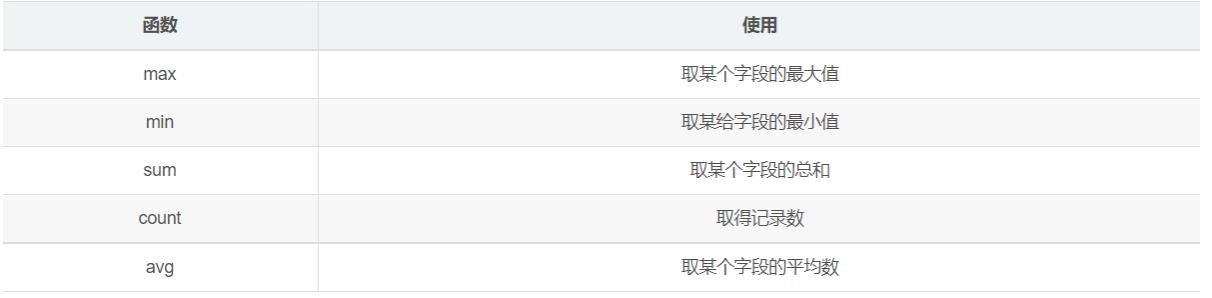
1.4.6、分组函数/聚合函数/多行处理函数
1.4.7、分组查询
分组查询主要涉及到两个子句,分别是:group by 和 having
原则:能在 where 中过滤的数据,尽量在 where 中过滤,效率较高。having 的过滤是专门对分组之后的数据进行过滤的
select 字段
from 表名
where ……
group by ……
having ……(就是为了过滤分组后的数据而存在的—不可以单独的出现)
order by ……
1.4.8、连接查询
连接分类: 连接分为内连接和外连接
内链接: 表 1 inner join 表 2 on 关联条件做连接查询的时候一定要写上关联条件 inner 可以省略
外连接 : 外连接分为左外连接和右外连接
**左外连接:**表 1 left outer join 表 2 on 关联条件 做连接查询的时候一定要写上关联条件 outer 可以省略
右外连接: 表 1 right outer join 表 2 on 关联条件做连接查询的时候一定要写上关联条件outer 可以省略
左外连接(左连接)和右外连接(右连接)的区别: 左连接以左面的表为准和右边的表比较,和左表相等的不相等都会显示出来,右表符合条件的显示,不符合条件的不显示右连接恰恰相反,以上左连接和右连接也可以加入 outer 关键字,但一般不建议这种写法
1.4.9、子查询
子查询就是嵌套的 select 语句,可以理解为子查询是一张表
where子查询: 在where语句中加入select语句
select * from 表名 where id = (select id from 表名)
from子查询: 在from语句中使用子查询
select * from 表名 join (子查询) on 条件
select子查询: 在select语句中使用子查询
select 字段,(子查询) from 表名 字段
1.4.10、union和limit
union: 表示可以合并的集合(相加)
select * from student where hight > 170 union select * from student where hight < 155
# 查询hight大于170和hinght小于155的学生信息
limit: 主要用于提取前几条或者中间某几行数据
select * from 表名 where 条件 limit 0 5 # 拿取从第一条数据为始的5条数据
1.5、表
1.5.1、创建表
创建表的时候,表中有字段,每一个字段有:
- 字段名
- 字段数据类型
- 字段长度限制
- 字段约束
mysql常用数据类型:
| 类型 | 描述 |
|---|---|
| char(长度) | 定长字符串,存储空间大小固定,适合作为主键或外键 |
| varchar(长度) | 变长字符串,存储空间等于实际数据空间 |
| double(有效数字位数,小数位) | 数值型 |
| Float(有效数字位数,小数位) | 数值型 |
| Int(长度) | 整型 |
| bigint(长度) | 长整型 |
| Date | 日期型 |
| blob | Binary Large OBject(二进制大对象) |
| 其他类型… | … |
1.5.2、增加/删除/修改表结构
添加字段
alter table 表名 add 字段名 字段类型(长度);
修改字段
alter table 表名 modify 字段名 字段类型(长度);
删除字段
alter table 表名 drop 字段名;
1.5.3、数据的增删改(DML)
插入数据(insert)
insert into 表名(字段名,字段名,...,字段名) values(字段值,字段值,...,字段值)
更改数据(update)
update 表名 set 字段名=字段值,...,字段名=字段值 where 条件
删除数据(delete)
delete from 表名 where 条件
1.5.4、创建表加入约束
常见的约束
- 非空约束,not null
- 唯一约束,unique
- 主键约束,primary key
- 外键约束,foreign key
- 自定义检查约束,check(不建议使用)(在 mysql 中现在还不支持)
建立学生表
create table student(
id int primary key, #int类型的长度限制可以省略不写 id作为主键
student_id char(11) not null unique, #学生学号,唯一且不为空
name varchar(50) not null, #学生姓名,不为空
cno int, #外键 班级id
foreign key(cno) references class(id), #将班级表class的主键id作为该表的外键
unique(student_id,name) #学生学号和姓名联合起来不唯一 约束没有添加在列的后面,这种约束被称为表级约束。
)
1.5.5、增加/删除/修改表约束
1.5.5.1、增加约束
添加外键约束
alter table 从表 add constraint 约束名称 foreign key 从表(外键字段) references 主表(主键字段);
添加主键约束
alter table 表 add constraint 约束名称 primary key 表(主键字段);
添加唯一性约束
alter table 表 add constraint 约束名称 unique 表(字段);
1.5.5.2、删除约束
删除外键约束
alter table 表名 drop foreign 外键字段;
删除主键约束
alter table 表名 drop primary key;
1.5.5.3、修改约束,其实就是修改字段
alter table 表名 modify 字段名 字段类型(长度) 约束;
# mysql 对有些约束的修改时不支持,所以我们可以先删除,再添加
1.6、存储引擎
1.6.1、存储引擎的使用
-
数据库中的各表均被(在创建表时)指定的存储引擎来处理
-
服务器可用引擎依赖于以下因素
- MySQL的版本
- 服务器在开发时如何配置
- 启动选项
-
为了解当前服务器中有哪些储存引擎可用,可以使用SHOW ENGINES 语句查看
SHOW ENGINES\\G -
在创建表时,可使用 ENGINE 选项为 CREATE TABLE 语句显式指定存储引擎
CREATE TABLE 表名 (NOINT) ENGINE = MyISAM; -
如果在创建表时没有显式指定存储引擎,则该表使用当前默认的存储引擎
-
默认的存储引擎可在 my.ini 配置文件中使用 default-storage-engine 选项指定
-
现有表的存储引擎可使用 ALTER TABLE 语句来改变
ALTER TABLE 表名 ENGINE = INNODB; -
为确定某表所使用的存储引擎,可以使用 SHOW CREATE TABLE 或 SHOW TABLE STATUS 语句
SHOW CREATE TABLE 表名\\G SHOW TABLE STATUS LIKE '表名' \\G
1.6.2、常见的存储引擎
1.6.2.1、MyISAM存储引擎
- MyISAM是MySQL最常用的引擎
- 它管理表具有以下三个特征:
- 使用三个文件表示每个表:
- 格式文件:存储表结构的定义(mytable.frm)
- 数据文件:存储表行的内容(mytable.MYD)
- 索引文件:存储表上的索引(mytable.MYI)
- 灵活的AUTO_INCREMENT 字段处理
- 可被转化为压缩、只读来节省空间
- 使用三个文件表示每个表:
1.6.2.2、InnoDB存储引擎
- InnoDB存储引擎是MySQL的缺省引擎
- 它管理的表具有下列主要特征:
- 每个 InnoDB 表在数据库目录中以.frm 格式文件表示
- InnoDB 表空间 tablespace 被用于存储表的内容
- 提供一组用来记录事务性活动的日志文件
- 用 COMMIT(提交)、SAVEPOINT 及 ROLLBACK(回滚)支持事务处理
- 提供全 ACID 兼容
- 在 MySQL 服务器崩溃后提供自动恢复
- 多版本(MVCC)和行级锁定
- 支持外键及引用的完整性,包括级联删除和更新
1.6.2.3、Memory存储引擎
- 使用 MEMORY 存储引擎的表,其数据存储在内存中,且行的长度固定,这两个特点使得 MEMORY 存储引擎非常快
- MEMORY 存储引擎管理的表具有下列特征:
- 在数据库目录内,每个表均以.frm格式的文件表示
- 表数据及索引被存在内存中
- 表级锁机制
- 不能包括TEXT和BLOB字段
- Memory存储引擎以前被称为HEAP引擎
1.6.3、如何选择存储引擎
- MyISAM:适合大量数据读而少量数据更新的混合操作。MyISAM 表的另一种适用情形是使用压缩的只 读表
- InnoDB:如果包含较多的数据更新操作,那么就一个使用InnoDB。其行级锁机制和多版本的支持为数据读取和更新的混合 操作提供了良好的并发机制
- Memory:存储非永久性需要的数据,或者是能够从基于磁盘表中重新生成的数据
1.6.3.1、MyISAM和InnoDB的区别
| 对比项 | MyISAM | InnoDB |
|---|---|---|
| 外键 | 不支持 | 支持 |
| 事务 | 不支持 | 支持 |
| 行表锁 | 表锁,即使操作一条记录也会锁住整个表, 不适合高并发的操作 | 行锁,操作时只锁某一行,不对其它行有影响, 适合高并发的操作 |
| 缓存 | 只缓存索引,不缓存真实数据 | 不仅缓存索引还要缓存真实数据,对内存要求较高,而且内 存大小对性能有决定性的影响 |
| 关注点 | 读性能 | 并发写,事务,资源 |
| 默认安装 | Y | Y |
| 默认使用 | N | Y |
| 自带系统表使用 | Y | N |
1.7、事务
1.7.1、概述
事务可以保证多个操作的原子性,要么全部成功,要么全部失败。对应数据库来说事务保证批量的DML操作要么全部成功要么全部失败。事务有四个特征ACID
- 原子性(Atomicity): 整个事务中的全部操作,必须作为一个单元全部完成(或全部取消)
- 一致性(Consistency): 在事务开始之前和结束之后,数据库都保持一致
- 隔离性(Isolation): 一个事务不会影响其他事务的运行
- 持久性(Durability): 在事务完成后,该事务对数据库所有的更改都会被持久的保存在数据库中,不会被回滚
事务中存在一些概念
事务(Transaction): 一批操作(一组DML操作)
开启事务(start transaction 或者 begin)
回滚事务(rollback)
提交事务(commit)
**SET AUTOCOMMIT: **禁用事务或者启用事务的自动提交模式
执行DML语句就是开启一个事务
关于事务的回滚: 只能回滚insert、update和delete语句,不能回滚select语句(回滚select没有意义),也不能回滚,create、drop和alter语句
事务只对DML语句有效
注意:rollback,或者commit后事务就结束了
1.7.2、事务自动提交模式
自动提交事务模式用户新事物如何级何时启动
- 启用自动提交模式
- 如果自动提交模式被启用,则单条 DML 语句将缺省地开始一个新的事务
- 如果语句执行成功,那么事务自动提交,并永久保存该语句的执行结果
- 如果语句执行失败,那么事务回滚,并取消该语句执行的结果
- 在自动模式下,也可以通过start transaction 或者 begin来显式的开启事务。这时,一个事务仍然可以包括多条语句,直到这些语句被统一提交或者回滚
- 禁用自动提交模式
- 如果禁用自动提交模式,事务可以跨越多条语句
- 这种情况下,事务可以通过commit和rollback显式的提交和回滚
- 自动提交事务可以通过AUTOCOMMIT来控制
- SET AUTOCOMMIT=0 **| NO **禁止自动提交
- SET AUTOCOMMIT=1 **| OFF **开启自动提交
1.7.3、事务的隔离级别
1.7.3.1、隔离级别
事务的隔离级别决定了事务的可见级别
当多个用户并发的访问同一个表时,可能出现下面的一致性问题
- 脏读取(Dirty Read): 一个事务开始读取了某行数据,但是另一个事务已经更新了这行数据但是没有及时提交,这就造成了脏读
- 不可重复读((Non-repeatable Read): 在同一个事务中,同一个读操作对同一个数据的前后两次读取产生了不同的读取结果,这就是不可重复读
- 幻想读(Phantom Read): 幻像读指的是在同一个事务中以前没有的行,由于其它事务的提交而出现的新行
1.7.3.2、事务的四个隔离级别
InnoDB实现了四个隔离级别,用于控制事务所做的修改,并将修改的通告告知其它事务
- 读未提交(READ UMCOMMITTED): 允许一个事务可以看到其它事务未提交的修改
- 读已提交(READ COMMITTED): 允许一个事务可以看到其它事务已提交的修改,不能查看未提交的修改
- 可从复读(REPEATABLE READ): 确保一个事务中执行两次相同的select语句,都能得到相同的结果,不管其它事务是否提交了这些修改(银行总账)
- 串行化(SERIALIZABLE): 将一个事务于其它事务完全隔离
1.7.3.3、隔离级别与一致性问题的关系
| 隔离级别 | 脏读取 | 不可重复读 | 幻像读 |
|---|---|---|---|
| 读未提交 | 可能 | 可能 | 可能 |
| 读已提交 | 不可能 | 可能 | 可能 |
| 可重复读 | 不可能 | 不可能 | 对于InnoDB不可能 |
| 串行化 | 不可能 | 不可能 | 不可能 |
1.7.3.4、设置服务器缺省隔离级别
通过修改配置文件配置
可以在my.ini文件中使用transaction-isolation选项来设置服务器缺省事务级别
改选项值可为
- READ-UNCOMMITTED
- READ-COMMITTED
- REPEATABLE-READ
- SERIALIZABLE
例如
transaction-isolation = READ-COMMITTED
通过命令动态设置隔离级别
隔离级别可以在运行的服务器中动态设置,使用SET TRANSACTION ISOLATION LEVEL 语句设置
语法为
TRANSACTION ISOLATION LEVEL <isolation-level>
其中isolation-level可以为
- READ UNCOMMITTED
- READ COMMITTED
- REPEATABLE READ
- SERIALIZABLE
例如
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;
set transaction isolation level repetable read;
1.7.3.5、隔离级别的作用范围
事务的隔离级别的作用范围分为两种:全局级,会话级
全局级: 对所有的会话有效
会话级: 对当前的会话有效
设置全局隔离级别的语法
set global transaction isolation level 隔离级别
设置会话级别的语法
set session transaction isolation level 隔离级别
1.7.3.6、查看隔离级别
服务器变量tx_isolation(包括会话级和全局级两个变量)中保存着当前的会话隔离级别
查看会话级当前隔离级别
select @@tx_isolation;
select @@session.tx_isolation;
查看全局级当前隔离级别
select @@global.tx_isolation;
1.8、索引
1.8.1、索引的概念
MySQL 官方对索引的定义为: 索引(Index)是帮助 MySQL 高效获取数据的数据结构。可以得到索引的本质: 索引是数据结构。可以简单理解为排好序的快速查找数据结构
一般来说索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储在磁盘上
1.8.1.1、索引的优缺点
优点
- 提高数据的检索效率,降低数据库的IO成本
- 通过索引列对数据进行排序,降低数据排序的成本,降低了CPU的消耗
缺点
- 虽然大大的提交高了数据的查询效率,但是会降低更新表的速度。因为当对表进行DML操作时,索引也需要动态维护,降低了数据的维护速率
- 实际上索引也是一张表,该表保存了主键于索引字段,并指向实体表的记录,所以索引列也是要占用空间的
1.8.2、MySQL的索引类型
从数据结构层次来看有以下几种
- B-Tree索引
- 哈希索引
- R-Tree索引
- 全文索引
从物理层面来看有以下几种
- 主键索引(聚簇索引):叶子节点存储的是整行的数据
- 非主键索引(二级索引):叶子节点存储着主键的值
1.8.2.1、B-Tree索引
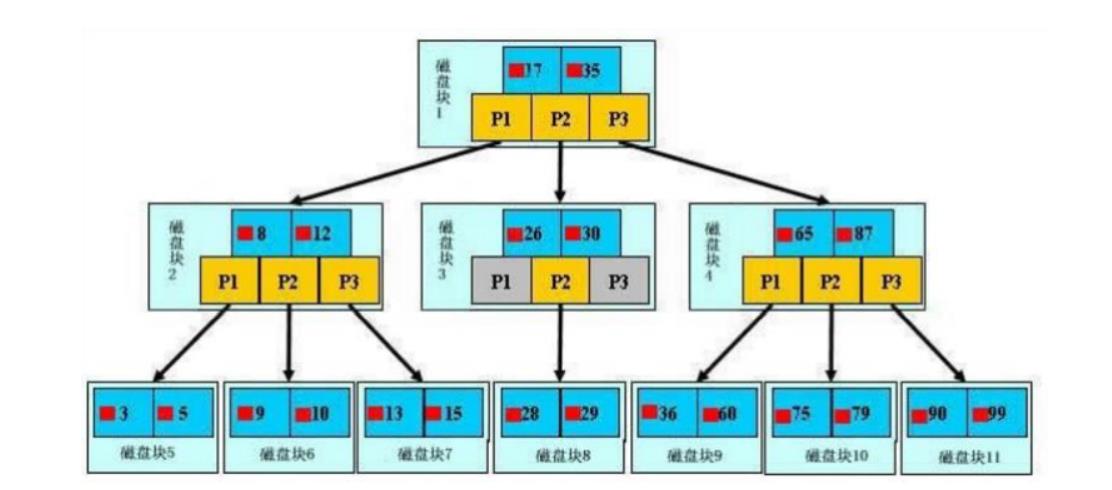
初始化介绍
一颗 b 树,浅蓝色的块我们称之为一个磁盘块,可以看到每个磁盘块包含几个数据项(深蓝色所示)和指针(黄色 所示)
如磁盘块 1 包含数据项 17 和 35,包含指针 P1、P2、P3, P1 表示小于 17 的磁盘块,P2 表示在 17 和 35 之间的磁盘块,P3 表示大于 35 的磁盘块
真实的数据存在于叶子节点即 3、5、9、10、13、15、28、29、36、60、75、79、90、99
非叶子节点只不存储真实的数据,只存储指引搜索方向的数据项,如 17、35 并不真实存在于数据表中
查找数据的过程
从上往下找,从根节点依次往下寻找数据
这样只需要三次IO操作,三层的b树可以表示上百万的数据,如果三百万的数据只需要三次IO操作,那么这个对于性能的提升是巨大的
如果没有索引,每个数据项都需要一次IO操作,那么可能总需要百万次的IO操作,显然成本是非常之高的
1.8.2.2、B+Tree
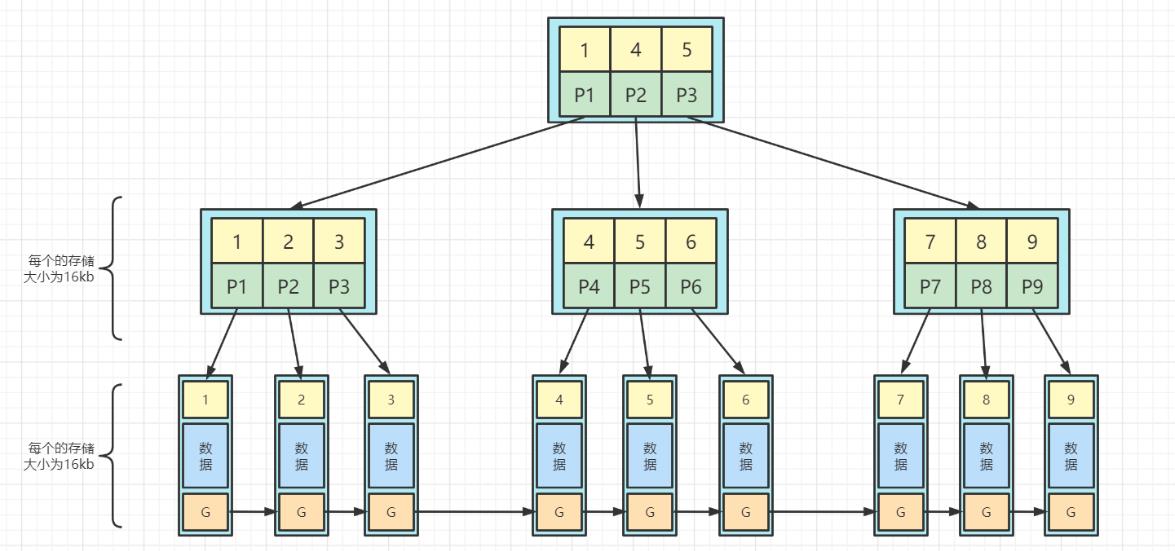
b-tree和b+tree的区别
- b-tree树的关键字和数据是放在一起的,叶子节点和非叶子节点都存在。而b+tree树非叶子节点只存在关键字和指向下一个节点的索引,数据只放在叶子节点中
- b+tree中间节点不房数据,所以在同样大小的磁盘页上,可以容纳更多的节点元素,并且数据顺序排列且相连,所以便于区间从查找和搜索
B+树比 B-树更适合实际应用中操作系统的文件索引和数据库索引是因为
- B+树的磁盘读写代价更低
- B+树的查询效率更加稳定
1.8.3、聚簇索引和非聚簇索引
聚簇索引并不是一种单独的索引类型,而是一种数据存储的方式。术语 “聚簇” 表示数据行和相邻的键值聚簇的存储在一起。
一张表只能有一个聚簇索引,聚簇索引要比非聚簇索引的查询效率高很多,尤其是范围查询的时候
一般情况下主键会默认创建聚簇索引,且一张表只能存在一张聚簇索引
聚簇索引的好处: 按照聚簇索引排列顺序,查询显示一定范围数据的时候,由于数据都是紧密相连,数据库不不用从多 个数据块中提取数据,所以节省了大量的 io 操作
聚簇索引的限制: 对于MySQL数据库而言,目前只有InnoDB数据引擎支持聚簇索引,而MyISAM数据引擎不支持,由于物理存储排序方式只有一种,所以每个MySQL的表只能有一个聚簇索引。一般情况下就是该表的主键
1.8.4、索引的分类
单值索引: 一个索引只包含单个列,一个表可以有多个单列索引
create index 索引名 on 表名(字段名) #创建单值索引
alter table 表名 add index 索引名 (字段)
唯一索引: 索引列的值必须唯一,但是允许有空值
create unique index 索引名 on 表名(字段名) #创建唯一索引
alter table 表名 add unique 索引名(字段名)
主键索引: 设置主键后数据库会自动建立索引,InooDB为聚簇索引
alter table 表名 add primary key(字段名) #创建主键索引
复合索引: 一个索引包含多个列
create index 索引名 on 表名(字段名,...,字段名) #创建复合索引
alter table 表名 add index 索引名(字段名,...,字段名)
基本语法
show index from 表名\\G #查看表中的索引
dorp index 索引名 on 表名 #删除索引
alter table 表名 drop index 索引名 #删除索引
alter table 表名 drop index primary key #删除主键索引,一张表中只有一个主键索引
1.8.5、索引的创建时机
适合创建索引的时机
- 主键自动创建索引
- 频繁作为查询条件的字段应该创建索引
- 查询中与其它表关联的字段,外键关系创建索引
- 单键/组合索引的选择问题, 组合索引性价比更高
不适合创建索引的时机
- 表记录太少
- 经常增删改的表或者字段
- where条件里用不到的字段不创建索引
- 过滤性不好的不适合创建索引
1.8.6、Explain性能分析
使用 EXPLAIN 关键字可以模拟优化器执行 SQL 查询语句,从而知道 MySQL 是如何处理你的 SQL 语句的。分 析你的查询语句或是表结构的性能瓶颈
explain sql语句
查询返回的信息

1.8.6.1、Explain的关键字段
type: 表示连接的类型,从好差的类型排序为
- system:系统表,数据已经加载到内存里
- const:常量连接,通过索引一次就找到
- eq_ref:唯一性索引扫描,返回所有匹配某个单独值的行
- ref:非主键非唯一索引等值扫描,const或eq_ref改为普通非唯一索引
- range:范围扫描,在索引上扫码特定范围内的值
- index:索引树扫描,扫描索引上的全部数据
- all:全表扫描
Key: 显示MySQL实际决定使用的键
Key_len: 显示MySQL使用键的长度,键长越短越好
Extra: 额外信息
- Using filesort:MySQL使用外部的索引排序,很慢需要优化
- Using temporary:使用了临时表保存中间结果,很慢需要优化
- Using index:使用了覆盖索引
- Using where:使用了where
1.9、视图
视图是一种根据查询(也就是 SELECT 表达式)定义的数据库对象,用于获取想要看到和使用的局部数据
视图有时也被称为 “虚拟表”
视图可以被用来从常规表(称为“基表”)或其他视图中查询数据
相对于从基表中获取数据,视图可以
- 访问数据变得简单
- 可被用于对不同的用户显示不同的表的内容
视图的作用:
- 提高检索效率
- 隐藏表的实现细节
创建视图
create view 视图名 as 查询语句; // 注意子查询创建视图不被支持
删除视图
drop view 视图名
1.10、数据库三大范式
1.10.1、第一范式
数据表中不能出现重复记录,每个字段是原子性不可再分的
关于第一范式,每一行必须唯一,也就是每个表必须有主键,这是我们数据库设计的最基本要求
1.10.2、第二范式
第二范式是建立在第一范式基础上的,另外要求所有非主键字段完全依赖主键,不能产生部分依赖
如果一个表是单一主键,那么它就符合第二范式,部分依赖和主键有关系
1.10.3、第三范式
建立在第二范式基础上的,非主键字段不能传递依赖于主键字段(不要产生传递依赖)
1.10.4、三范式总结
第一范式: 有主键,具有原子性,字段不可割分
第二范式: 完全依赖,没有部分依赖
第三范式: 没有传递依赖
数据库设计尽量遵循三大范式,但是还是要根据实际情况来进行取舍,有时候会拿冗余换速度,最终的目的是为了满足客户需求
以上是关于MySQL总结的主要内容,如果未能解决你的问题,请参考以下文章