使用InflubDB和Grafana监控Flink
Posted 博而不客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用InflubDB和Grafana监控Flink相关的知识,希望对你有一定的参考价值。
Influxdb和Grafana安装不在这里赘述,直接介绍flink的配置。
一、创建InfluxDB数据库
因为我们需要将采集的metrics数据保存到influxdb中,所以我们首先需要创建一个数据库,create databases flinkonyarn
默认情况下,influxdb在刚安装好之后,禁用身份验证,静默忽略所有凭据,并且所有用户都具有所有权限,这样是极不安全的。在开启身份验证之后,创建相应的用户和对应的密码
二、配置flink文件
修改配置文件 conf/flink-conf.yaml 在最后面增加以下
metrics.reporter.influxdb.class: org.apache.flink.metrics.influxdb.InfluxdbReporter
metrics.reporter.influxdb.host: xx.xx.xx.xx
metrics.reporter.influxdb.port: 8086
metrics.reporter.influxdb.db: flinkonyarn
metrics.reporter.influxdb.username: admin
metrics.reporter.influxdb.password: admin
class:这个是固定的
host:这个是安装 InfluxDB 的 host 地址
port:这个是 InfluxDB 的端⼝口,默认是 8086
db:表示你要将 metrics 数据存⼊入到 InfluxDB 的哪个数据库
username:InfluxDB 的⽤用户名
password:InfluxDB 的密码
配置完以上两步,新提交的flink任务产生的metrics数据就会写入到influxdb中,我们可以看有没有对应的表产生
use flinkonyarn
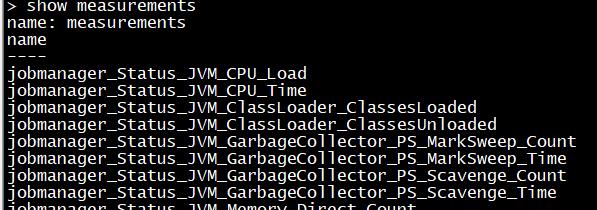
show measurements
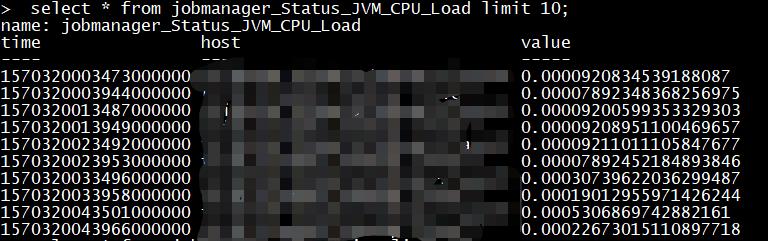
查看表数据 select * from jobmanager_Status_JVM_CPU_Load limit 10;
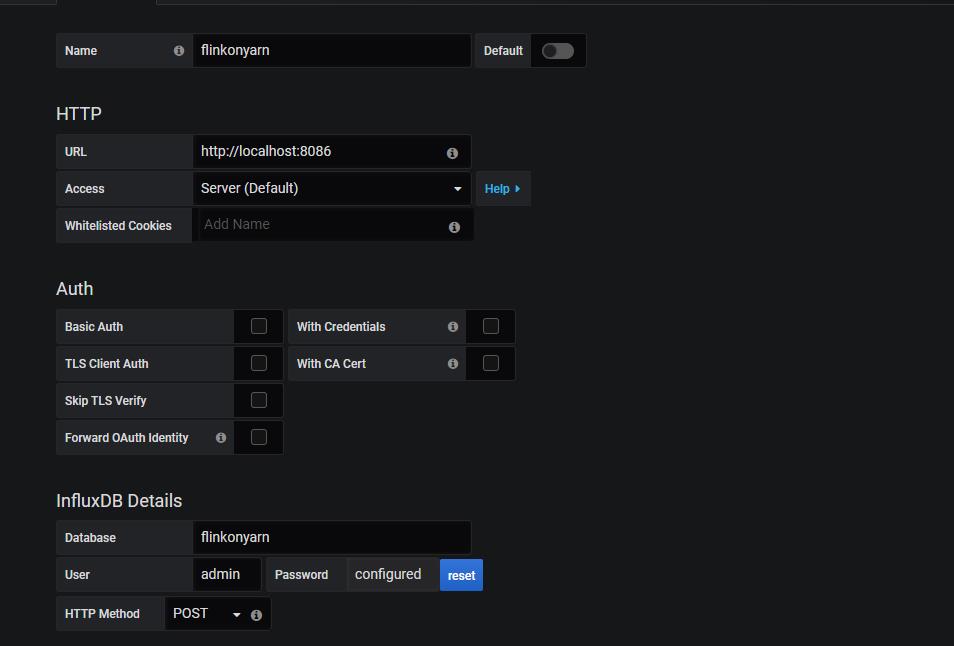
三、增加Grafana数据源
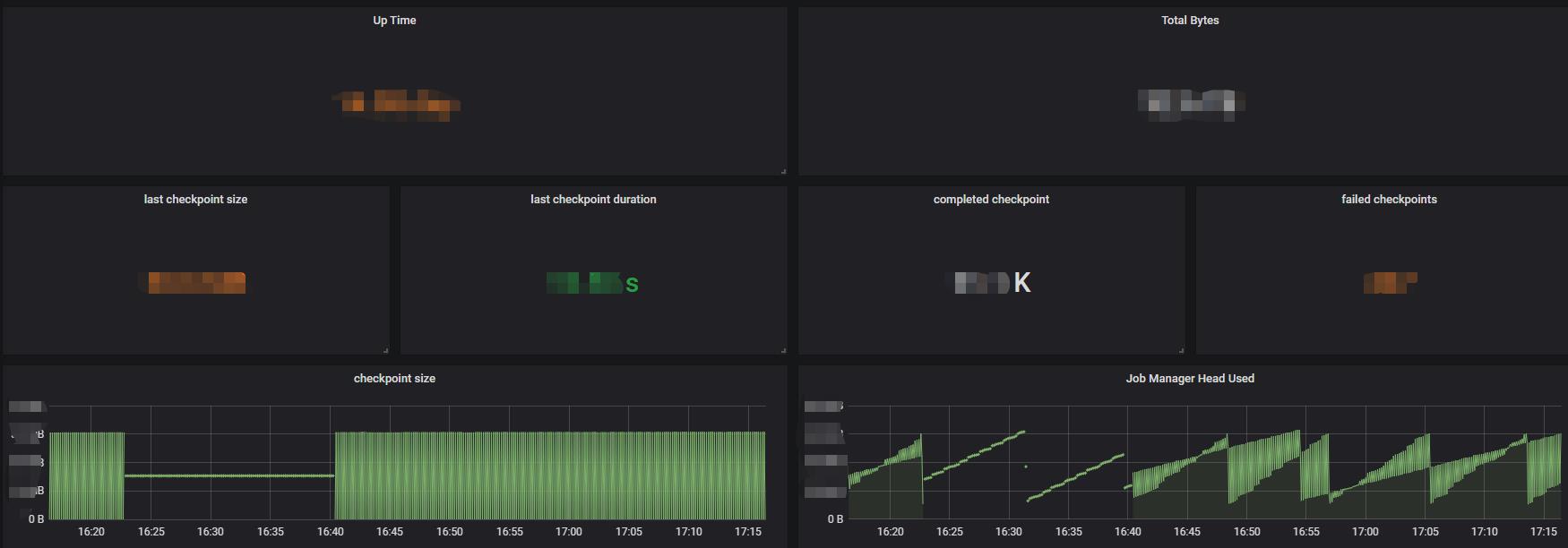
所有这些弄好后,就可以配置图表了。
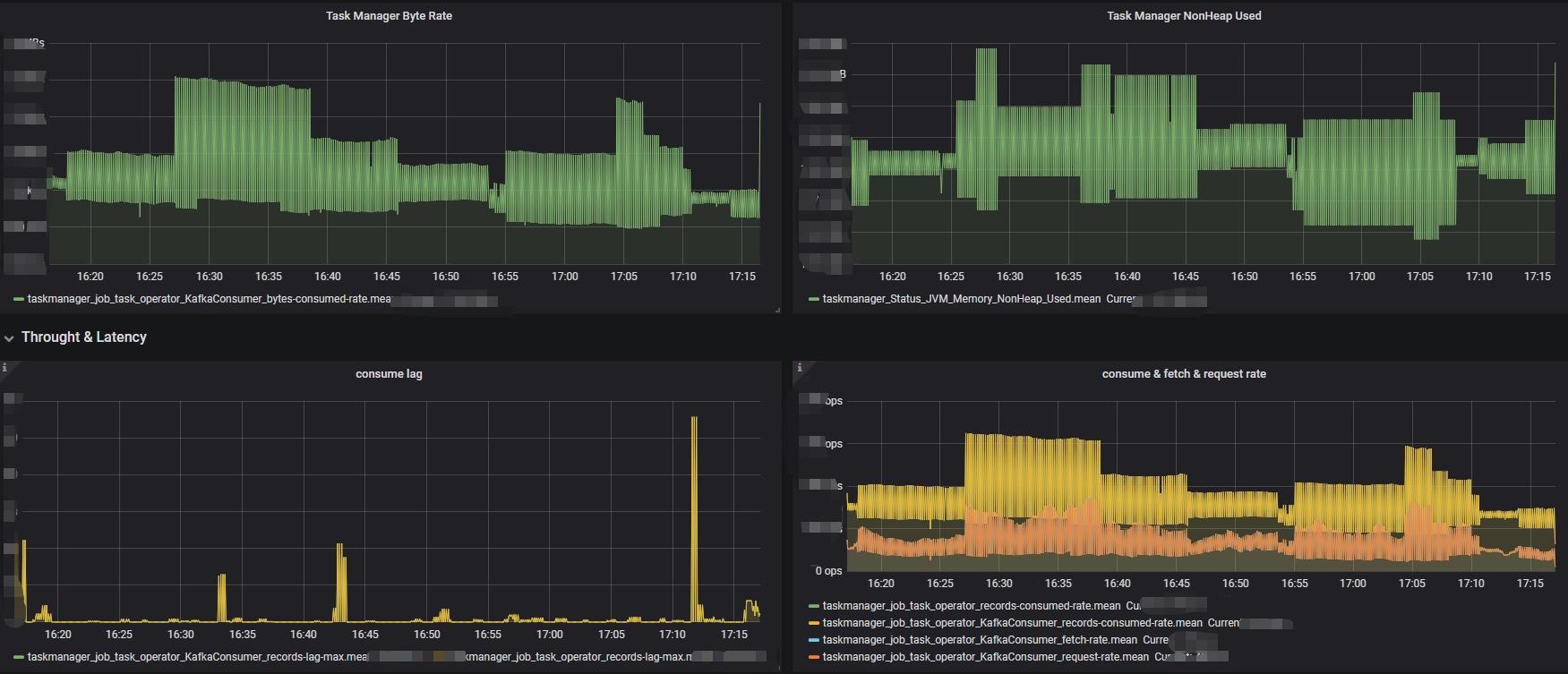

以上是关于使用InflubDB和Grafana监控Flink的主要内容,如果未能解决你的问题,请参考以下文章
Windows_安装整合Prometheus + Grafana监控主机和Flink作业
Flink 监控系列Flink 自定义 kafka metrics reporter 上报 metrics 到 kafka
Flink 监控系列Flink 自定义 kafka metrics reporter 上报 metrics 到 kafka