深入理解mysql事务
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入理解mysql事务相关的知识,希望对你有一定的参考价值。
做为开发人员对数据库事务应该都不陌生,但是如果知其然而不知其所以然的话,在开发中难免写出来的代码存在bug,本文主要介绍mysql中的事务,重点讲解事务的隔离级别。1. ACID
1.1 原子性
原子性是指事务是一个不可分割的工作单位,事务中的操作要么全部执行,要么全部都不执行。
例如:
begin // 开启事务
A:update user set account=account+1 where id =1;
B:update user set account=account+1 where id =1;
commit
这个事务,执行commit时,在么两条语句都执行成功,如果出错,执行rollback时,两条语句的操作都会回滚到原始状态;
undo log保证原子性
在操作任何数据之前,首先将数据备份到一个地方(这个存储数据的地方就是undo log)。然后进行数据的修改,如果用户出现了错误或者用户执行了rollback语句,系统可用利用undo log中的备份的数据恢复到事务开始之前的状态。
注意:undo log是逻辑日志
可以理解为:
- 当delete一条记录时,undo log中记录一条对应的insert记录
- 当insert 一条记录时,undo log中会记录一条对应的delete记录
- 当update一条记录时,它记录一条对应相反的udpate记录
1.2 一致性
事务执行前和事务执行后,数据库的完整性约束不被破坏。即事务的执行是从一个有效状态转移到另一个有效状态;
例如:
tom给jack转账50元,如果从tom账户减少后系统故障或其它原因没有给jack加上50元,而事务还没有执行完毕,数据库会将整个转账过程回滚,保证数据的一致性;1.3 隔离性
隔离性是指在并发操作中,不同事务之间应该隔离开来,使每个并发中的事务不会互相干扰;
1.4 持久化
一旦事务提交成功,事务中所有的数据操作都必须被持久化保存到数据库中,即使提交事务后,数据库崩溃,在数据库重启时,也必须能保证通过某种机制恢复数据。
redo log保证持久性
redo log记录的是新数据的备份,在事务提交前,只要将redo log持久化即可,不需要将数据持久化。当系统崩溃时,虽然数据没有持久化,但是redo log已经持久化,系统可以根据redo log的内容,将所有数据恢复到最新的状态。2. 事务引起的问题
上面介绍了数据库的事务特性,其中隔离性,是我们本文中重点需要解说的,设置不同的数据库事务之间的隔离级别,会解决相应的事务并发问题。那么下面说一下事务都会引起哪些问题:
2.1 脏读
事务A读取到了事务B已经修改但尚未提交的数据,如果事务B回滚,A读取的数据与上次不一致;不符合事务的一致性要求;
例如:A(图左)和B(图右)同时开启事务,A执行如下命令: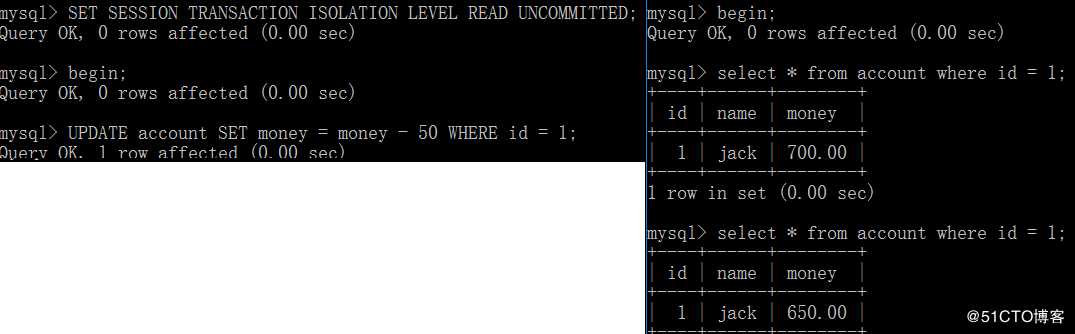
用户A并未提交事务,可见在事务B中两次查询的结果已经发生变化,读取了事务A中未提交的数据;
2.2 不可重复读
事务A读取到了事务B已经提交的修改数据,不符合隔离性;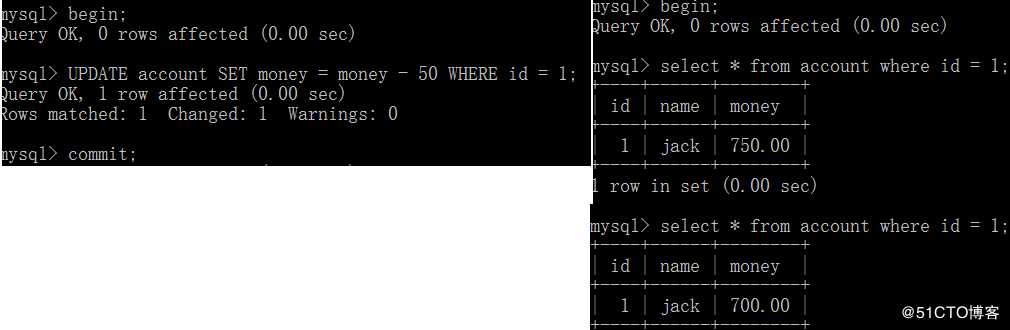
上图可见,事务B读取到了事务A所修改的数据;
2.3 幻读
事务A读取到了事务B提交的新增数据,不符合隔离性;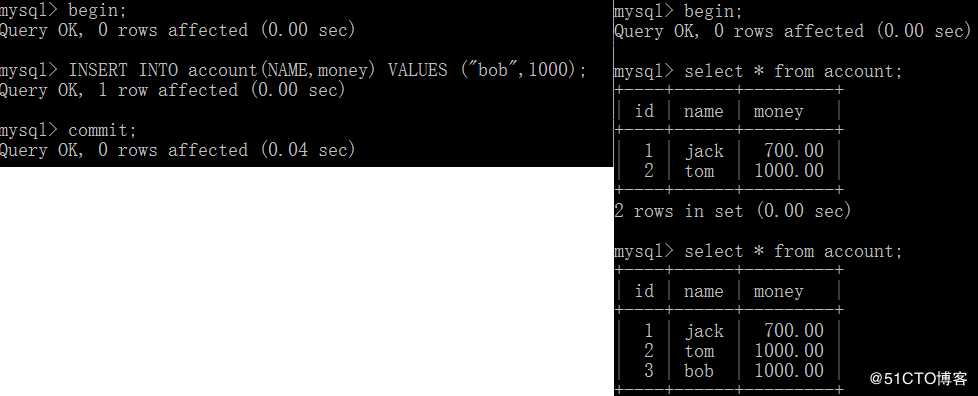
事务B读取到了事务A提交的新增数据;
3. 深入隔离级别
隔离级别等级:
查看隔离级别:
show variables like ‘%isolation%‘;
SELECT @@GLOBAL.transaction_isolation, @@transaction_isolation;设置隔离级别:
全局:SET GLOBAL TRANSACTION ISOLATION LEVEL REPEATABLE READ;
会话:SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;3.1 读未提交
读未提交是数据库事务隔离级别最低的级别,它任何问题都没有解决;
设置数据库事务隔离级别为读未提交
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;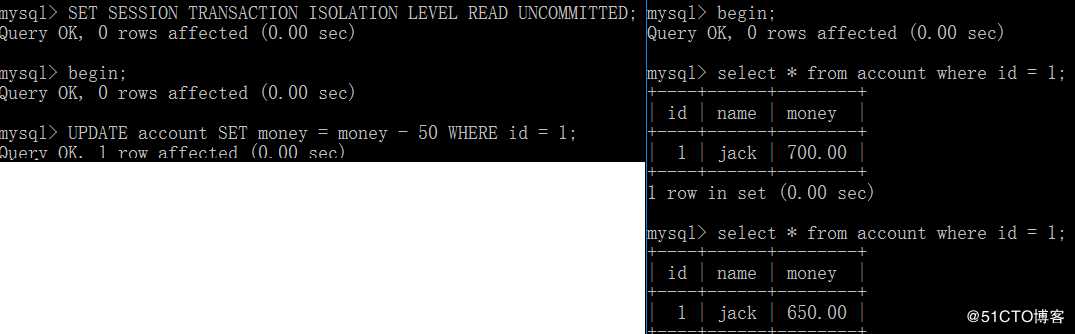
3.2 读已提交
读已提交它主要解决脏读的问题;
设置数据库事务隔离级别为读已交
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;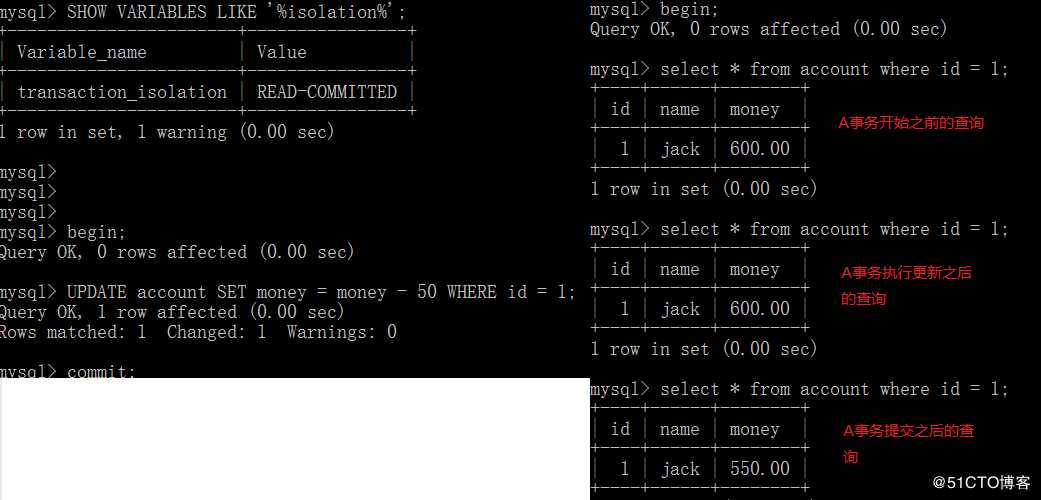
可以看出,读已提交已经解决了脏读的问题;
3.3 可重复读
设置事务隔离级别:
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;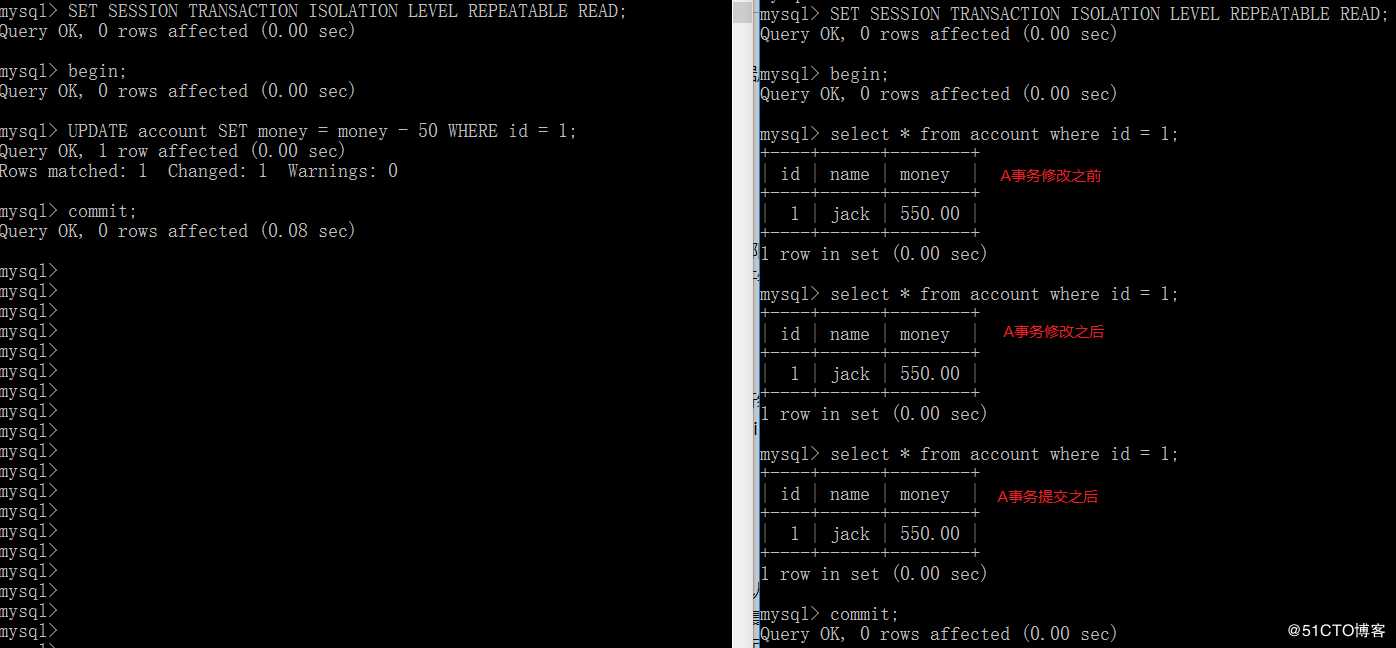
可以看到,就算事务A已经提交,事务B也不会再读到事务A提交的数据;
那么可重复读是否解决了幻读呢?
我们试验一下: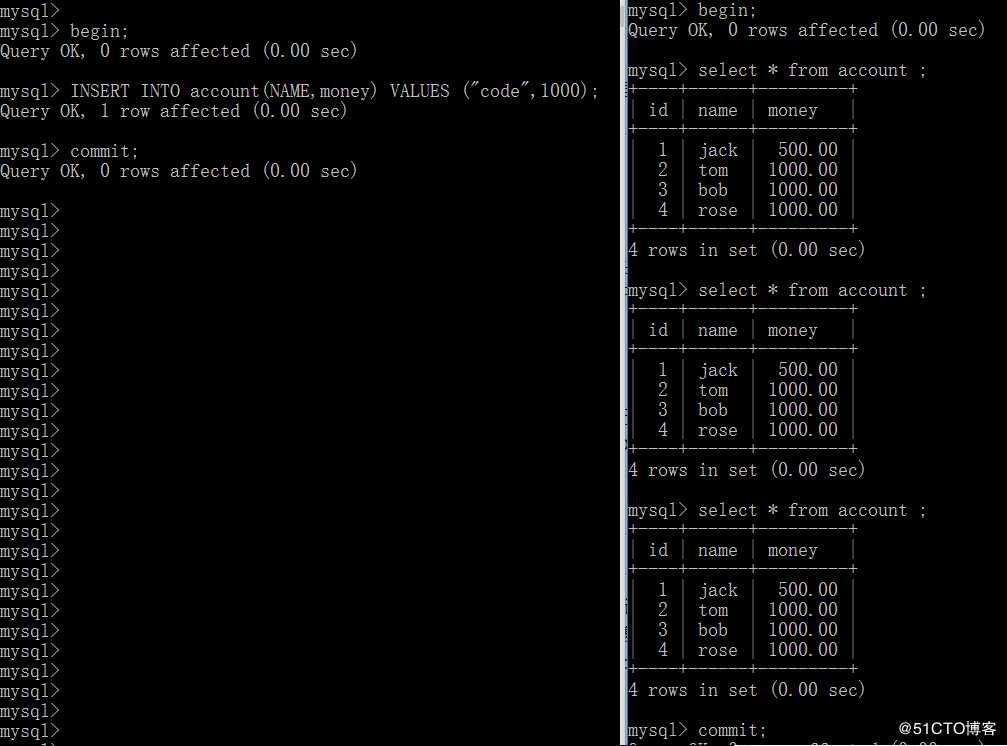
这是怎么回事呢?不是说好的可重复读不会解决幻读的问题吗?为什么这里新插入的数据就是没有在事务B中读取到呢? (下节解答)
3.4 串行化
串行化就不多说了,它其实是将事务按排队的处理方式,但是这样会使事务非常低率的。
4. mysql的MVCC
我们先来看个示例: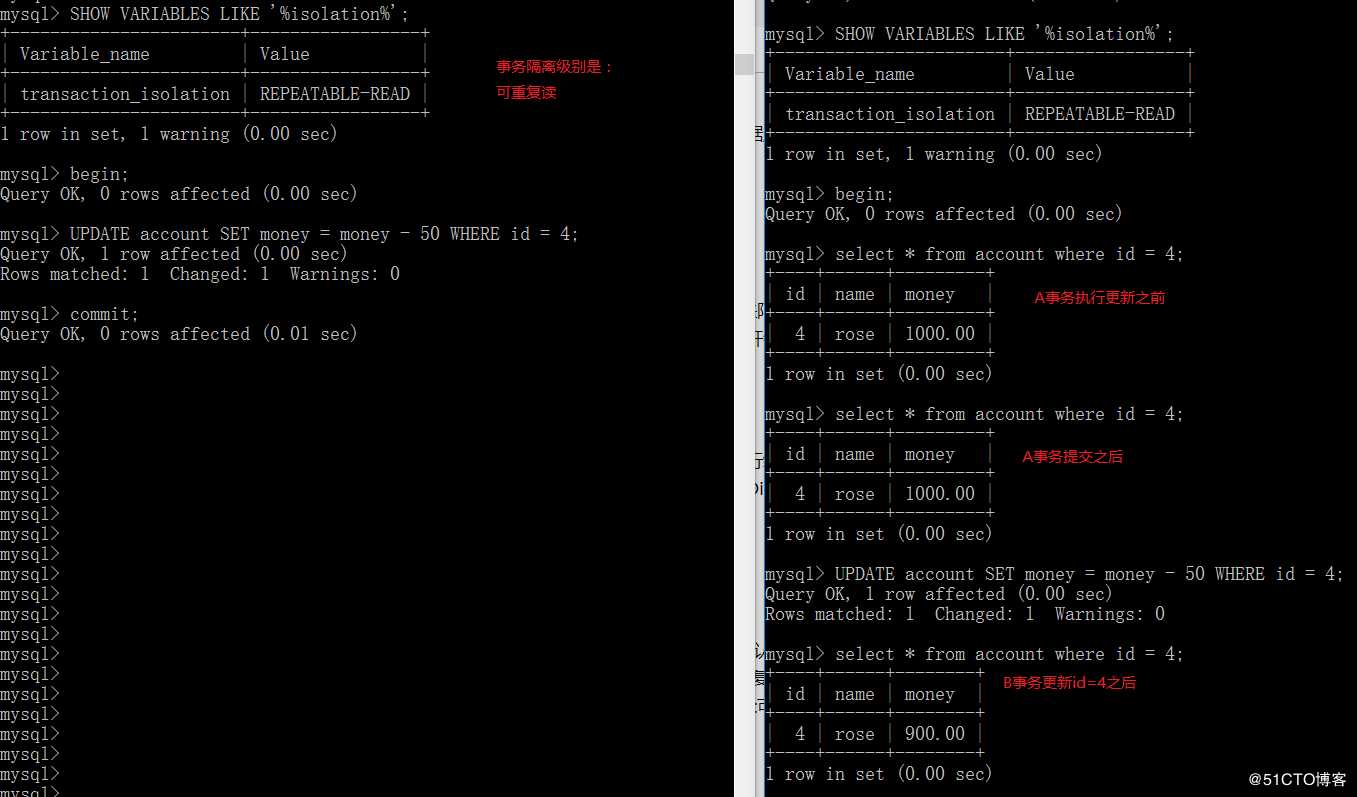
从上面的执行过程可以看出,在A事务提交之后,B事务虽然执行查询时没有 问题,但是在B事务执行更新之后,再查询时,账户直接少了100;这是为什么呢?
1) MVCC原理
InnoDB的MVCC通过每行记录后面的两个隐藏字段来实现的,创建时的版本号和删除时的版本号。每个事务开始版本号都会递增。
SELECT:
- 查找版本早于当前事务版本的数据行,即,行的系统版本号小于或等于事务的系统版本号,这样可以确保事务读取的行,是在事务开始之前已经存在的或者自身事务操作过的。
- 行的删除版本,要么未定义,要么大于当前事务版本号,这样可以确保事务读取到的行,在事务开始之前未被删除;
INSERT:
为插入的每一行保存当前系统版本号作为行的版本号;
DELETE:
删除的每行保存当前系统版本号作为删除标记;
UPDATE:
插入一行新记录,保存当前系统版本号为行版本号,同时,保存当前系统版本号到原来的行的删除标识;
2) 快照读和当前读
快照读:
读取的是快照版本,也就是历史版本;普通的select就是快照读
当前读:
读取的是最新版本,update、delete、insert、select...lock in share mode、select ... for update是当前读;
3.3节疑惑解答
事务A执行更新之后,提交了事务,而事务B再执行更新的时候,它其实是一个当前读,能够读取到最新的已经被事务A修改后的数据(前提事务A已经提交)。
3) undo log中的版本链及ReadView
这块内容比较复杂,可以参考:
https://blog.csdn.net/shenchaohao12321/article/details/92801779
以上是关于深入理解mysql事务的主要内容,如果未能解决你的问题,请参考以下文章