基础架构
平时我们使用数据库,看到的通常都是一个整体, 例如下面:
mysql> select * from t where id=1;
我们看到的只是输入一条语句,返回一个结果,那么这条语句在MySQL内部的执行过程是如何的呢?
下面是mysql的经典架构图
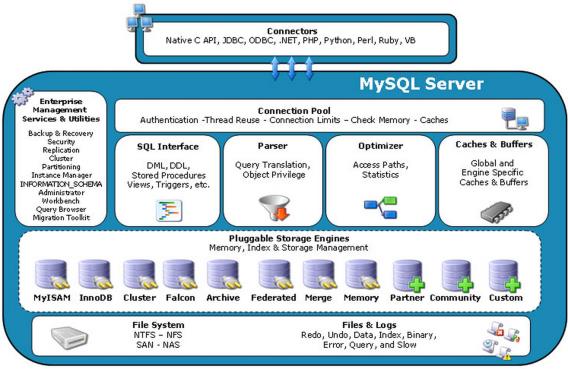
大致可以分为4层:
- 连接层
最上层是一些客户端和连接服务,包含本地socket和大多数基于客户端/服务端工具实现的类似于tcp/ip的通信,主要完成一些类似连接处理,授权认证,及相关的安全方案,在该层引入线程池的概念,为通过认证安全接入的客户端提供线程,同样在该层上可以实现基于SSL的安全链接,服务器也会为安全接入的每个客户端验证它所具备的操作权限。 - 服务层
第二层架构主要完成大多数的核心服务功能,如SQL接口,并完成缓存查询,SQL的分析和优化及部分内置函数的执行,所有跨存储引擎的功能也在这一层实现,如过程,函数等,在该层,服务层会解析查询并创建相应的内部解析树,并对其完成响应的优化确认查询表的顺序,是否利用索引等,最后生成相应的执行操作,如果是select语句,服务器还会查询内部的缓存,如果缓存空间足够大,这样就解决大量读操作的环境中能够很好的提供系统性能。 - 存储引擎层
存储引擎层,存储引擎真正负责了MySQL中数据的存储和提取,服务器通过API与存储引擎进行通信,不同的存储引擎具有的功能不同,这样我们可以根据自己的实际需要进行选取,例如:MYISAM和InnoDB。 - 数据存储层
主要将数据存储在运行于裸设备的文件系统之上,并完成存储引擎的交互(文件系统)。
上面给出的是比较笼统的概念。接下来是根据mysql实战45讲里第一讲的内容的一些总结。
下面这张mysql逻辑架构图会更加清晰。

连接器
想要执行sql语句的第一步就是需要选用一个客户端来连接上mysql服务器, 这个客户端可以是各种语言,抑或是mysql的原生端, 只要实现mysql的基本通信协议即可。我们首先需要做的就是使用账号密码连接:
- 如果用户名或密码不对,你就会收到一个"Access denied for user"的错误,然后客户端程序结束执行。
- 如果用户名密码认证通过,连接器会到权限表里面查出你拥有的权限。之后,这个连接里面的权限判断逻辑,都将依赖于此时读到的权限。
查询缓存
连接建立完成后, 可以选用相应的库, 执行select语句。
mysql拿到一个查询请求后,会先到查询缓存看看,之前是不是执行过这条语句。之前执行过的语句及其结果可能会以key-value对的形式,被直接缓存在内存中。如果当前查询能够直接在这个缓存中找到,那么就会被直接将结果返回给客户端。
如果语句不在查询缓存中,就会继续后面的执行阶段。执行完成后,执行结果会被存入查询缓存中。如果查询命中缓存,MySQL不需要执行后面的复杂操作,就可以直接返回结果,这个效率会很高, 和redis缓存的原理如出一辙。
但是大多数情况下最好不要使用查询缓存,为什么呢?因为查询缓存往往弊大于利。
查询缓存的失效非常频繁,只要有对一个表的更新,这个表上所有的查询缓存都会被清空。 因此很可能费劲地把结果存起来,还没使用呢,就被一个更新全清空了。对于更新压力大的数据库来说,查询缓存的命中率会非常低。除非业务就是有一张静态表,很长时间才会更新一次。比如,一个系统配置表,那这张表上的查询才适合使用查询缓存。
需要注意的是,MySQL 8.0版本直接将查询缓存的整块功能删掉了,也就是说8.0开始彻底没有这个功能了。
分析器
如果没有命中查询缓存,就要开始真正执行语句了。首先,MySQL需要知道我们要做什么,因此需要对SQL语句做解析。
分析器先会做“词法分析”。我们输入的是由多个字符串和空格组成的一条SQL语句,MySQL需要识别出里面的字符串分别是什么,代表什么,然后去执行相应的命令。
例如我们输入select * from t where id = 1; 就会根据select识别出是查询, from t 识别出是表t,如果我们输入有误,出现常见的语法错误,就会报You have an error in your SQL syntax的错误, 需要在use near...里找寻错误。
优化器
经过了分析器, mysql知道了我们的目的,但在执行之前, 还需要进行过一步优化处理。
说白点就是优化客户端请求的 query语句 , 优化器是在表里面有多个索引的时候,会决定使用哪个索引;或者在一个语句有多表关联(join)的时候,决定各个表的连接顺序。 它会根据客户端请求的 query 语句,和数据库中的一些统计信息,在一系列算法的基础上进行分析,得出一个最优的策略,告诉后面的程序如何取得这个 query 语句的结果,优化器就相当于大脑,在这一步已经决定了接下来都该如何去执行的具体策略。
例如执行select uid,name from user where gender = 1;
首先这个select 查询会根据where 语句进行选取,而不是先将表全部查询出来以后再进行gender过滤,接着这个select查询先根据uid和name进行属性投影,而不是将属性全部取出以后再进行过滤。最后将这两个查询条件联接起来生成最终查询结果。
执行器
到了执行器,已经明确知道了该如何执行相应语句了。 开始执行的时候,要先判断一下该连接对这个表有没有执行查询的权限,如果没有,就会返回没有权限的错误(在工程实现上,如果命中查询缓存,会在查询缓存放回结果的时候,做权限验证。查询也会在优化器之前调用precheck验证权限)。
如果有权限,就打开表继续执行。打开表的时候,执行器就会根据表的引擎定义,去使用这个引擎提供的接口。
比如查询select * from t where id = 1;
假如在这个例子中, id字段没有索引,那么执行器的执行流程是这样的:
- 调用
InnoDB引擎接口取这个表的第一行,判断id值是不是10,如果不是则跳过,如果是则将这行存在结果集中; - 调用引擎接口取“下一行”,重复相同的判断逻辑,直到取到这个表的最后一行。
- 执行器将上述遍历过程中所有满足条件的行组成的记录集作为结果集返回给客户端。
至此,这个语句就执行完成了。
对于有索引的表,执行的逻辑也差不多。第一次调用的是“取满足条件的第一行”这个接口,之后循环取“满足条件的下一行”这个接口,这些接口都是引擎中已经定义好的。
上面就是一条mysql中一条sql语句的全部了.