GreenPlum tidb 性能比较
Posted 大数据之路
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GreenPlum tidb 性能比较相关的知识,希望对你有一定的参考价值。
主要的需求
针对大体量表的OLAP统计查询,需要找到一个稳定,高性能的大数据数据库,具体使用
- 数据可以实时的写入和查询,并发的tps不是很高
- 建立数据仓库,模式上主要采用星星模型、雪花模型,或者宽表
- 前端展示 分为3类 saiku、granafa、c#代码开发
- 数据体量:事实表在3-5亿、维度表大的在500万左右
- 数据集成:可以和现在使用的kettle进行无缝集成
基于以上需求,前期使用tidb,但是在大体量表的olap查询性能不是很好,使用tipark 离线计算还可,但是时间上无法满足系统需求,初步了解到mpp架构的greenplum。因此先期进行了简单比较
基础测试数据表说明
数据表
订单宽表,数据表字段为300个左右
基本的测试结果 --不包含并发测试
集群基本配置 :
Greenplum 4台8核56G,9个segments 表:列存,无索引
tidb :6台8核56G,ssd
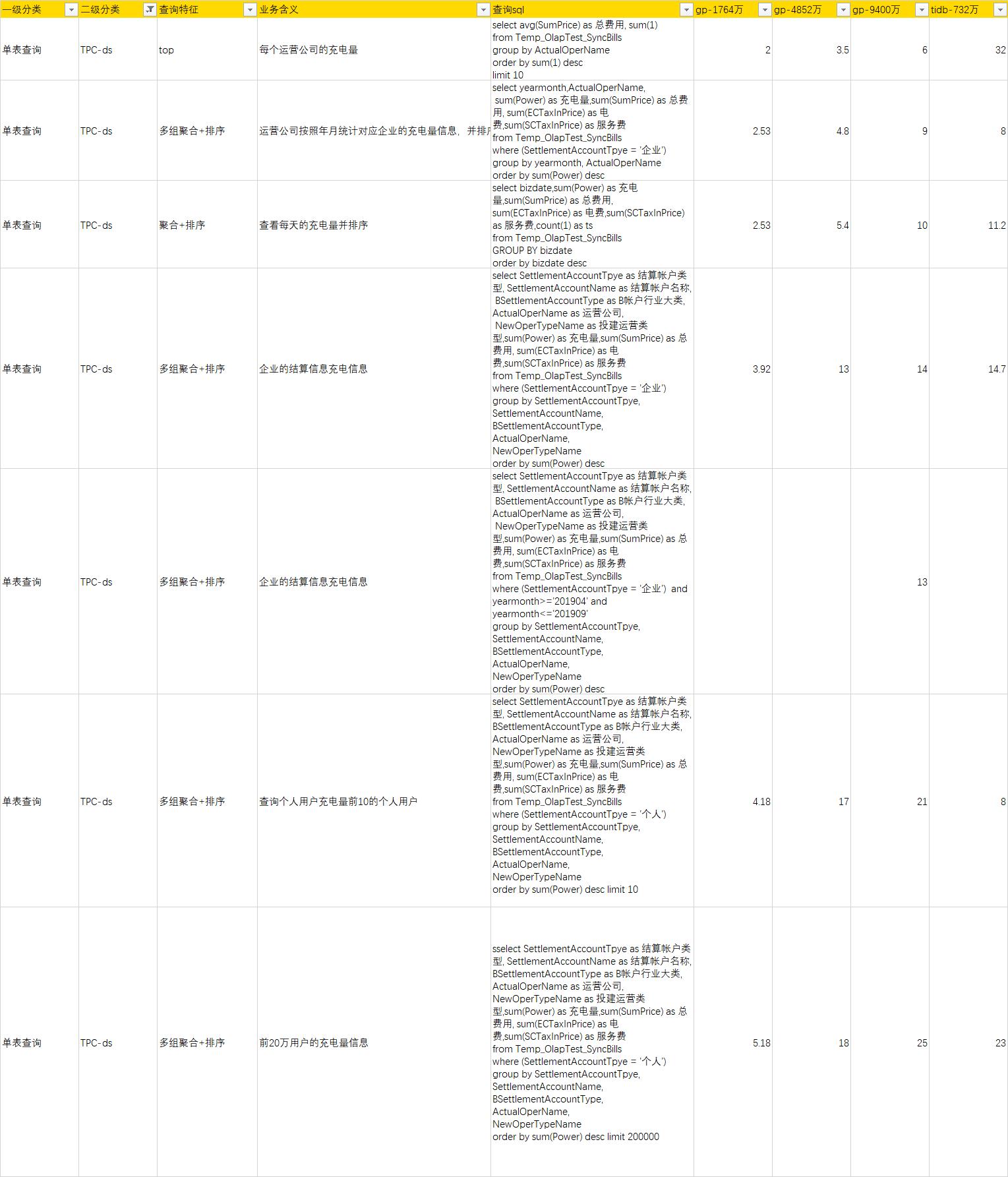
tpc-ds
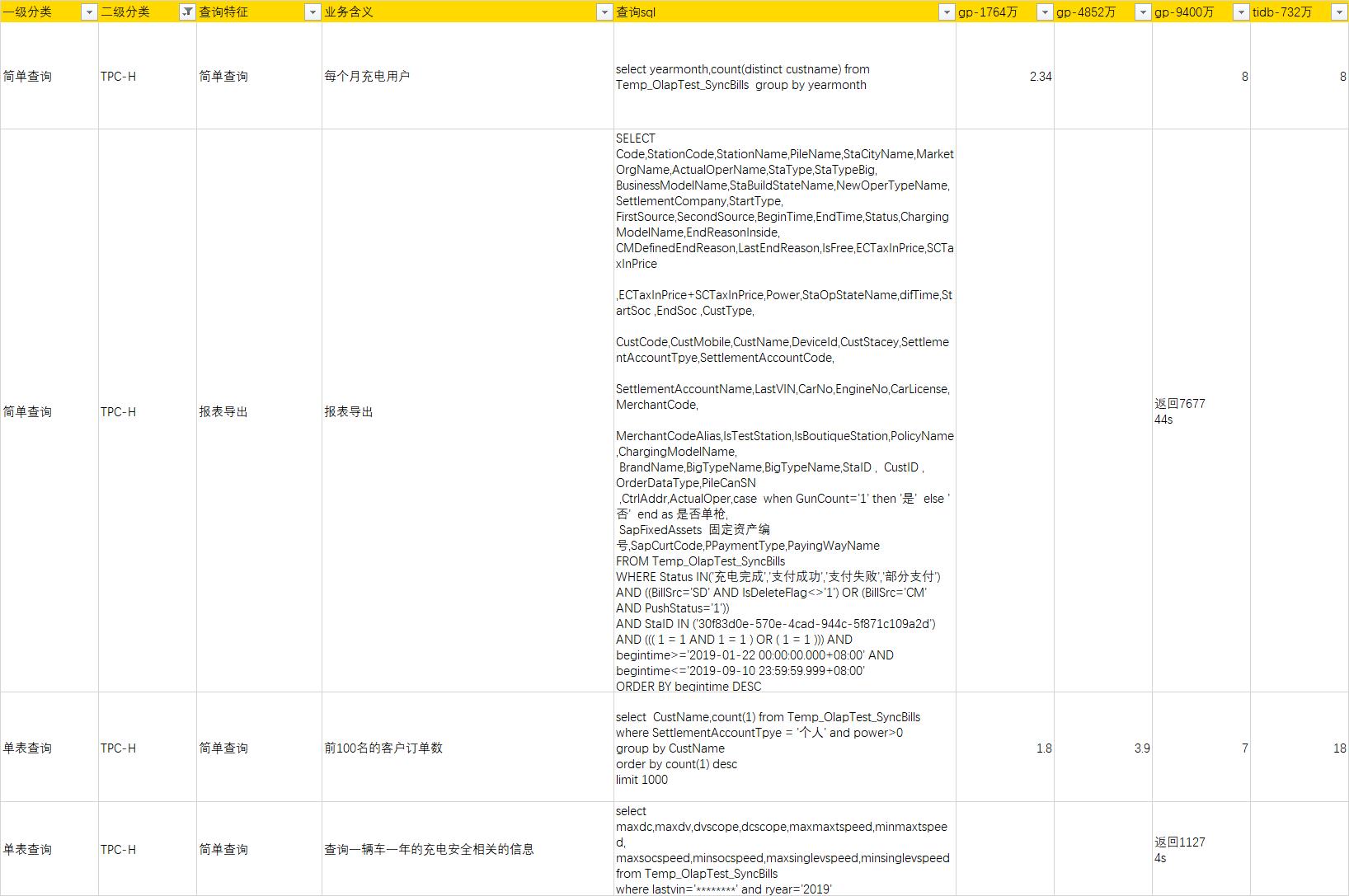
tpc-h
其余测试 --
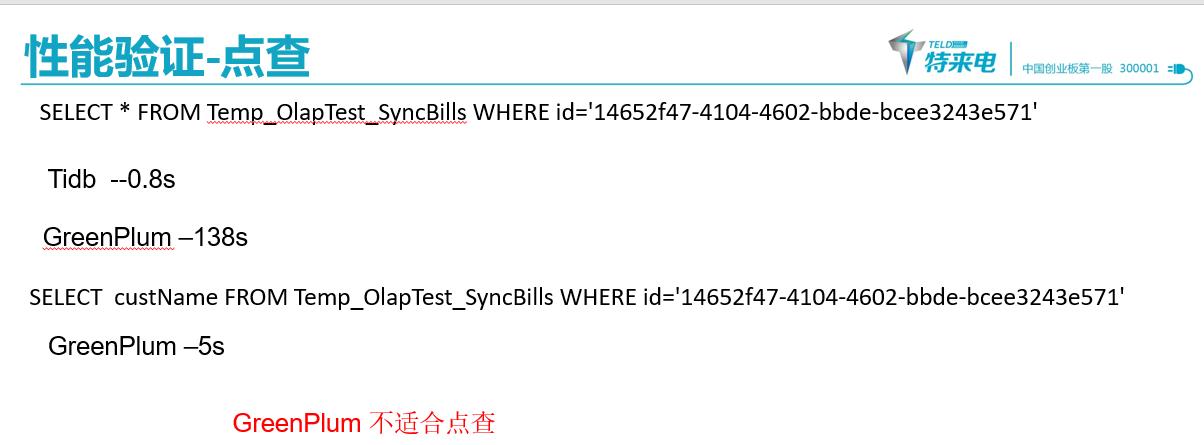

小结
- 针对OLAP的查询,greenplum 的分析统计性能要优于tidb
- 在greenplum不使用索引的情况下,点差要比tidb 差不少,增加对应的索引之后,性能差不多,但是greenplum 不建议使用索引
- greenplum在列存的场景下,查询的列的个数对性能影响较大。
下一步验证
1.星星模型 下的性能,考虑事实表 3亿,维度表 500万,
2.3亿的订单数据是否需要使用分区表
3.报表导出场景是否可以使用gp
4. sqlserver的存储过程是否可以迁移到greenplum
以上是关于GreenPlum tidb 性能比较的主要内容,如果未能解决你的问题,请参考以下文章