MySQL InnoDB 存储引擎原理浅析
Posted mikevictor
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL InnoDB 存储引擎原理浅析相关的知识,希望对你有一定的参考价值。
注:本文主要基于mysql 5.6以后版本编写,多数知识来着书籍《MySQL技术内幕++InnoDB存储引擎》,本文章仅记录个人认为比较重要的部分,有兴趣的可以花点时间读原书。
一、MySQL体系结构
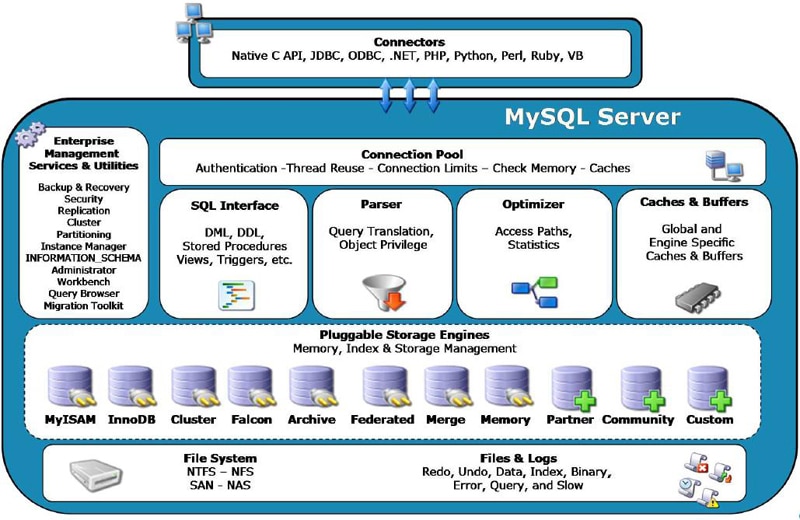
主要包含以下几部分:
1、管理服务于工具组件。
2、连接池与鉴权。
3、SQL接口。
4、查询分析器。
5、优化器组件。
6、缓存与缓冲区。
7、各式的插件式存储引擎。
8、物理文件。
其中存储引擎是基于表,而非数据库。
二、InnoDB体系结构
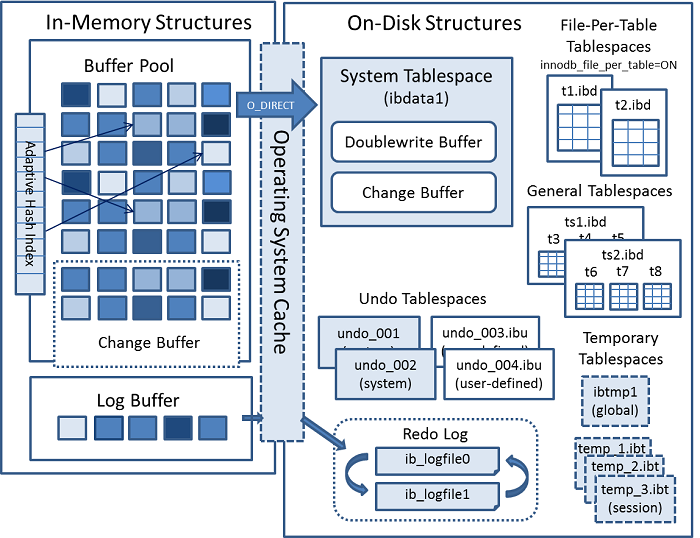
InnoDB引擎包含几个重要部分:
1、后台进程:
1.1 Master Thread:核心线程,负责缓冲池的数据异步入盘,包括脏页刷新、合并插入缓冲、undo页回收等。
1.2 IO Thread:包括read thread 和writer thread,使用show variables like ‘%innodb_%io_thread%‘;查看。
1.3 Purge Thread:回收事务提交后不再需要的undo log,通过show variables like ‘%innodb_purge_threads%‘; 查看。
1.4 Page clear thread:脏页的刷新操作,从master thread分离出来。
2、内存池
2.1 缓冲池
InnoDB将记录按页的形式进行管理,对于页的修改先修改缓冲池中的页,后以一定频率进行刷新到磁盘中(checkpoint)。在数据库的页读取操作时,将也缓存到缓冲池中,下一次如读取相同的页,则无需从磁盘中加载。缓存池大小通过innodb_buffer_pool_size配置。

从上图来看,主要包括索引页、数据页、undo页、insert buffer、adaptive hash index、数据字典等,其中索引页和数据页占用多数内存。
配置innodb_pool_buffer_instances将缓冲池分割为多个实例,减少内部竞争(比如锁)。
2.2 LRU list、free list、flush list
默认的缓冲页大小是16KB,使用LRU算法进行管理,新从磁盘加载的页默认加到LRU列表的midpoint处(尾端算起37%位置处)。通过show engine innodb status输出如下(部分):
-------------------
Buffer pool size 512 【缓冲池内存512*16K】
Free buffers 256
Database pages 256 【LRU列表占用页】
Old database pages 0
Modified db pages 0
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 0, not young 0
0.00 youngs/s, 0.00 non-youngs/s
Pages read 255, created 40, written 67
0.16 reads/s, 0.06 creates/s, 0.37 writes/s
Buffer pool hit rate 943 / 1000 【缓冲池命中率大于95%则良好】, young-making rate 0 / 1000 not 0 / 1000
LRU len: 256, unzip_LRU len: 0 【LRU列表中的页可被压缩分为1K/2K/4K/8K之类的页】
------------------
LRU列表中的页被修改后变为dirty page,此时缓冲池中的页和磁盘不一致,通过checkpoint刷回磁盘,其中Flush list即为dirty page列表。
2.3 Redo log buffer
InnoDB将重做日志首先刷入缓冲区中,后续以每秒一次刷新到日志文件中,通过show variables like ‘innodb_log_buffer_size‘; 查看,需要保证mysql每秒事务量应该小于此大小,通常可以配置8-32MB。以下情况会刷新缓冲区到磁盘的重做日志文件中:
1、Master thread每秒刷新。
2、每个事务提交。
3、缓冲区空间小于1/2(如果缓冲区过小则导致频繁的磁盘刷新,降低性能)。
2.4 innodb_additonal_mem_pool_size
如果申请了很大的buffer pool,此参数应该相应增加,存储了LRU、锁等信息。
3、checkpoint
每次执行update、delete等语句更改记录时,缓冲池中的页与磁盘不一致,但是缓冲池的页不能频繁刷新到磁盘中(频率过大性能低),因此增加了write ahead log策略,当事务提交时先写重做日志,再修改内存页。当发生宕机时通过重做日志来恢复。checkpint解决以下问题:
(1)减少重做日志大小,缩减数据恢复时间。
(2)缓冲池不够用时将脏页刷回磁盘。
(3)重做日志不可用时将脏页刷回磁盘(如写满)。
show variables like ‘innodb_max_dirty_pages_pct‘; (默认75%)来控制inndodb强制进行checkpoint。
若每个重做日志大小为1G,定了了两个总共2G,则:
asyn_water_mark = 75 % * 重做日志总大小。
syn_water_mark = 90 % * 重做日志总大小。
(1)当checkpoint_age < asyn_water_mark时则不需要刷新脏页回盘。
(2)当syn_water_mark < checkpoint_age < syn_water_mark 时触发ASYNC FLUSH。
(3)当checkpoint_age>syn_water_mark触发sync flush,此情况很少发生,一般出现在大量load data或bulk insert时。
4、InnoDB关键特性
关键特性包括:
(1) Insert buffer.
(2) double write.
(3) adaptive hash index.
(4) Async IO.
(5)Flush neighbor page.
4.1 Insert buffer
若插入按照聚集索引primary key插入,页中的行记录按照primary存放,一般情况下不需要读取另一个页记录,插入速度很快(如果使用UUID或者指定的ID插入而非自增类型则可能导致非连续插入导致性能下降,由B+树特性决定)。如果按照非聚集索引插入就很有可能存在大量的离散插入,insert buffer对于非聚集索引的插入和更新操作进行一定频率的合并操作,再merge到真正的索引页中。使用insert buffer需满足条件:
(1)索引为辅助索引。
(2)索引非唯一。(唯一索引需要从查找索引页中的唯一性,可能导致离散读取)
4.2 Double write
Doubel write保证了页的可靠性,Redo log是记录对页(16K)的物理操作,若innodb将页写回表时写了一部分(如4K)出现宕机,则物理页将会损坏无法通过redolog恢复。所以在apply重做日志前,将缓冲池中的脏页通过memcpy到doublewrite buffer中,再将doublewrite buffer页分两次每次1MB刷入共享表空间的磁盘文件中(磁盘连续,开销较小),完成doublewrite buffer的页写入后再写入各个表空间的表中。

当写入页时发生系统崩溃,恢复过程中,innodb从共享表空间的doublewrite找到该页的副本,并将其恢复到表空间文件中,再apply重做日志。
4.3 Adaptive hash index
Innodb根据访问频率对热点页建立哈希索引,AHI的要求是对页面的访问模式必须一样,如连续使用where a=‘xxx‘ 访问了100次。建立热点哈希后读取速度可能能提升两倍,辅助索引连接性能提升5倍。
通过show engine innodb statusG;查看hash searches/s, 表示使用自适应哈希,对于范围查找则不能使用。
4.4 Async IO
用户执行一次扫描如果需要查询多个索引页,可能会执行多个IO操作,AIO可同时发起多个IO请求,系统自动将这些IO请求合并(如请求数据页[1,2]、[2,3]则可合并为从1开始连续扫描3个页)提高读取性能。
4.5 刷新临近页
InnoDB提供刷新临近页功能:当刷新一脏页时,同时检测所在区(extent)的所有页,如果有脏页则一并刷新,好处则是通过AIO特性合并写IO请求,缺点则是有些页不怎么脏也好被刷新,而且频繁的更改那些不怎么脏的页又很快变成脏页,造成频繁刷新。对于固态磁盘则考虑关闭此功能(将innodb_flush_neighbors设置为0)。
5、InnoDB的启动、关闭与恢复
5.1 innodb_fast_shutdown
该值影响数据库正常关闭时的行为,取值可以为0/1/2(默认为1):
【为0时】:关闭过程中需要完成所有的full purge好merge insert buffer,并将所有的脏页刷新回磁盘,这个过程可能需要一定的时间,如果是升级InnoDB则必须将此参数调整为0再关闭数据库。
【为1时(默认)】:不需要full purge和merge insert buffer,但会将缓冲池中的脏页写回磁盘。
【为2时】:不需要full purge和merge insert buffer,也不会将缓冲池中的脏页写回磁盘,而是将日志写入日志文件中,后续启动时recovery。
5.2 innodb_force_recovery
参数innodb_force_recovery直接影响InnoDB的恢复情况。
默认值为0:进行所有的恢复操作,当不能进行有效恢复(如数据页corrupt)则将错误写入错误日志中。
某些情况下不需要完整的恢复造成,则可定制恢复策略,有以下几种:
- 1(SRV_FORCE_IGNORE_CORRUPT):忽略检查到的corrupt页。
- 2(SRV_FORCE_NO_BACKGROUND):阻止Master Thread线程运行,如果master thread需要进行full purge操作,这样会导致crash。
- 3(SRV_FORACE_NO_TRX_UNDO):不进行事务的回滚操作。
- 4(SRV_FORCE_NO_IBUF_MERGE):不进行插入缓冲区的合并操作。
- 5(SRV_FORCE_NO_UNDO_LOG_SCAN):不查看undo log,这样未提交的事务被视为已提交。
- 6(SRV_FORCE_NO_LOG_REDO):不进行redo操作。
在设置了innodb_force_recovery大于0后可对表进行select/create/drop操作,但不能进行insert update和delete等DML。如有大事务未提交,并且发生了宕机,恢复过程缓慢,不需要进行事务回滚则将参数设置为3以加快启动过程。
三、文件
3.1 二进制日志
二进制日志记录MySQL的变更操作(不包含查询),如果数据的影响行数为0也会记录。主要用于数据的恢复、复制、审计等场景。通过log-bin参数配置binlog的文件名。影响二进制日志记录的行为有:
(1) max_binglog_size
(2) binlog_cache_size
(3) sync_binlog
(4) binlog-to-db
(5) binlog-ignore-db
(6) log-slave-update
(7) binlog_format
max_binglog_size指定单个日志文件最大值,超过则产生新文件,默认为1G。
binlog_cache_size默认为32K,记录未提交的事务,当提交事务后会写入二进制日志文件中,该参数是基于会话的,不宜设置过大,通过以下命令检查是否cache不够导致使用到了磁盘(binlog_cache_disk_use),单位为次数:
$ show variables like ‘binlog_cache_size‘;
$ show global status like ‘binlog_cache%‘; (该命令显示的单位为次数)
如果显示的binlog_cache_disk_use次数较多,则考虑要增加binlog_cache_size大小。
sync_binlog表示每写多少次缓冲就同步到磁盘,通过设置参数为1则代表同步的方式写磁盘,但即使将该参数设置为1,还有一种异常场景:假设事务发出commit前,由于sync_binlog设置为1会立即写盘,但实际上还没提交事务就宕机,下次重启前由于没有commit动作事务将会被回滚,但二进制日志记录了该事务又不能被回滚,该异常场景通过设置innodb_support_xa为1来解决,保证了二进制日志与InnoDB存储赢钱数据文件的同步。
3.2 InnoDB存储引擎文件
3.2.1 表空间文件
默认共享表空间为ibatat1,可通过设定innodb_data_file_path=/db/ibdata1:2000M; /dir2/db/ibdata2:2000M:autoextend 指定多个共享表空间文件(用于均衡磁盘负载),通过设置autoextend用完自动增长,该文件不会缩小(即使删除记录),只能通过导出数据后,再删除该文件后重启再导入才能缩小此文件占用的空间。
一般情况下开启参数innodb_file_per_table=ON来开个独立表空间,每个表都有自己的表空间,以:表名.idb 命名,在清空表会后自动释放此单独的表空间。
独立的表空间仅存储该表的数据、索引、插入缓冲BITMAP等信息,其余的信息还是放在默认表空间中。
3.2.2 重做日志文件(Redo log file)
MySQL默认初始化ib_logfile0、ib_logfile1两个重做日志文件,一个用完切换到另一个,影响参数如下:
(1) innodb_log_file_size : 每个redo log文件大小。
innodb_log_files_in_group : 文件组中的文件数量,默认为2.
innodb_mirrored_log_groups : 镜像文件组数量,默认为1,如果磁盘已做高可用阵列,则用默认的1即可,不再需要再做日志镜像。
innodb_log_group_home_dir : 日志文件路径,默认在数据文件路径下。
Redo log设置不易过大,多大则重启需要恢复时间很长,也不宜过小,过小则导致频繁发生async checkpoint,需要刷脏页回磁盘,影响性能。一般的应用设置为1G即可。
InnoDB中重做日志是记录每个page的物理更改情况,而二进制文件是仅在事务提交前提交(即只写磁盘一次),在事务进行过程中,却不断有redo entry写入到重做日志文件中。两者是由差别的。
参数innodb_flush_log_at_trx_commit影响重做日志的刷写动作,有以下值:
【0】事务提交时并不写,而是等待主线程每秒刷写一次。
【1】默认值,表示执行事务commit时同步写到磁盘,提供最大的安全性,也是最慢的方式。
【2】异步写磁盘,先写到系统缓存,交给系统写到磁盘。
四、表
表空间由segment、extend、page组成,其中page是InnoDB磁盘管理的最小单位(默认大小为16K)。如下图:

如果启用了innodb_file_per_table参数,每张表的表空间只存放数据、所以和插入缓冲bitmap页,其他的数据如undo信息、插入缓冲、double write buffer等还是存放在共享表空间中。
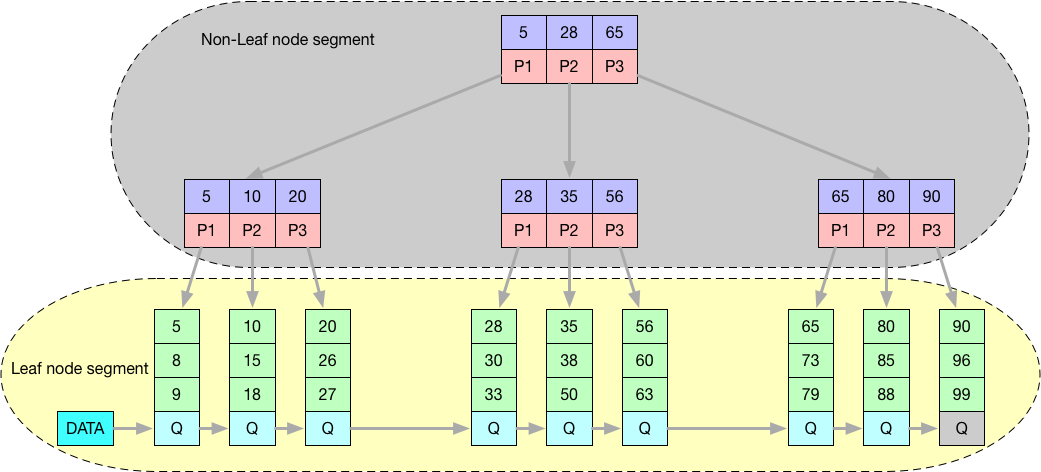
4.1 Segment (段)
常见的segment有数据段、索引段、回滚段等, 数据段为B+树的叶子节点(Leaf node segment)、索引段为B+树的非叶子节点(Non-leaf node segment)。如下图:
4.2 Extend (区)
每个区大小固定为1MB,为保证区中page的连续性通常InnoDB会一次从磁盘中申请4-5个区。在默认page的大小为16KB的情况下,一个区则由64个连续的page。
InnoDB 1.2.x版本增加参数innodb_page_size参数指定page的大小,但区的大小不会改变。 当启用了innodb_file_per_table参数后创建的表大小默认是96KB,而不是立即是1MB,是由于每个段开始先使用32个页大小的fragment page(碎片页)来存放数据,对于一些小表可节省磁盘空间。
4.3 Page (页)
每个page默认大小为16K, InnoDB 1.2.x版本增加参数innodb_page_size参数指定page的大小,设置完成后表中所有page大小都固定,除非重新dump再imports数据,否则不能再修改page大小。page类型有:
(1) B-tree node - 数据页
(2) undo log page
(3) system page
(4) transaction system page
(5) insert buffer bitmap
(6) insert buffer free list
(7) uncompressed BLOB page
(8) compressed BLOB page
// 本文后续待继续完善书籍中的其他重要知识点 //
以上是关于MySQL InnoDB 存储引擎原理浅析的主要内容,如果未能解决你的问题,请参考以下文章