阿里经济体大数据平台的建设与思考
Posted zhaowei121
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阿里经济体大数据平台的建设与思考相关的知识,希望对你有一定的参考价值。
本文内容根据演讲视频以及PPT整理而成。
双十一!=11.11
首先从双11说起,双11已经成为阿里巴巴最大的单日促销活动。双11活动可能对于消费者而言只是一天而已,但是对于阿里巴巴和数百万商家而言,却是一个非常长线的工作。站在阿里巴巴的角度来看双11,其实无论是从业务线还是技术线,背后都存在着很多的思考。

从“人、货、场”的角度看待双11。首先,对于“人”而言,双11需要回答什么样的消费者会看什么样的商品,以及每个人看到的商品是什么样子的。“货”则是对于商家而言的,商家需要知道在这次双11中,什么样的商品才能成为尖货,以及需要提前多久准备多少货才是最合适的。“场”的概念则更偏重于物流,比如需要提前将什么货物铺在什么地方才能够达到最优的物流执行效率。在“人、货、场”的背后存在两件事情,他们才是电商竞争力的关键。第一件事情就是供应链,如果能够提前长周期地布局供应链,包括柔性、精细化的供应链,对于商家双11大促和成本的降低将会产生非常大的作用。另外一件事情就是物流,前几年的时候每到双11物流就会爆仓,而最近几年虽然成交量在不断上涨,但是却没有再出现物流爆仓的情况。这背后的原因是阿里巴巴联合商家已经把消费者可能购买的商品布局到当地的本地仓库中了。而所有的这些工作其实都是千万级别商品和十亿级的消费者的匹配的问题。
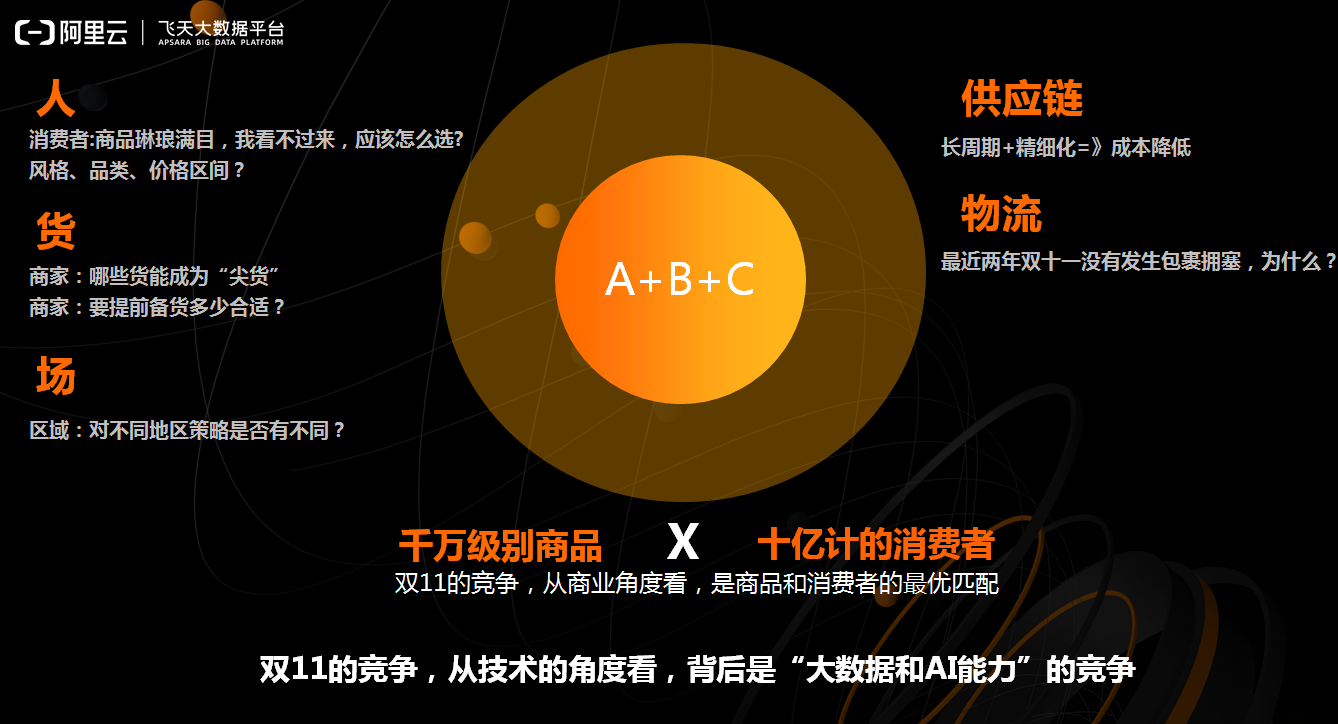
而从技术的角度来看,在这背后其实就是大数据和AI能力的竞争。双11竞争的是企业是否具有足够多的数据、足够强的算力、足够好的算法,指导什么样的消费者在什么样的风格、类目以及价格区间上看到商品;对于商家而言,什么样的货品才能够成为尖货,需要准备多少货才是合适的;对于供应链而言,需要怎样布局才能够达成成本的最优,将货物放在那个货场才能够距离消费者更近。这就是阿里所提的A+B+C概念,这里的A指的是Algorithm算法,B指的是Big Data大数据,C就是Computing计算,也就是说是否有足够多的数据、足够好的算法以及足够便宜的计算力。因此,双11的竞争,从技术角度来看,就是一个公司的大数据和AI能力的竞争。
下图展示的双11单日处理数据量的统计情况。从2015年到2019年,双11单日数据处理量大约增长了70%左右,但是这样的数据量不只是在双11当天才需要处理的,实际上从9月下旬到双11当天,每一天都需要处理如此之多的数据。运营同学、分析同学以及商家就在这些数据里面运行非常精细的算法,实现数据挖掘和信息处理,通过这种方式助力双11,这样才能使得双11当天实现最优的匹配。
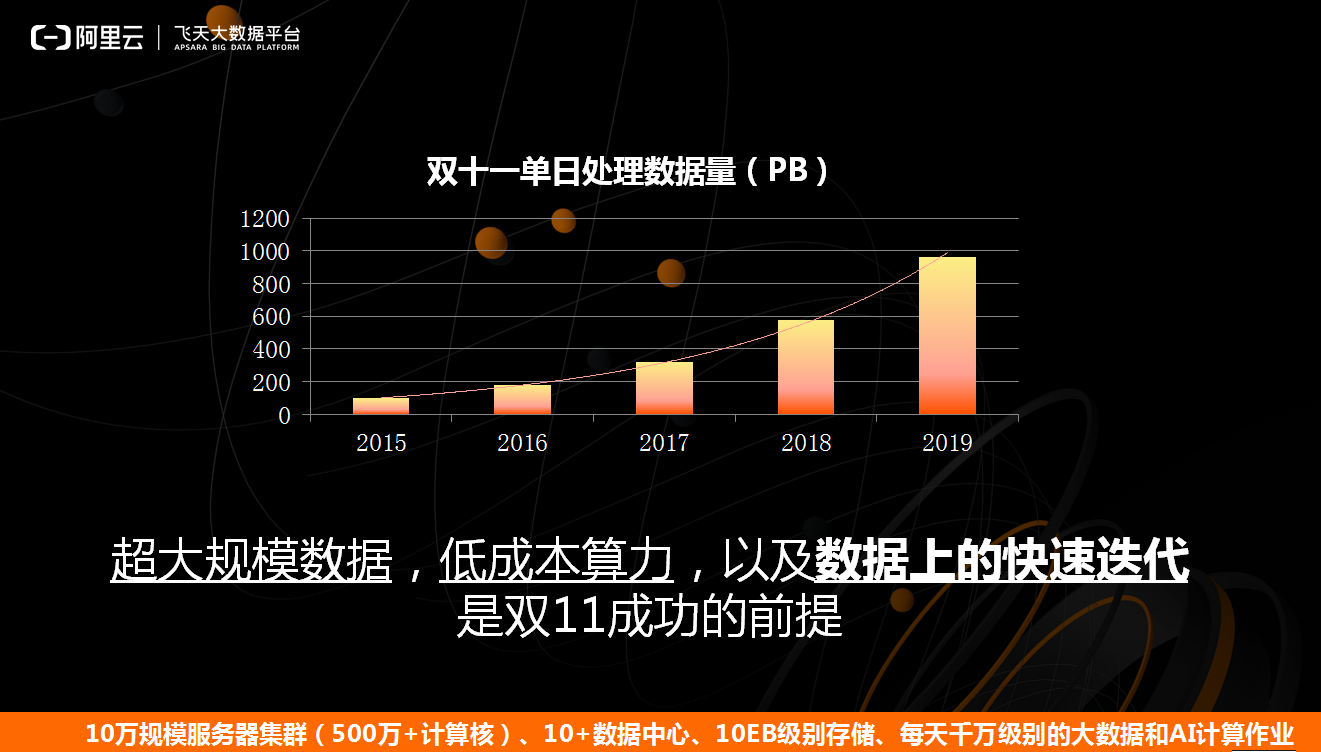
从技术的角度来看,双11的成功有三个必要条件,即超大规模数据,低成本算力,以及数据上的快速迭代。最后这个条件要划重点,如何使上万名算法工程师和数据工程师在数据上实现快速迭代与前面数据以及算力同样关键。海量数据上的快速迭代能力,本质是数据中台和数据开发平台的能力。
飞天大数据平台整体架构
如下图所示的是从阿里巴巴的角度看的整个飞天大数据平台的布局。从左侧看起,阿里巴巴主线数仓在MaxCompute上,目前在全球10个数据中心具有超过10万台的规模,阿里巴巴几乎所有的数据都存储在这里面。MaxCompute支撑了一套自研的SQL引擎,同时也支持Spark等开源的计算能力。除了主线数仓和大数据计算之外,阿里巴巴还有基于Flink的流计算系统。对于云上业务则有基于Hadoop的完整的EMR解决方案提供给客户。下图中左边的三部分叫做Basic Engine,也就是基础计算引擎。右边的引擎则包括PAI机器学习平台等,之所以左边和右边引擎割裂开,是因为两者不属于同等层面的关系,比如PAI的作业可以跑在MaxCompute上面也可以跑在Flink和EMR上面。除了PAI之外,阿里巴巴大数据平台还包括Hologres、图计算引擎Graph Compute以及Elasticsearch等。中间则是使用DataWorks贯穿起来的一体化大数据开发平台,包括大数据的开发以及数据Pipeline的建立也都整合在一个体系内。
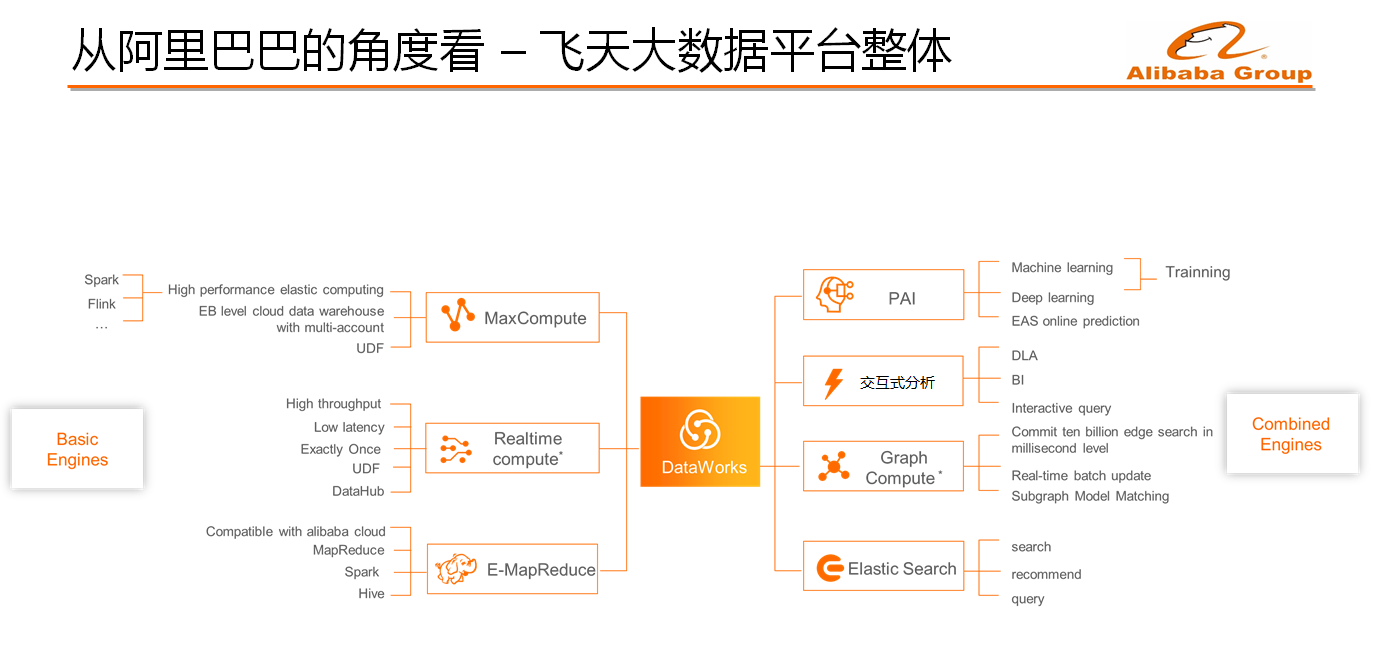
接下来以 MaxCompute 为例为大家介绍阿里经济体大数据平台的建设与思考。
飞天平台发展历程
从2002年开始,阿里所有的数据都存储在Oracle数据库里面。因为电商类业务最初都是记账类的,那时候所有的数据都在Oracle里面,当时阿里拥有整个亚洲最大的Oracle集群。而在后来发现Oracle无法支撑计算力的提升之后,阿里巴巴就迁移到了Greenplum上。Greenplum采用分布式架构,最高能够扩展到PB级别,但是不到一年的时间,Greenplum却也无法满足阿里业务的发展了。因此,在2008年的时候,阿里巴巴启动了Hadoop集群,这是阿里最早在大数据方面的探索。2009年阿里云成立,建立了飞天品牌,当时考虑是否自建一套飞天系统,所以大数据引擎、分布式存储和分布式调度一起作为三条主线一起启动。在2010年,阿里发布了存储计算的MaxCompute 1.0体系,对应的底盘叫做盘古存储,中间使用伏羲调度,最早支持蚂蚁金服的小微贷业务。在2013年,阿里开始在规模和扩展性上做到一定的量级,大约5千台服务器的级别,并在这个关键点上启动了阿里内部非常关键的项目“登月”,也就是将阿里巴巴所有的数据都集中到一个体系上来。因此当时存在非常大的讨论就是到底使用Hadoop还是使用自研的盘古 + MaxCompute体系,最终决定了使用自研体系。从2013年到2015年实现了完整的“登月”过程。2015年,阿里使用MaxCompute全面替换Hadoop,基于MaxCompute和DataWorks构建了完整的阿里数据中台。在2017年的时候,阿里巴巴认为需要进行引擎的迭代了,因此发布了MaxCompute 2.0版本,将整个核心引擎实现了重构。当时在扩展性上,单集群能够达到万台,全球有超过10个数据中心。最近,阿里巴巴在MaxCompute方面所做的工作包括性能的提升,以及在中台的基础之上演进自动中台或者说是自动数仓。
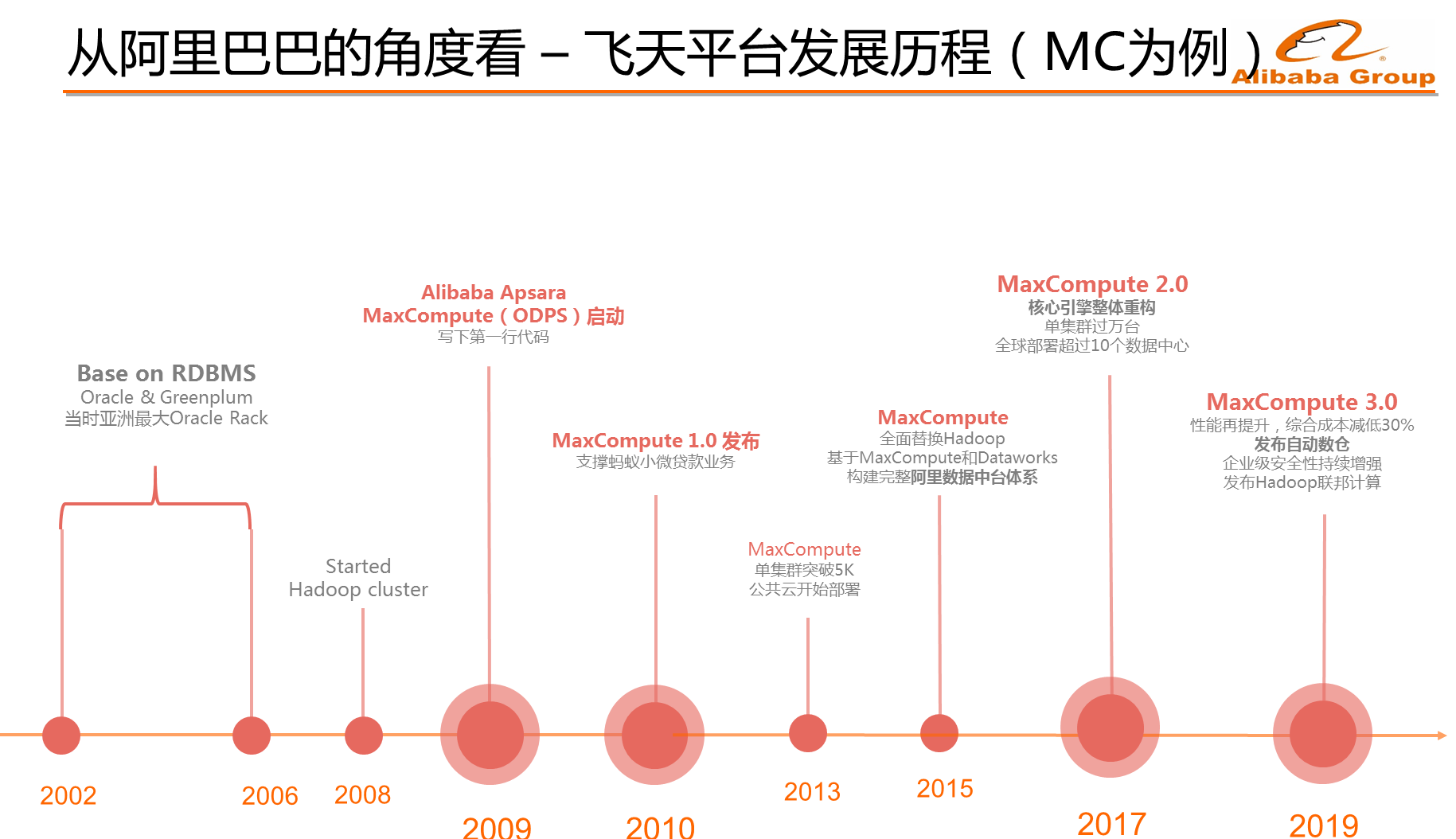
因此,飞天平台的发展历程可以用几句话来总结:第一,回首过去10年的发展,其实是阿里巴巴对于数据规模和低成本算力的持续追求。第二,从开源到自研的演进,而如今又从自研向开源方向演进,比如Flink的发展。第三,从最早的数据库走向数据仓库,走向了数据中台,再走向自动数仓。第四,数据湖开始的时候选择了Hadoop体系,而如今需要考虑如何将数据湖和数据仓库很好地融合在一起。
企业级计算平台的核心问题
对于企业级计算平台而言,往往会遇到很多问题。第一个问题很简单,但是也很常见,那就是需要可靠的数据交汇点,这里的可靠就是100%万无一失,并且需要保证数据存储在机房里面就不会丢失。第二个需要考虑高性能和低成本,这里除了引擎本身的性能优化之外,还需要考虑存储。第三个问题是如何做数据管理、共享与安全性。第四个问题则是企业级能力,比如如何做企业级自动化运维。第五个问题是需要支撑统一而丰富的运算能力,包括批处理、流处理、机器学习、图计算、交互计算等能力。第六个问题是如何拥抱和融合各种生态,包括自主系统与生态的融合,数据湖和数据仓库的融合等。第七个问题比较简单,就是开发语言与效率。第八个问题就是弹性能力与扩展性。最后一个问题就是大数据系统如何更好地支撑AI能力,同时是否能够利用AI能力优化大数据系统。

有关性能/效率(成本)优化
阿里巴巴在性能和效率方面所面临的挑战可以总结为以下4点:
1.当规模超过1万台时成本会持续增长,因此云上大规模客户对于成本的要求非常关键。
2.阿里巴巴数据和计算力的增长非常迅速,从双11来看,每年数据处理量的增速为70%左右,但是硬件投入不可能达到70%,这样的成本是无法承受的,因此需要打破数据和计算量线性增长之间的关系。
3.目前,技术发展进入了开源软件盲区,因为一般而言,开源软件无法满足超大规模的应用需要,因此需要解决这个问题。
4.之前发现了非常多的小集群,但是他们之间的负载无法实现均衡,因此需要解决多集群整体利用率不够高的问题。
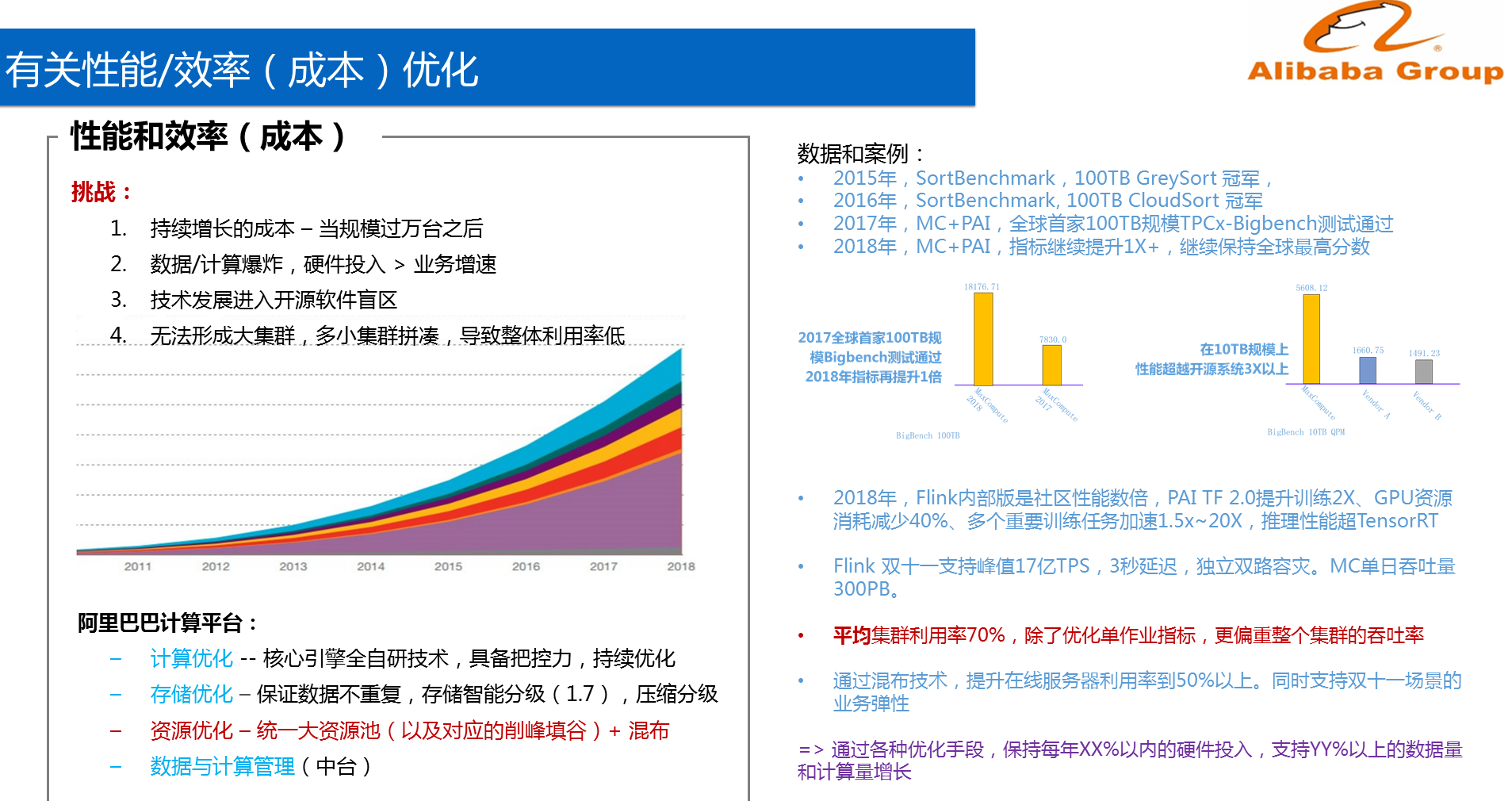
针对以上问题和挑战,可以从计算、存储以及资源方面进行优化,这里重点分享资源优化中的一部分,那就是混部。这里需要说明的是阿里巴巴在考虑资源优化的时候,并不考虑单作业的成本和效率,而关心整个集群的利用率的提升,将集群利用率提高到60%以上是阿里巴巴的强优化目标。
在双11当天,流量刚开始的时候会出现一个尖峰,这个尖峰可能一年就出现一次。大概到2点多钟的时候,流量会跌倒一个低谷,因为大家第一波抢购完成之后就睡觉了,等大家起床之后又会出现流量上升。那么,阿里巴巴需要准备多少台服务器才能满足需求呢?如果按照峰值准备,那么将会有一半的服务器总会处于空闲。如果按照均值进行规划,就会发现在峰值时用户无法提交请求,双11的体验就会很差。
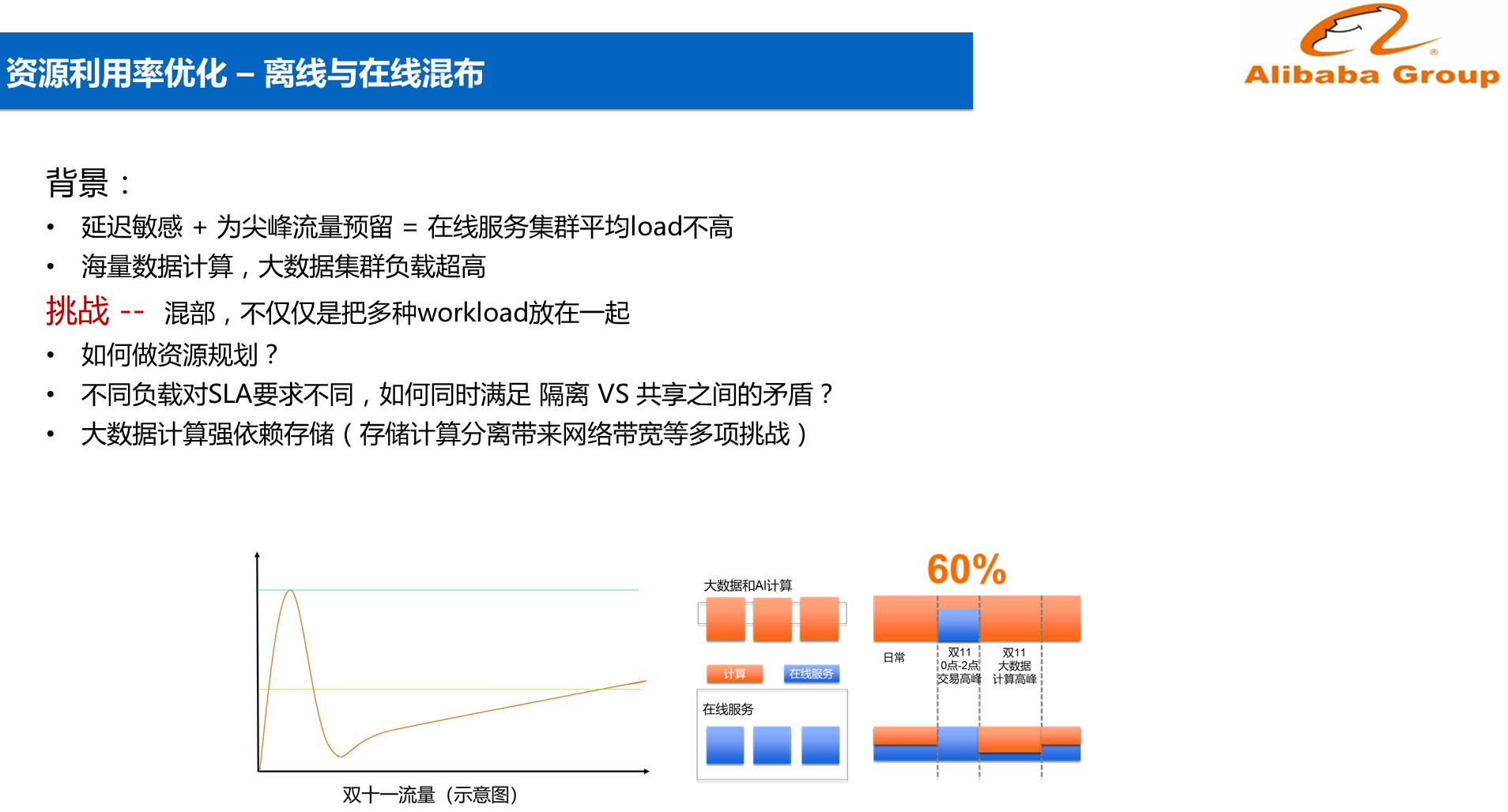
针对于双11的现状,阿里实现了两套混合部署的体系,第一套体系叫做离线和在线混合部署,第二套体系叫做在线和离线混合部署。比如大数据与AI计算服务和在线计算在离线计算规模上各不相同,对于电商服务而言,白天可能比较空闲,而大数据服务则是一直都很繁忙,因此在白天的时候,可以将一些大数据的计算弹到电商的集群上来,利用电商的部分CPU计算资源。而在双11,大数据业务需要快速回退,这里的回退指的不是几台机器的回退,而是数万台机器的回退,来支撑电商的流量洪峰。大数据和AI计算使用电商资源的混合部署是每天都会发生的,而电商使用大数据的资源则只在每年的双11和双12发生,每次只要两个小时,但是这两个小时的弹性却会为阿里巴巴节省数十亿的成本。混部这件事情绝不是将一些Workload放在一起就能解决问题了,因为总会遇到一些问题,比如如何做资源规划?这里不仅是在线集群的资源规划问题,而是阿里巴巴整个经济体的资源规划问题。因为不同负载对SLA要求不同,因此需要同时满足隔离和共享之间的矛盾?此外,大数据计算强依赖存储,这种情况下需要推的就是存储和计算分离的架构,而在存储与计算分离的背后是极高的网络带宽挑战。
资源利用率优化–离线与在线混布
如下图所示的是资源调度模拟图。Sigma是在线容器调度器,基本上所有的在线系统全部都实现了容器化,所有的容器系统都通过Sigma调度。伏羲是大数据和AI的调度器,主力计算力都通过伏羲进行调度。两套调度器都看到一套资源的View,相当于能够看到哪部分资源是空的,可以调入和调出。底层有两套Agent,这两套Agent负责在拿到资源之后向下做资源申请和管理。Sigma后续可能会延续到Kubernetes平台上,目前是使用Docker完成的。这里并没有试图去合成一个中央调度器来实现所有的调度工作,而是以在线和离线分开来做调度的。从半动态资源调度策略起步,保持两边调度系统改动最小,从而实现快速升降级和迭代。
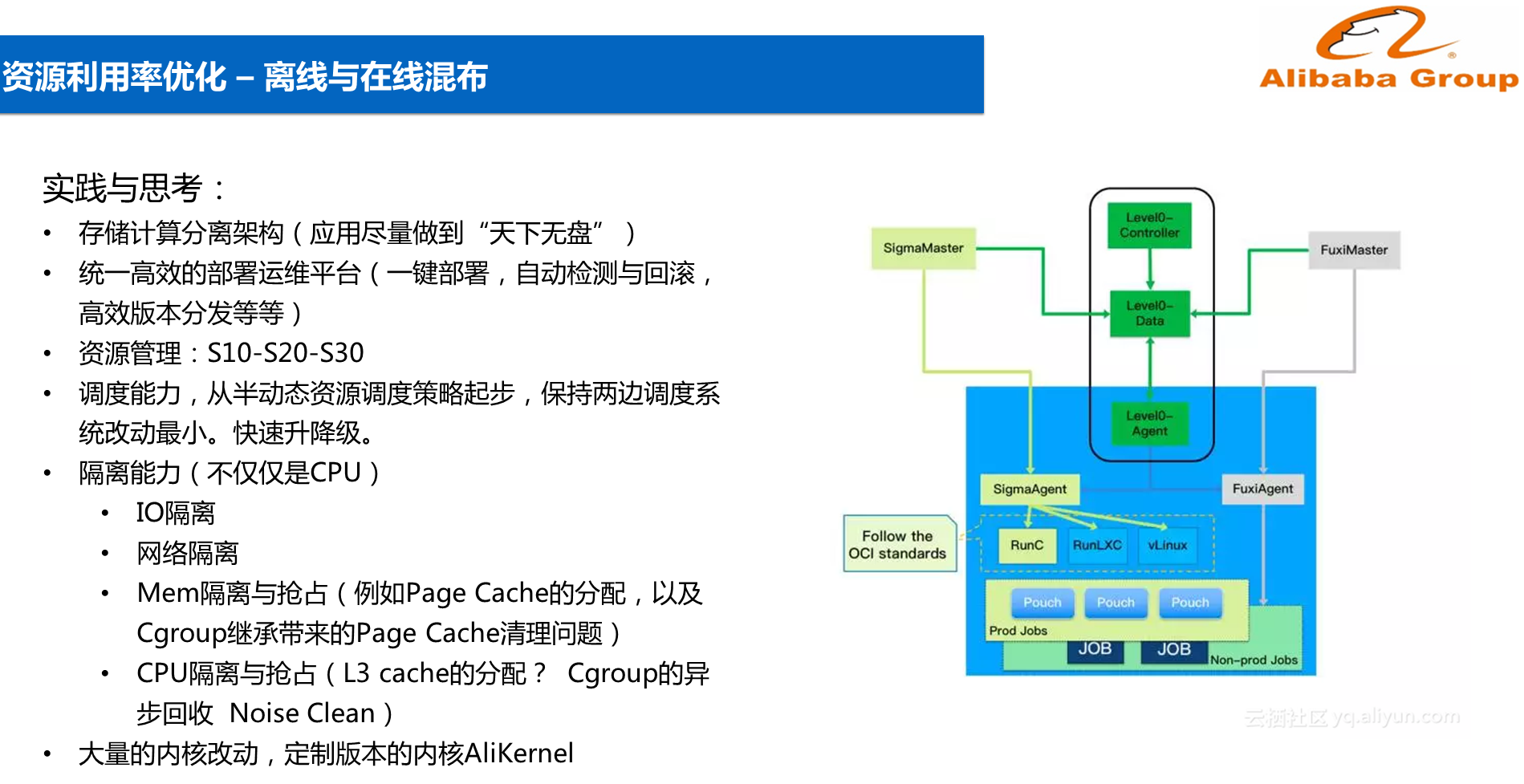
在思考层面,有几个关键点,其中一个是存储和计算分离,特别是想要利用大规模电商资源实现弹性的时候,一定要做存储和计算分离。因此,在阿里巴巴内部有一个项目叫做“天下无盘”,也就是说所有的计算都可以和存储分开,而不依赖于本地存储。因为会涉及到数十万台机器的调度,因此需要有统一高效的部署运维平台,一定需要一键部署,自动检测与回滚,高效版本分发等能力。在资源管理层,因为不同的应用具有不同的SLA要求,因此将资源分为了S10-S20-S30三个等级。隔离能力绝对不仅仅是CPU的隔离,这里面包括IO、网络、内存等各个方面的隔离。对于大量的改动而言,阿里巴巴实现了定制版本的内核AliKernel,将这些改动全部放在AliKernel里面。以上这些关键点实现之后,基本上就能够实现比较完善的电商混部。
有关数据仓库与数据湖
其实Hadoop本身就是一个数据湖体系,其拥有一套统一的存储架构,上面运行多套引擎。Hadoop基本满足数据湖所有的定义,比如HDFS存储的数据几乎不要求是完全建模的,可以不建模,并且能够是Schema-On-Read的,可以在读取到时候动态解析Schema。因为是开放架构,因此可以运行所有引擎,但是从另外一个层面上讲解,因为存储是开放的,因此难以做全面优化。在成本方面,对于数据湖而言,比较容易启动。其难点在于维护成本比较高,比如最经典的小文件问题。对于数据使用而言,往往难以实现很高的质量以及可维护性。从另外一个角度来看,包括阿里在内的很多企业都在做数据仓库,之所以做这件事情是因为在数据仓库中,数据进来都是Fully modelled的,那么表和数据都是事先定义好的。正因为是Fully modelled的,因此通常只存储结构化和非结构化的数据,而这样会造成数据存储灵活性的问题。而因为采用了一体的概念,那么并不是所有引擎都适合运行在这套系统里面。但是一体化架构更容易实现优化,存储更容易为上层计算进行优化,这里的成本就是数据仓库可能不好建设,因为对于数据写入以及维护等要求较高。但是一旦数据仓库做成,就更容易实现Fully managed。对于数据使用而言,往往能够实现较高的数据质量,并且易于使用。

那么将核心数据全部放在数据仓库上是否可以行,显然是可行的,并且包括阿里巴巴在内的很多企业也都是这么做的。如果只用数据湖来做,是否可行,答案也是可行的,其实很多公司也是这么做的。那么能否将两者结合起来呢?也是可行的。业界也有很多尝试,并且是双向的,数据湖架构能够看到数据仓库的优势,因此向着数据仓库演进比如Hadoop + HMS,可以认为是增强版HMS的Netflix Iceberg以及Spark DeltaLake。而数据仓库系统也能够看到数据湖的灵活性,也在向着数据湖发展,比如Redshift和Snowflake,因此演进是双向的。
有关数据仓库与数据湖–阿里大数据平台的演进
阿里巴巴在2013年到2015年的时候看到了Hadoop体系的一些问题,比如扩展性、性能、安全性、稳定性以及代码可控性。因此,阿里做了Hadoop到MaxCompute的迁移,相当于对于数据湖场景做了主线数仓,那个时候就已经开始有能力构建阿里的数据中台,开始构建数据建模、数据血缘、数据治理以及标签体系等。

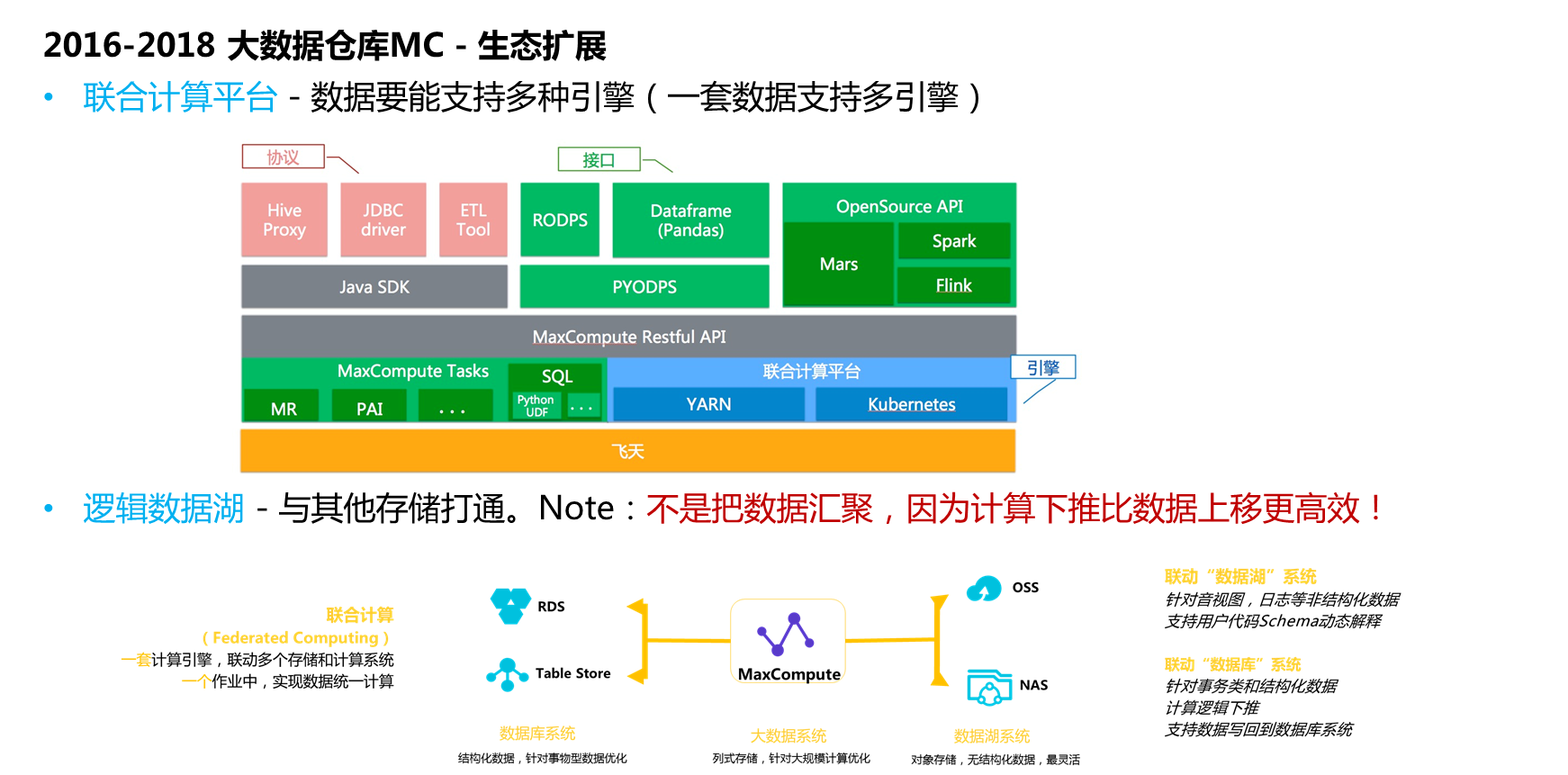
阿里巴巴构建完数据中台之后,在2016年到2018年的时候对于主线的数据仓库平台中做了两个项目,分别是联合计算平台和逻辑数据湖。联合计算平台使得数据能支持多种引擎,在MaxCompute平台上封装了“丘比特”,将数据的资源层封装成了Yarn和Kubernetes平台,将数据存储层抽象了一套IO接口,将元数据系统抽象出来一套系统,可以对接Spark、Flink等开源引擎。丘比特平台所能实现的是Spark和Flink不需要修改代码,只需要替换一些Jar包就能够在MaxCompute平台上使用资源跑数据,相当于在数仓的基础之上向上扩展了对于引擎的支持。另外一件事情就是做了外表能力,所谓逻辑数据湖则实现了与其他存储打通,不是把数据汇聚,因为计算下推比数据上移更高效。
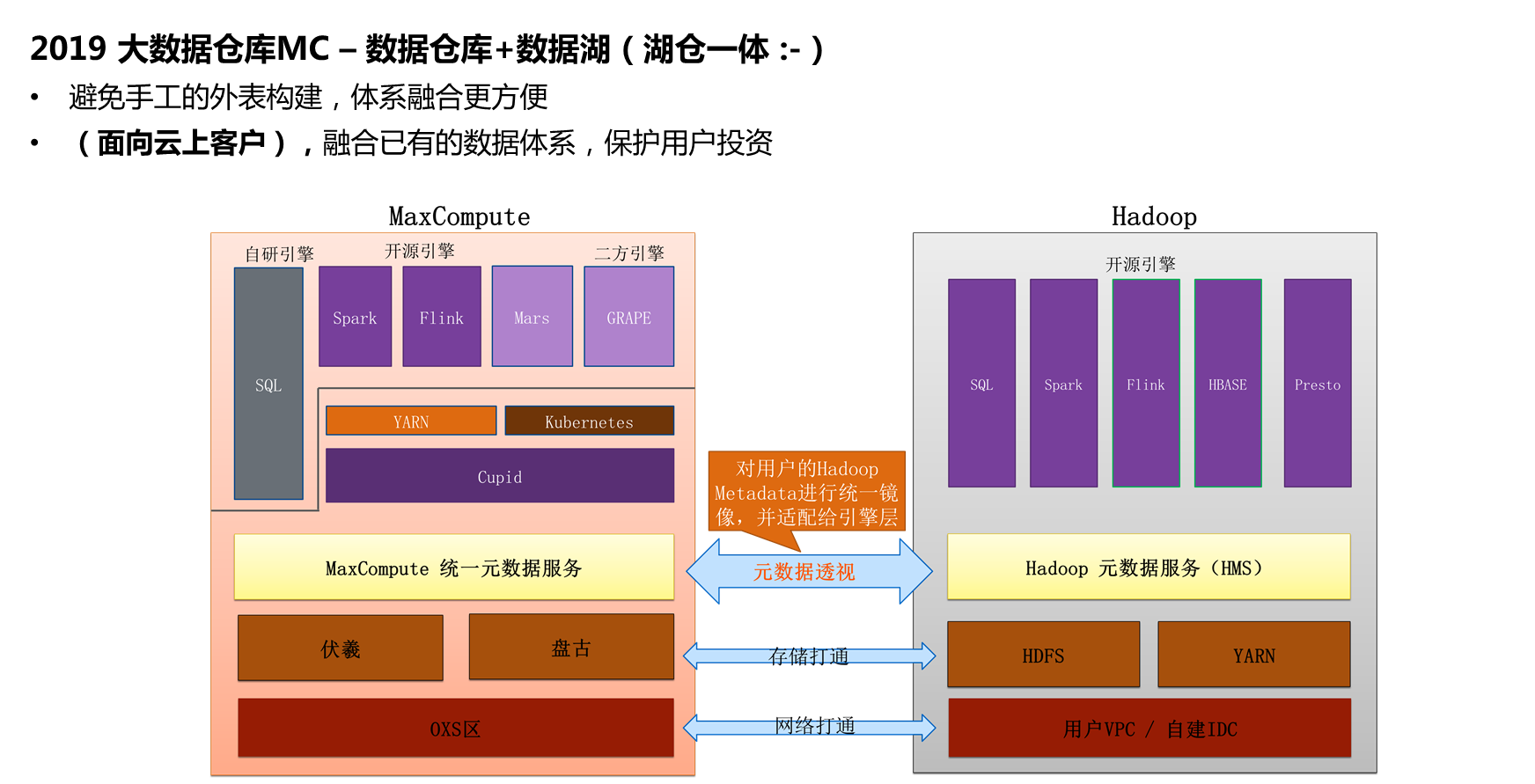
在2019年,阿里巴巴看到了实现逻辑数据湖潜在的问题,这对于用户而言是非常困难的,特别是具有海量数据的时候。另外一点,云上客户给阿里的反馈是手里已经有了200台机器的Hadoop体系了,并且希望使用阿里的数仓架构和中台架构提升业务能力,如何实现两条线和谐发展呢?因此,阿里巴巴正在着手实现所谓的“湖仓一体”,也就是将数据仓库和数据湖融合在一起。除了打通数据湖和数据仓库的网络之外,阿里巴巴还实现了元数据的打通,当希望对两边的数据做Join计算的时候不需要建立外表,目前这套架构正在试用中。
本文作者:晋恒
本文为阿里云内容,未经允许不得转载。
以上是关于阿里经济体大数据平台的建设与思考的主要内容,如果未能解决你的问题,请参考以下文章