大数据---大数据及HDFS简述
Posted bluedarkni
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据---大数据及HDFS简述相关的知识,希望对你有一定的参考价值。
一、大数据简述
在互联技术飞速发展过程中,越来越多的人融入互联网。也就意味着各个平台的用户所产生的数据也越来越多,可以说是爆炸式的增长,以前传统的数据处理的技术已经无法胜任了。比如淘宝,每天的活跃用户量是很大的一个数目。马云之前说过某个省份的女性bar的size最小问题,不管是玩笑还什么,细想而知,基于淘宝用户的购物记录确实可以分析出来。
对企业的用户数据进行分析,可以知道公司产品的运营情况,比方说一个APP的用户每天登陆了几乎都没有什么实质性的操作,那就说明这个玩意儿已经快凉了,程序员赶快可以跑路了。
每个人登录哪些电商网站的首页都是不一样,这后面就是根据用户的近期浏览或者关注的,根据这些来生成推送每个人关注的商品。
对于这些海量的数据的处理分析所诞生的技术,也就是大数据。
对于这些数据两个核心点,一个如何存储,另一个就是怎么使用。
相关的技术:
存储框架:
HDFS——分布式文件存储系统(HADOOP生态中的存储框架)
HBASE——分布式数据库系统
KAFKA——分布式消息缓存系统(实时流式数据处理场景中应用广泛)
运算框架:(要解决的核心问题就是帮用户将处理逻辑在很多机器上并行)
MAPREDUCE—— 分布式计算(HADOOP中的运算框架)
SPARK —— 离线批处理/实时流式计算
STORM —— 实时流式计算
其他框架:
HIVE —— 数据仓库工具:可以接收sql,翻译成mapreduce或者spark程序运行
FLUME——数据采集
SQOOP——数据迁移
ELASTIC SEARCH —— 分布式的搜索引擎
.......
.......
.......
二、HDFS简述
hadoop中有3个核心组件:
分布式文件系统:HDFS —— 实现将文件分布式存储在很多的服务器上
分布式运算编程框架:MAPREDUCE —— 实现在很多机器上分布式并行运算
分布式资源调度平台:YARN —— 帮用户调度大量的mapreduce程序,并合理分配运算资源
HDFS---分布式文件系统,相当于就是一个目录树,一层一层的,这个是虚拟的出来一个结构,由HDFS管理,并不能实际看见,只能通过客户端去访问的时候可以看见这些结构。
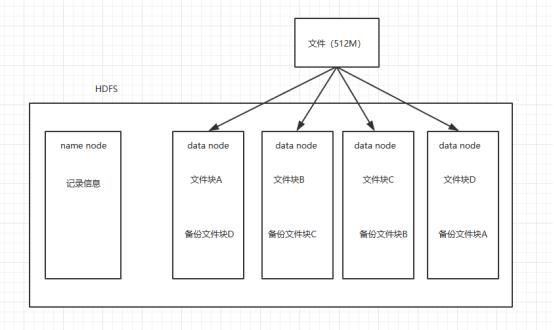
1.一个数据在HDFS上面存储的时候会根据大小来进行分块,被分块之后,存放在多个机器上面(data node),比如一个512M的文件,如果按照128M来分,就会被分成4块,然后
存储到4个节点上。
2.一般来说为了保证数据的高可用,我们会把同一个数据块备份到不同的节点上面,某个节点挂了,还可以在其他节点上面找到数据。意思就说数据块A既会在A机器上存储,也会在机器B上面存储一份,甚至更多的备份。
3.分块存储之后怎么直到数据存在哪些机器上呢,这个时候就需要一个管理者来记录这些数据信息(name node)
也就是说一个HDFS系统是由name node服务器和多个data node服务组成
以上是关于大数据---大数据及HDFS简述的主要内容,如果未能解决你的问题,请参考以下文章