大数据---HDFS集群搭建
Posted bluedarkni
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据---HDFS集群搭建相关的知识,希望对你有一定的参考价值。
一、准备工作
1.准备几台机器,我这里使用VMware准备了四台机器,一个name node,三个data node。
VMware安装虚拟机:https://www.cnblogs.com/nijunyang/p/12001312.html
2.Hadoop生态几乎都是用的java开发的,因此四台机器还需要安装JDK。
3.集群内主机域名映射,将四台机器的IP和主机名映射分别写到hosts文件中(切记主机名不要带非法字符,图片中的下划线”_”请忽略)
vim /etc/hosts
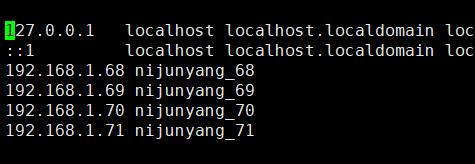
配好一个之后可以直接将这个复制到其他机器上面去,不用每台都去配置:
scp /etc/hosts nijunyang69:/etc/
scp /etc/hosts nijunyang70:/etc/
scp /etc/hosts nijunyang71:/etc/
二、hdfs集群安装
1.下载hadoop安装包到linux服务器上面,并进行解压,我这里使用的的2.8.5,
tar -zxvf hadoop-2.8.5.tar.gz
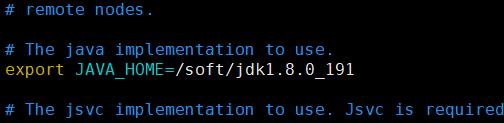
2.hadoop指定java环境变量:
hadoop-2.8.5/etc/hadoop/hadoop-env.sh 文件中指定java环境变量:
export JAVA_HOME=/soft/jdk1.8.0_191
3.配置核心参数:
默认参数:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
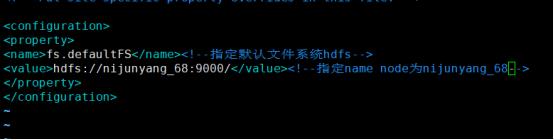
1)指定hadoop的默认文件系统为:hdfs
2)指定hdfs的namenode节点为哪台机器
修改/etc/hadoop/core-site.xml 指定hadoop默认文件系统为hdfs,并且指定name node
<configuration> <property> <name>fs.defaultFS</name><!--指定默认文件系统hdfs--> <value>hdfs://nijunyang68:9000/</value><!--指定name node为nijunyang_68--> </property> </configuration>
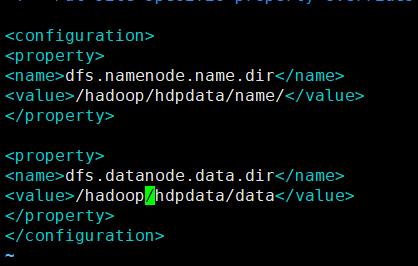
3) 指定namenode存储数据的本地目录
4) 指定datanode存放文件块的本地目录
修改/etc/hadoop/hdfs-site.xml
<configuration> <property> <name>dfs.namenode.name.dir</name> <value>/hadoop/hdpdata/name/</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/hadoop/hdpdata/data</value> </property> </configuration>
每台机器都执行同样的操作,配置好上述配置,可以使用scp -r /soft/hadoop-2.8.5 nijunyang69:/soft 这个命令将第一台机器配置好的全部打包拷贝到另外机器上面去。
4.配置hadoop环境变量
5.初始化namenode:hadoop namenode -format
这时我们设置的namenode数据目录下面就会初始化出来对应的文件夹
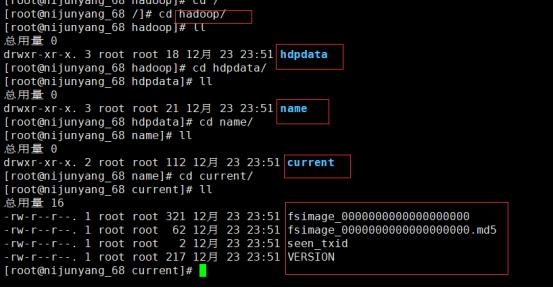
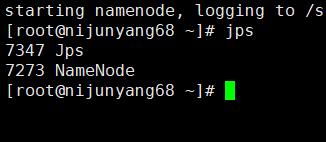
6.启动namenode:在之前指定的namenode上面执行:hadoop-daemon.sh start namenode
Jps查看可以看到一个namenode的java进程,同时通过默认的50070端口可以进行web访问
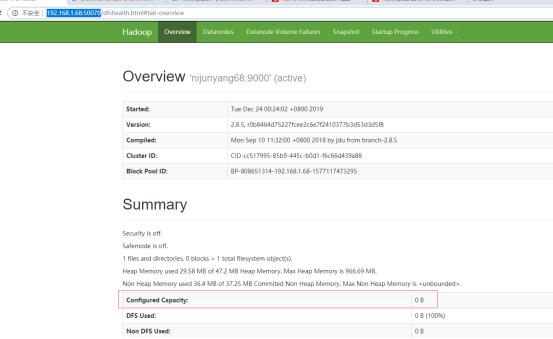
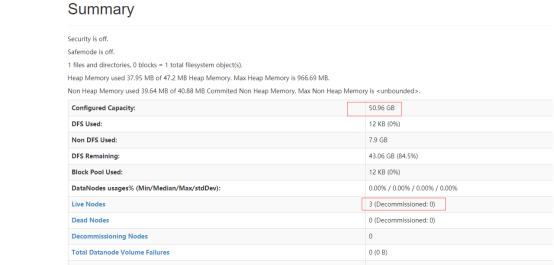
可以看到现在HDFS的容量还是0,因为我还没有启动datanode
7.依次启动datanode:hadoop-daemon.sh start datanode
同样可以看到一个datanode的java进程启动了,再看web页面这个时候的hdfs容量大小差不多就是三个datanode之和了。
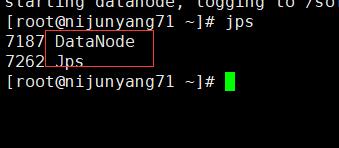
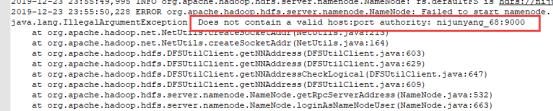
至此整个hdfs集群基本就搭建完毕了,中间的一个小插曲,主机名一定不要带”.” “/” “_”等特殊符号,否则启动无服务的时候可能报错无法启动:Does not contain a valid host
三、脚本一键启动集群
1.在启动的机器上配置SSH免密登录集群所有机器,在任意一台机器配置都可以
1)生成秘钥:ssh-keygen
2)设置免密连接:
ssh-copy-id nijunyang68
ssh-copy-id nijunyang69
ssh-copy-id nijunyang70
ssh-copy-id nijunyang71
设置好之后就可以当前机器直接通过SSH连接其他机器,不需要输入密码
2. 修改文件hadoop-2.8.5/etc/hadoop/etc/hadoop/slaves,加入需要启动的datanode
默认有个本机。如果不需要再本机启动datanode就把localhost删掉
3.执行sbin目录下的集群启动脚本/停止脚本:start-dfs.sh/stop-dfs.sh
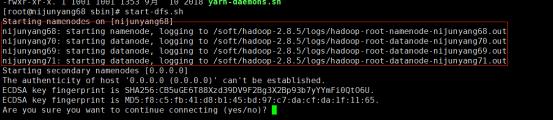
虽然集群起来了,但是还有个Starting secondary namenodes 启动在本机上,这个时候我最好去将secondary namenodes配置到另外的机器上面去,修改之前的/etc/hadoop/hdfs-site.xml,加入secondary namenodes的配置:
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>nijunyang69:50090</value>
</property>
以上是关于大数据---HDFS集群搭建的主要内容,如果未能解决你的问题,请参考以下文章