Mysql千万级别数据批量插入,性能提高
Posted cool小伙
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Mysql千万级别数据批量插入,性能提高相关的知识,希望对你有一定的参考价值。
-----------------------------------------------------------方式1 ----------------------------------------------------------------------------------------
第一步:配置my.ini文件
文件中配置
bulk_insert_buffer_size=120M 或者更大
将insert语句的长度设为最大。
Max_allowed_packet=1M
Net_buffer_length=8k
保存
第二步:查看设置的参选有没有生效.
mysql > SHOW VARIABLES;
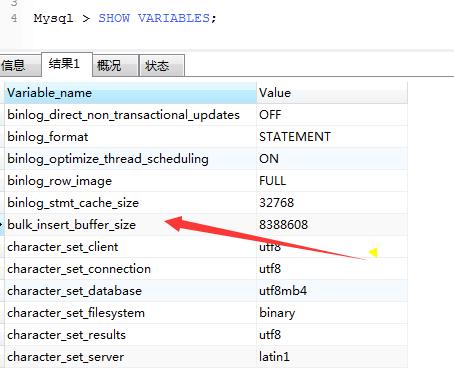
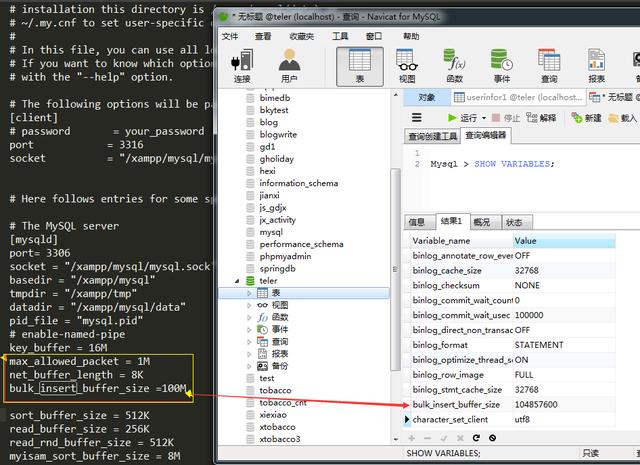
bulk_insert_buffer_size默认是8M,我们要把它调成100M或百兆以上,也不要太大。下面看调整个好的,如下图:
第三步:完成设置后,批量插入数据时使用多条模式。
INSERT INTO table (field1,field2,field3) VALUES (\'a\',"b","c"), (\'a\',"b","c"),(\'a\',"b","c");
----------------------------------------------------------- 方式2 ----------------------------------------------------------------------------------------
python中单个和批量增加更新的mysql(没有则插入,有则更新)
建表语句:

DROP TABLE IF EXISTS `stock_discover`; CREATE TABLE `stock_discover` ( `code` char(6) NOT NULL, `index` int(11) unsigned NOT NULL DEFAULT \'0\', `name` varchar(20) NOT NULL, `exchange` varchar(10) NOT NULL DEFAULT \'\', `date` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, `yesterday` double unsigned NOT NULL, PRIMARY KEY (`code`,`index`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
单个添加更新
如果记录在表中不存在则进行插入,如果存在则进行更新:
sql = "INSERT INTO stock_discover VALUES (\'%s\', 2, \'%s\', \'HZ\', \'%s\', \'%s\')" \\
" ON DUPLICATE KEY UPDATE `date` = \'%s\' , yesterday = \'%s\'\'"
#数据格式
data = [\'000005\', u\'合肥\', \'2018-09-19 14:55:21\', u\'2520.64\']
sql = sql % (data[0], data[1], data[2], data[3], data[2], data[3])
cursor.execute(sql)
批量添加更新
在更新大量数据时可能同时遇到两个问题:
① 如果每条更新执行一次sql性能很低,也容易造成阻塞;
② 批量更新时又有可能遇到主键重复的问题
使用 ON DUPLICATE KEY UPDATE 一条sql解决批量更新和主键重复问题(id为主键),使用executemany进行批量插入
# 记录在表中不存在则进行插入,如果存在则进行更新
sql = "INSERT INTO `stock_discover` VALUES (%s, %s, %s, %s, %s, %s) " \\
"ON DUPLICATE KEY UPDATE `date` = VALUES(`date`) , yesterday = VALUES(yesterday)"
#数据格式如下:
data_info = [(\'000005\', 2, u\'合肥\', \'HZ\', \'2018-09-19 14:55:21\', u\'2520.64\'),
(\'000006\', 2, u\'北京\', \'HZ\', \'2018-09-19 14:55:21\', u\'2694.92\'),
(\'000007\', 2, u\'上海\', \'HZ\', \'2018-09-19 14:55:21\', u\'2745.38\')]
#批量插入使用executement
cursor.executemany(sql, data_info)
注意: ON DUPLICATE KEY UPDATE是mysql特有的语法,对于其他sql并不一定适用
也可以使用如下方法:
Mysql插入数据的SQL语句主要有:
1、insert into表示插入数据,数据库会检查主键,如果出现重复会报错;
2、replace into表示插入替换数据,需求表中有PrimaryKey,或者unique索引,如果数据库已经存在数据,则用新数据替换,如果没有数据效果则和insert into一样;
3、insert ignore表示,如果表中如果已经存在相同的记录,则忽略当前新数据;
create table testtb( id int not null primary key, name varchar(50), age int ); insert into testtb(id,name,age)values(1,\'bb\',13); select * from testtb; insert ignore into testtb(id,name,age)values(1,\'aa\',13); select * from testtb; replace into testtb(id,name,age)values(1,"aa",12); select * from testtb;
以上是关于Mysql千万级别数据批量插入,性能提高的主要内容,如果未能解决你的问题,请参考以下文章