Hadoop学习之路Mapreduce程序完成wordcount
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop学习之路Mapreduce程序完成wordcount相关的知识,希望对你有一定的参考价值。
程序使用的测试文本数据:Dear River
Dear River Bear Spark
Car Dear Car Bear Car
Dear Car River Car
Spark Spark Dear Spark 1编写主要类
(1)Maper类
首先是自定义的Maper类代码
public class WordCountMap extends Mapper<LongWritable, Text, Text, IntWritable> {
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
//fields:代表着文本一行的的数据: dear bear river
String[] words = value.toString().split(" ");
for (String word : words) {
// 每个单词出现1次,作为中间结果输出
context.write(new Text(word), new IntWritable(1));
}
}
}?????这个Map类是一个泛型类型,它有四个形参类型,分别指定map()函数的输入键、输入值、输出键和输出值的类型。LongWritable:输入键类型,Text:输入值类型,Text:输出键类型,IntWritable:输出值类型.
?????String[] words = value.toString().split(" ");,words 的值为Dear River Bear River
?????输入键key是一个长整数偏移量,用来寻找第一行的数据和下一行的数据,输入值是一行文本Dear River Bear River,输出键是单词Bear ,输出值是整数1。
?????Hadoop本身提供了一套可优化网络序列化传输的基本类型,而不直接使用Java内嵌的类型。这些类型都在org.apache.hadoop.io包中。这里使用LongWritable类型(相当于Java的Long类型)、Text类型(相当于Java中的String类型)和IntWritable类型(相当于Java的Integer类型)。
?????map()方法的参数是输入键和输入值。以本程序为例,输入键LongWritable key是一个偏移量,输入值Text value是Dear Car Bear Car ,我们首先将包含有一行输入的Text值转换成Java的String类型,之后使用substring()方法提取我们感兴趣的列。map()方法还提供了Context实例用于输出内容的写入。
(2)Reducer类
public class WordCountReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
/*
(River, 1)
(River, 1)
(River, 1)
(Spark , 1)
(Spark , 1)
(Spark , 1)
(Spark , 1)
key: River
value: List(1, 1, 1)
key: Spark
value: List(1, 1, 1,1)
*/
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable count : values) {
sum += count.get();
}
context.write(key, new IntWritable(sum));// 输出最终结果
};
}Reduce任务最初按照分区号从Map端抓取数据为:
(River, 1)
(River, 1)
(River, 1)
(spark, 1)
(Spark , 1)
(Spark , 1)
(Spark , 1)
经过处理后得到的结果为:
key: hello value: List(1, 1, 1)
key: spark value: List(1, 1, 1,1)
所以reduce()函数的形参 Iterable<IntWritable> values 接收到的值为List(1, 1, 1)和List(1, 1, 1,1)
(3)Main函数
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountMain {
//若在IDEA中本地执行MR程序,需要将mapred-site.xml中的mapreduce.framework.name值修改成local
public static void main(String[] args) throws IOException,
ClassNotFoundException, InterruptedException {
if (args.length != 2 || args == null) {
System.out.println("please input Path!");
System.exit(0);
}
//System.setProperty("HADOOP_USER_NAME","hadoop2.7");
Configuration configuration = new Configuration();
//configuration.set("mapreduce.job.jar","/home/bruce/project/kkbhdp01/target/com.kaikeba.hadoop-1.0-SNAPSHOT.jar");
//调用getInstance方法,生成job实例
Job job = Job.getInstance(configuration, WordCountMain.class.getSimpleName());
// 打jar包
job.setJarByClass(WordCountMain.class);
// 通过job设置输入/输出格式
// MR的默认输入格式是TextInputFormat,所以下两行可以注释掉
// job.setInputFormatClass(TextInputFormat.class);
// job.setOutputFormatClass(TextOutputFormat.class);
// 设置输入/输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 设置处理Map/Reduce阶段的类
job.setMapperClass(WordCountMap.class);
//map combine减少网路传出量
job.setCombinerClass(WordCountReduce.class);
job.setReducerClass(WordCountReduce.class);
//如果map、reduce的输出的kv对类型一致,直接设置reduce的输出的kv对就行;如果不一样,需要分别设置map, reduce的 输出的kv类型
//job.setMapOutputKeyClass(.class)
// job.setMapOutputKeyClass(Text.class);
// job.setMapOutputValueClass(IntWritable.class);
// 设置reduce task最终输出key/value的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 提交作业
job.waitForCompletion(true);
}
}2本地运行
首先更改mapred-site.xml文件配置
将mapreduce.framework.name的值设置为local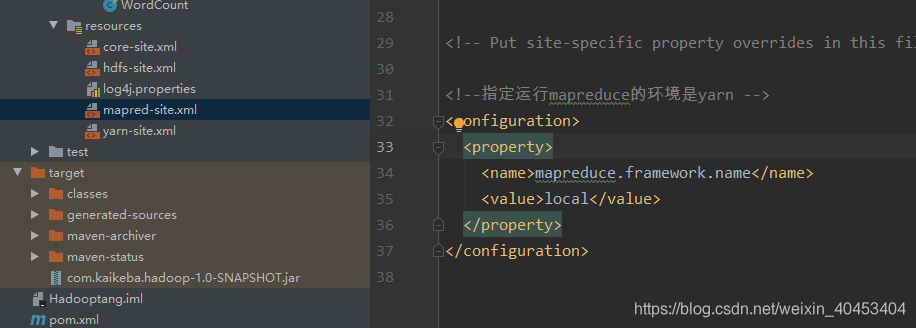
然后本地运行: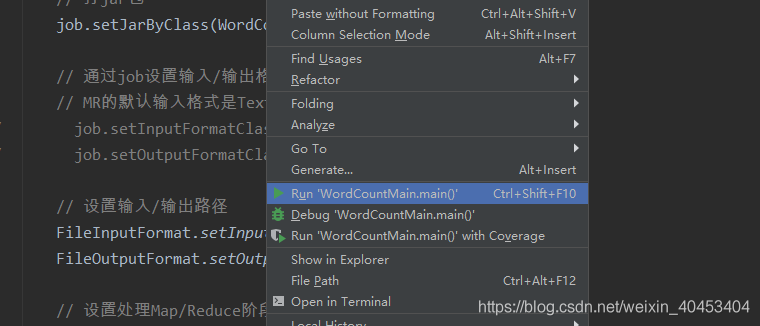
查看结果: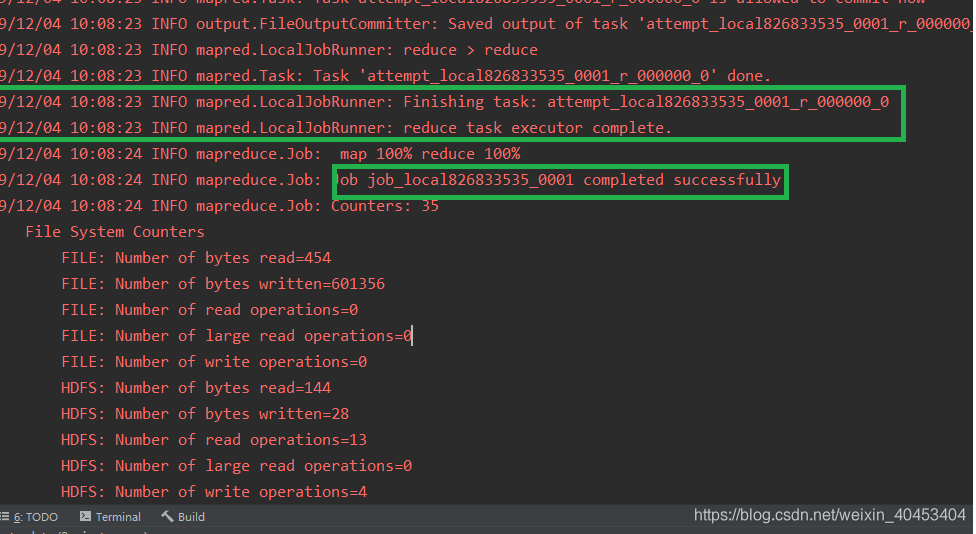
3集群运行
方式一:
首先打包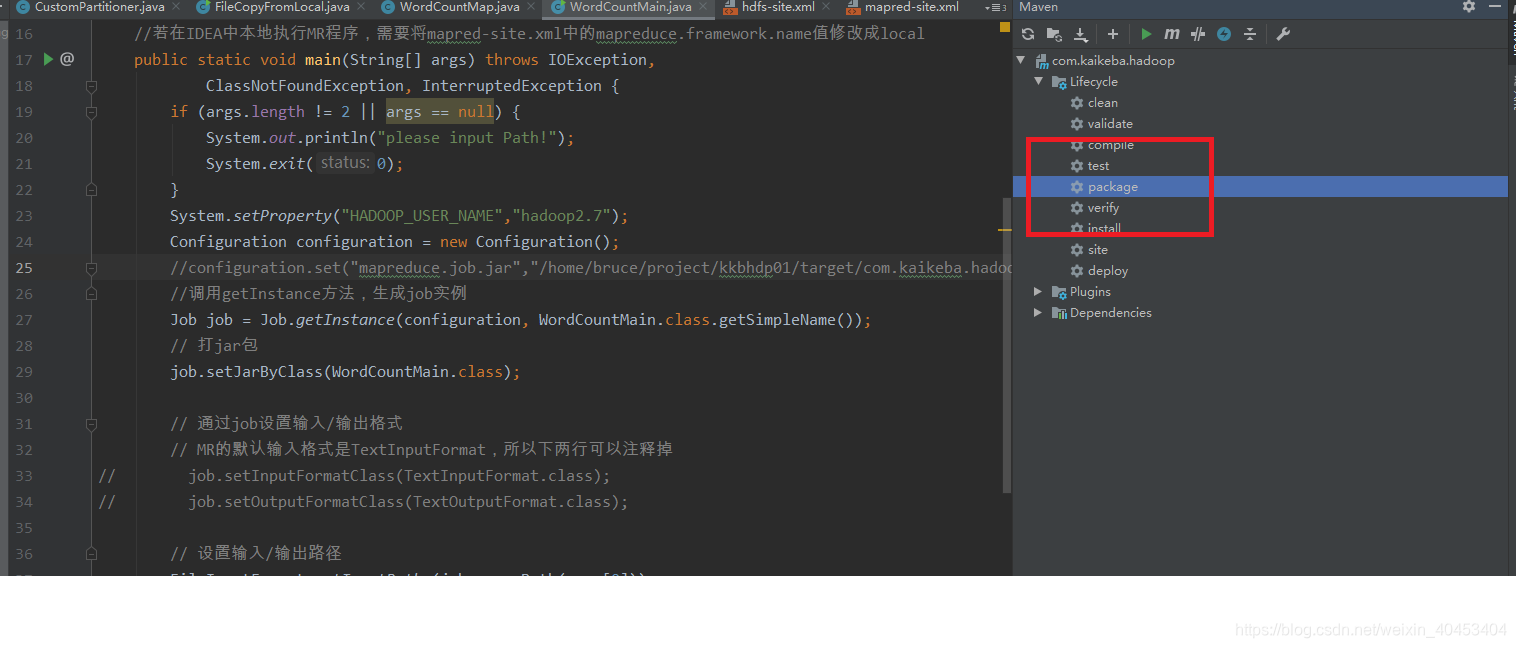
更改配置文件,改成yarn模式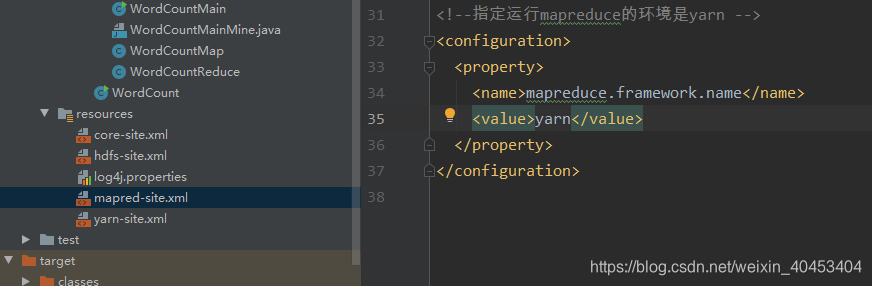
添加本地jar包位置:
Configuration configuration = new Configuration();
configuration.set("mapreduce.job.jar","C:Users anglei1IdeaProjectsHadooptang arget");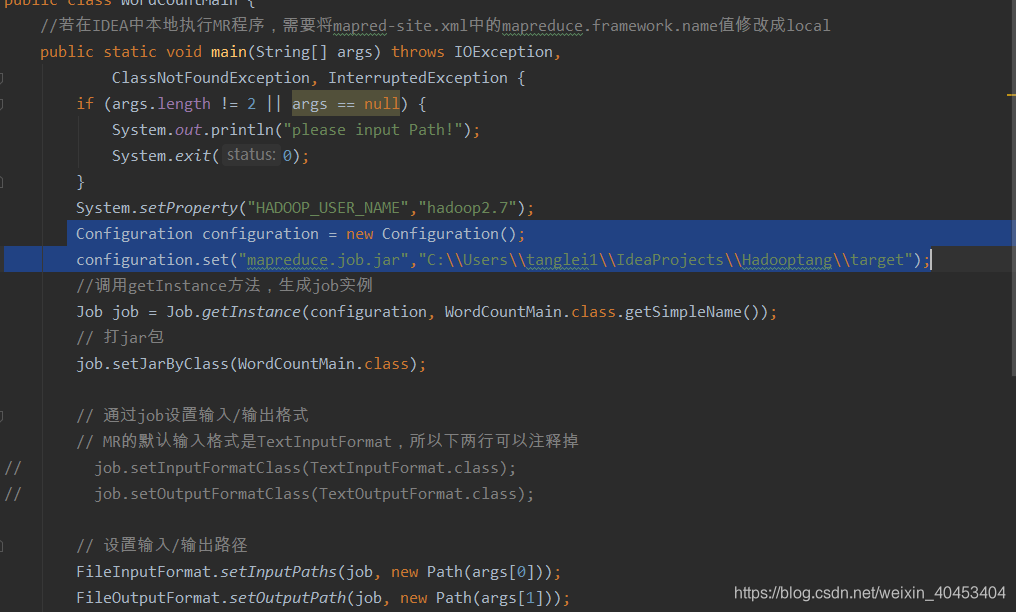
设置允许跨平台远程调用:
configuration.set("mapreduce.app-submission.cross-platform","true");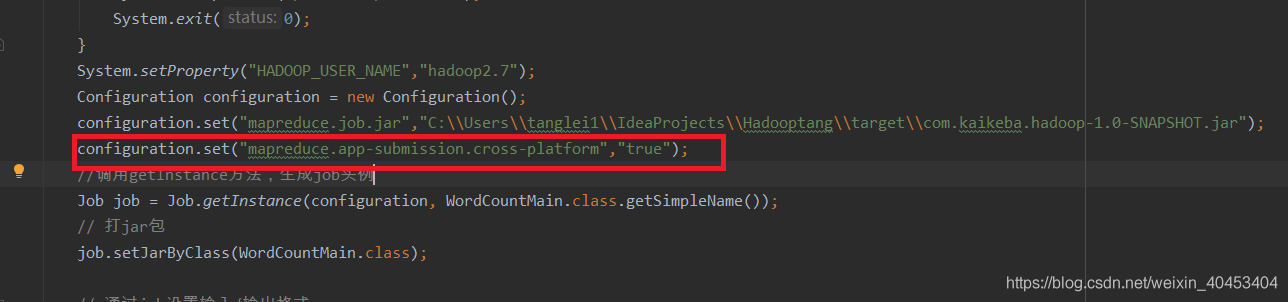
修改输入参数: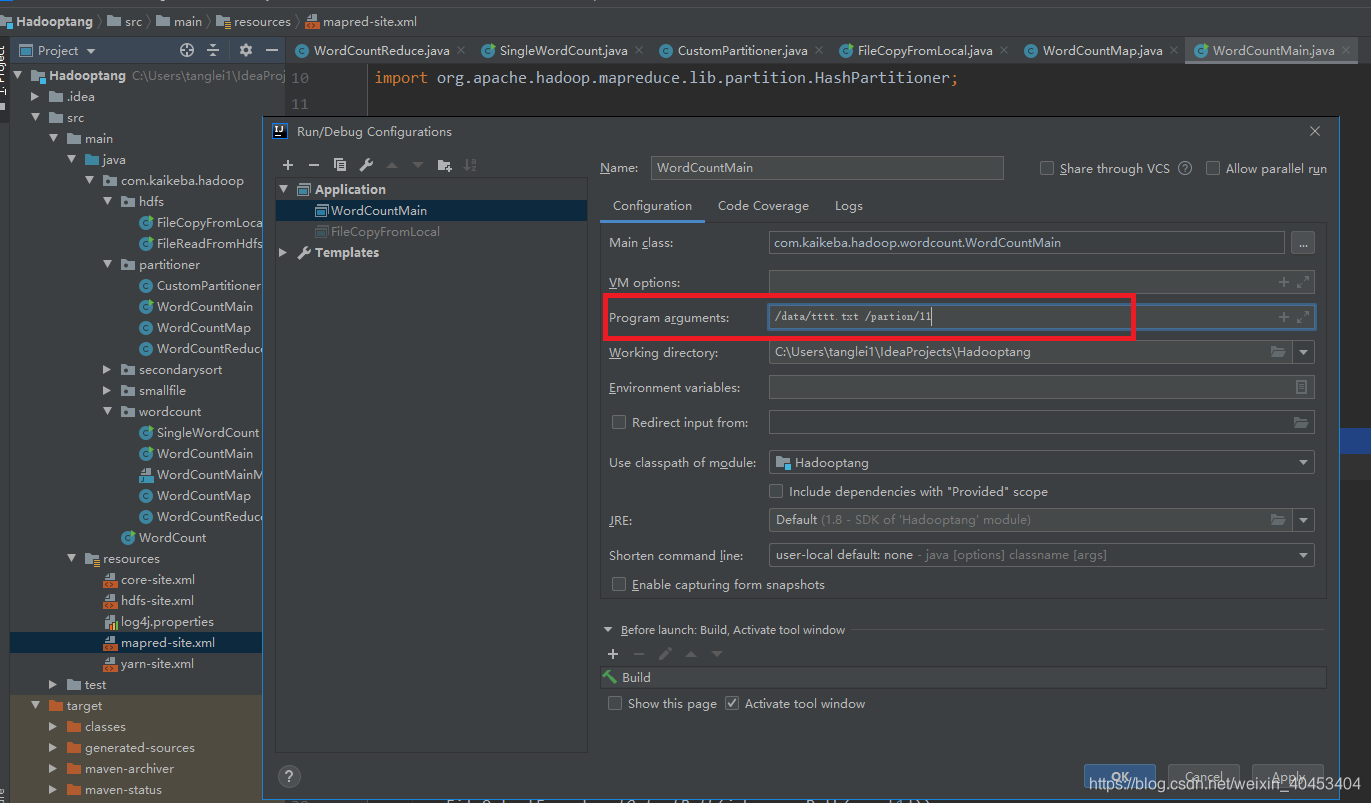
运行结果: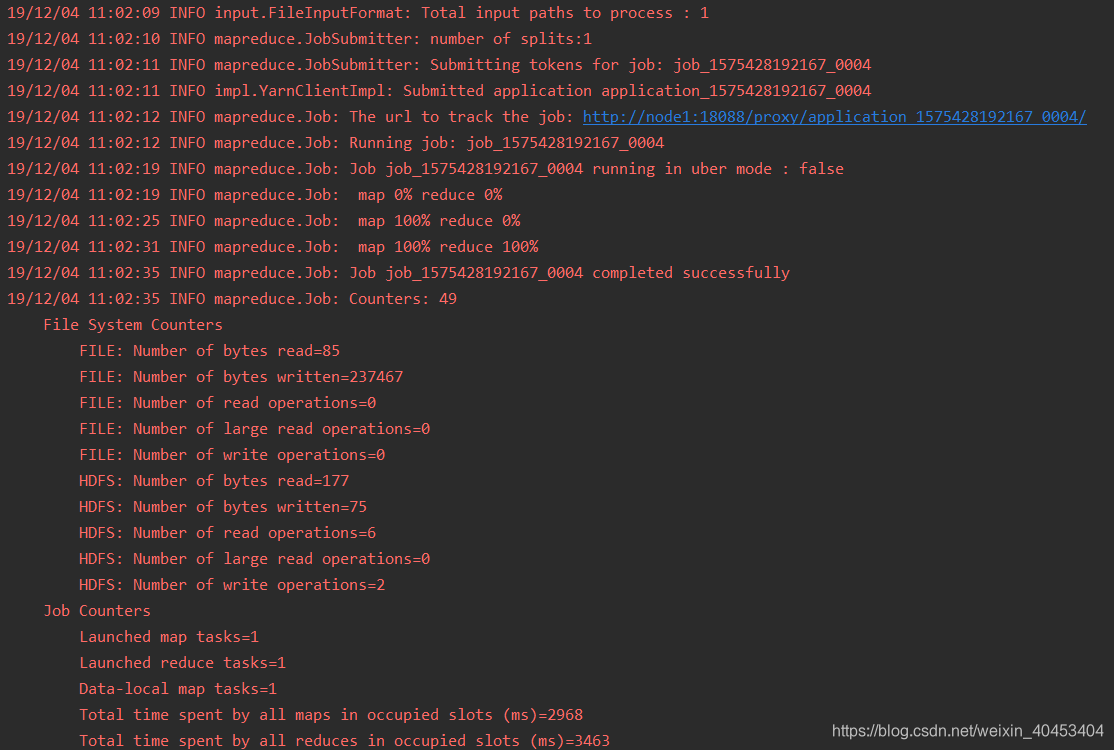
方式二:
将maven项目打包,在服务器端用命令运行mr程序
hadoop jar com.kaikeba.hadoop-1.0-SNAPSHOT.jar
com.kaikeba.hadoop.wordcount.WordCountMain /tttt.txt /wordcount11以上是关于Hadoop学习之路Mapreduce程序完成wordcount的主要内容,如果未能解决你的问题,请参考以下文章
Hadoop学习之路(十四)MapReduce的核心运行机制
Hadoop学习之路(十八)MapReduce框架Combiner分区