大数据---分布式任务资源调度Yarn
Posted bluedarkni
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据---分布式任务资源调度Yarn相关的知识,希望对你有一定的参考价值。
前面也说到过的Yarn是hadoop体系中的资源调度平台。所以在整个hadoop的包里面自然也是有它的。这里我们就简单介绍下,并配置搭建yarn集群。
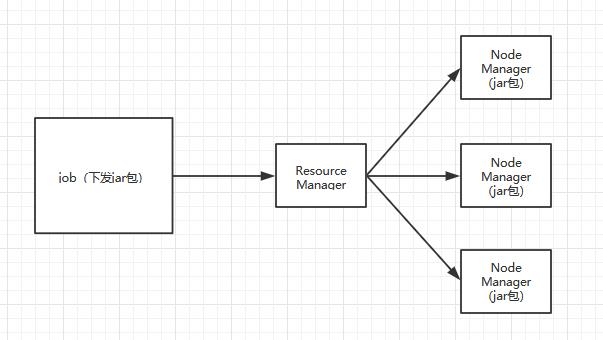
首先来说Yarn中有两大核心角色Resource Manager和Node Manager。
Resource Manager负责接收用户提交的分布式计算程序/任务,并为其划分资源,管理监控各个Node Manager。
Node Manager 接收resoResource Manager分配过来的任务,并计算。
通俗一点说就是计算程序会被打成一个jar包,然后分配到每个node manager上面去,这样每个node manager 执行的代码都是一样,只是可能数据源不一样。
集群配置:
node manager在物理上应该跟data node部署在一起,方便数据的读取
Yarn的软件在hadoop里面的都是有的,就和hdfs一样,我们只需要去配置一下,然后启动就可以了
每台机器都对etc/hadoop/yarn-site.xml进行配置
<property><!--配置redource manager-->
<name>yarn.resourcemanager.hostname</name>
<value>nijunyang68</value>
</property>
因为之前配置hdfs集群的时候已经在slaves中将集群IP的都配置进去了,所以现在只需要一键执行脚本就可以了:start-yarn.sh
注意在哪台机器启动redource manager就在那儿执行这个脚本,上面的配置只是告诉集群的中机器谁是redource manager,所以执行这个脚本需要在配置中的那个机器上面去执行。从日志中也可以看见,resource manager是在本机启动的,node manager是在其他机器上面启动的。

默认8088端口可以在web页面查看yarn集群信息
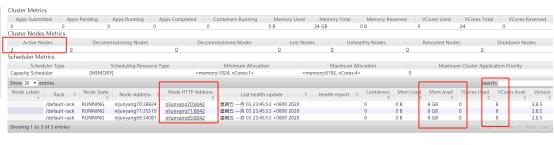
说一点,上面显示内存大小是不对的,因为我们没有配置,都是使用的默认,并不是我机器的实际值,实际上我的虚拟机总共才1G的内存

配置详情:https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1024</value>
</property>
内存有个最小分配限制1024,否则集群是无法启动的。
核数也并不是实际CPU的核数,我的虚拟机也才1核,这儿的意思是假如我内存200m,现在有一个任务需要100m内存,那么我这个机器就可以起两个任务,所以可以把核数配置成2,如果配置成那么久只能起一个任务。意思就是我CPU虽然是一核,但是我一个人100M,我200内存可以起两个任务,那么我CPU的运算能力就平均分给这两个任务。
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>2</value>
</property>
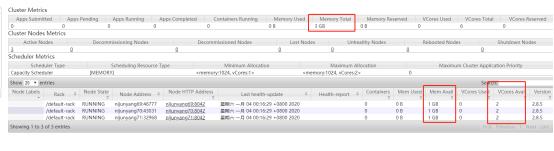
至此yarn集群就搭建完毕,后续就等着mapreduce任务丢上去运行了。
以上是关于大数据---分布式任务资源调度Yarn的主要内容,如果未能解决你的问题,请参考以下文章