Mysql聚簇索引和非聚簇索引
Posted learn-ontheway
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Mysql聚簇索引和非聚簇索引相关的知识,希望对你有一定的参考价值。
mysql聚簇索引和非聚簇索引
最近看了《高性能Mysql》那本书,总结下聚簇索引。
聚簇索引并不是一种单独的索引类型,而是一种数据存储方式,具体的细节依赖于实现方式,InnoDB的聚簇索引实际上在同一个结构中保存了B+Tree索引和数据行。
当表中有聚簇索引时,它的数据实际上存储在索引的叶子页中(叶子页中包含了行的全部数据)。而没有聚簇索引时B+Tree叶子页存放的是指向数据的指针。(页是mysql存储引擎最小的存储单元,InnoDB每个页默认大小为16k)可以理解为 有聚簇索引时,数据和对应的叶子页在同一页中,没有聚簇索引时,叶子页和对应的数据不在同一页中。
InnoDB存储引擎通过主键聚集数据(聚簇索引),如果没有定义主键,InnoDB会选择一个唯一的非空索引代替。如果没有唯一索引,InnoDB会隐式定义一个主键来作为聚簇索引。InnoDB 只聚集在同一个页面中的记录。包含相邻健值的页面可能相距甚远。
MyISAM中主键索引和其他索引 都指向物理行 (非聚簇索引)
下图展示了聚簇索引是如何存放的(图片来自《高性能MySQL(第三版)》):
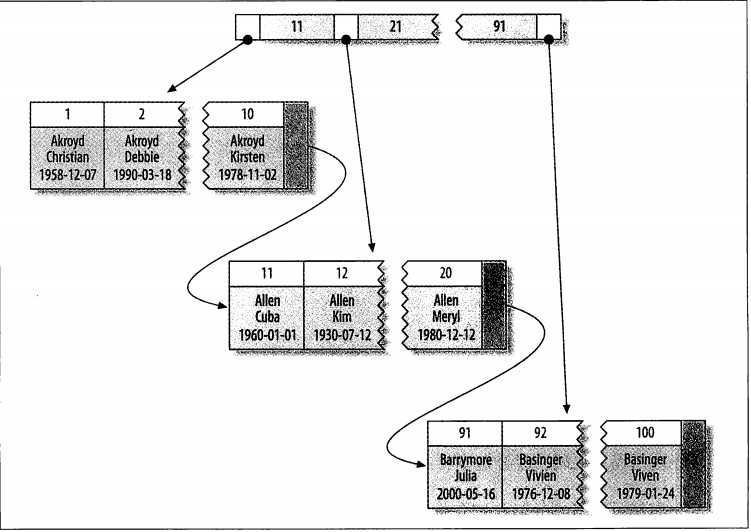
聚簇索引和非举措索引的区别:
聚簇索引,索引的顺序就是数据存放的顺序(物理顺序),只要索引是相邻的,那么对应的数据一定也是相邻地存放在磁盘上的。一张数据表只能有一个聚簇索引。(一个数据页中数据物理存储是有序的)
非聚簇索引通过叶子节点指针找到数据页中的数据,所以非聚簇索引是逻辑顺序。
聚集索引的优点:
1.数据存放的顺序和索引顺序一致,可以把相关数据保存在一起。例如实现电子邮箱时,可以根据用户 ID 来聚集数据,这样只需要从磁盘读取少数的数据页就能获取某个用户的全部邮件。如果没有使用聚簇索引,则每封邮件都可能导致一次磁盘 I/O。
2.数据访问更快,聚簇索引将索引和数据保存在同一个B-Tree中,因此从举措索引中获取数据通常比非聚簇索引查找更快。
3.使用覆盖索引扫描的查询可以直接使用页节点中的主键值(二级索引(非聚簇索引) 的叶子节点保存的不是指向行的物理位置的指针,而是行的主键值)。
(PS:覆盖索引:Mysql 可以使用索引来直接获取列的数据,这样就不需要查到索引后,然后通过叶子节点的指针回表读取数据行,如果索引的叶子节点中已经包含了或者说覆盖 所有需要查询的字段的值,那么就没有必要再回表查询了,这种称之为“覆盖索引”)
聚簇索引的缺点:
1.聚簇数据提高了IO性能,如果数据全部放在内存中,则访问的顺序就没那么重要了
2. 插入速度严重依赖插入顺序。按主键的顺序插入是速度最快的。但如果不是按照主键顺序加载数据,则需在加载完成后最好使用optimize table重新组织一下表
3.更新聚簇索引列的代价很高。因为会强制innod将每个被更新的行移动到新的位置
4.基于聚簇索引的表在插入新行,或主键被更新导致需要移动行的时候,可能面临页分裂的问题。页分裂会导致表占用更多的磁盘空间。
5.聚簇索引可能导致全表扫描变慢,尤其是行比较稀疏,或由于页分裂导致数据存储不连续的时
6.非聚集索引比想象的更大,因为二级索引的叶子节点包含了引用行的主键列
7.非聚集索引访问需要两次索引查找(非聚集索引中叶子节点保存的行指针指向的是行的主键值),对于innodb自适应哈希索引可以减少这样的重复工作
聚簇索引尽量选择有序的列(如AUTO_INCREMENT自增列),这样可以保证数据行是顺序写入,对于根据主键做关联操作的性能也会更好。
最好避免随机的(不连续且值的分布范围非常大)聚簇索引,特别是对于I/O密集型的应用。
从性能角度考虑,使用UUID来做聚簇索引会很糟糕,它使得聚簇索引的插入变得完全随机,这是最坏的情况,是的数据没有任何聚集的特性。
总结下使用类似UUID这种随机的聚簇索引的缺点:
1.UUID字段长,索引占用的空间更大。
2.写入是乱序的,InnoDB不得不频繁的做页分裂操作,以便新的行分配空间,页分裂会导致移动大量数据,一次插入最少需要修改三个页而不是一个页。
3.写入的目标页可能已经刷到磁盘上并从缓存中移除,或者还没有被加载到缓存中,InnoDB在插入之前不得不先找到并从磁盘读取目标页到内存中,这将导致大量的随机IO。
4.频繁的页分裂,页会变的稀疏并被不规则的填充,会产生空间碎片。
以上是关于Mysql聚簇索引和非聚簇索引的主要内容,如果未能解决你的问题,请参考以下文章