centos7安装hadoop3.2.1集群
Posted mufeng07
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了centos7安装hadoop3.2.1集群相关的知识,希望对你有一定的参考价值。
这次我安装的是hadoop3.2.1
一、下载Hadoop以及JDK
hadoop下载地址:http://mirrors.hust.edu.cn/apache/hadoop/common/
jdk参照:https://www.cnblogs.com/mufeng07/p/12150820.html
二、先一台虚拟机安装hadoop

1.修改主机
hostnamectl set-hostname hadoop01
vi /etc/hosts 追加
192.168.31.111 hadoop01
192.168.31.112 hadoop02
192.168.31.113 hadoop03
2.安装JDK
jdk参照:https://www.cnblogs.com/mufeng07/p/12150820.html
3.安装hadoop
sftp上传
tar -zxvf hadoop-3.2.1.tar.gz
4.修改hadoop配置文件
/home/hadoop/hadoop-3.2.1/etc/hadoop
修改core-site.xml
在<configuration>节点内加入配置:
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop01:9000</value>
</property>
修改hadoop-env.sh
export JAVA_HOME=/root/jdk1.8.0_151
修改hdfs-site.xml
在<configuration>节点内加入配置:
<property> <name>dfs.name.dir</name> <value>/root/hadoop/dfs/name</value> <description>Path on the local filesystem where theNameNode stores the namespace and transactions logs persistently.</description> </property> <property> <name>dfs.data.dir</name> <value>/root/hadoop/dfs/data</value> <description>Comma separated list of paths on the localfilesystem of a DataNode where it should store its blocks.</description> </property> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.permissions</name> <value>false</value> <description>need not permissions</description> </property>
说明:dfs.permissions配置为false后,可以允许不要检查权限就生成dfs上的文件,方便倒是方便了,但是你需要防止误删除,请将它设置为true,或者直接将该property节点删除,因为默认就是true。
新建并且修改mapred-site.xml
cp mapred-site.xml mapred-site.xml.template
在<configuration>节点内加入配置:
<property> <name>mapred.job.tracker</name> <value>hadoop01:49001</value> </property> <property> <name>mapred.local.dir</name> <value>/root/hadoop/var</value> </property> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
修改worker文件
去掉localhost
hadoop01
hadoop02
修改yarn-site.xml文件
在<configuration>节点内加入配置:
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<description>The address of the applications manager interface in the RM.</description>
<name>yarn.resourcemanager.address</name>
<value>${yarn.resourcemanager.hostname}:8032</value>
</property>
<property>
<description>The address of the scheduler interface.</description>
<name>yarn.resourcemanager.scheduler.address</name>
<value>${yarn.resourcemanager.hostname}:8030</value>
</property>
<property>
<description>The http address of the RM web application.</description>
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:8088</value>
</property>
<property>
<description>The https adddress of the RM web application.</description>
<name>yarn.resourcemanager.webapp.https.address</name>
<value>${yarn.resourcemanager.hostname}:8090</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>${yarn.resourcemanager.hostname}:8031</value>
</property>
<property>
<description>The address of the RM admin interface.</description>
<name>yarn.resourcemanager.admin.address</name>
<value>${yarn.resourcemanager.hostname}:8033</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
<discription>每个节点可用内存,单位MB,默认8182MB</discription>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
注意:端口号与里面的值,后期优化配置需要修改,第一次配可以全复制。
说明:yarn.nodemanager.vmem-check-enabled这个的意思是忽略虚拟内存的检查,如果你是安装在虚拟机上,这个配置很有用,配上去之后后续操作不容易出问题。如果是实体机上,并且内存够多,可以将这个配置去掉。
修改完毕!
三、复制虚拟机
参照https://www.cnblogs.com/mufeng07/p/12150766.html
复制两台:hadoop02、hadoop03
分别需要修改的如下:
1.主机名
2.core-site.xml 主机名
3.mapred-site.xml 主机名
4.worker文件 主机名
5.yarn-site.xml文件 主机名
四、设置三台虚拟机SSH免密互登
ssh-keygen -t dsa
在命令执行过程中敲击两遍回车,然后在/root/.ssh文件下生成id_dsa id_dsa.pub
在该文件下建立一个authorized_keys文件,将id_dsa.pub文件内容拷贝到authorized_keys文件中
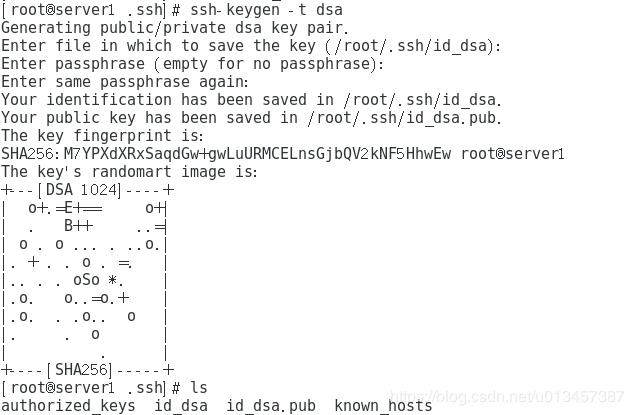
另外两个虚拟机也执行 #ssh-keygen -t dsa操作,并分别将id_dsa.pub内容拷贝到第一台虚拟机的authorized_keys文件中。将第一台的authorized_keys文件拷贝到另外两台虚拟机的/root/.ssh/ 下面。
ssh-dss AAAAB3NzaC1kc3MAAACBAP5rbDGfJ7HxfPGk35haclralPHOauYFvLY53OFPtTfyOy6+AxddT0XJ/W0HRLwVg7K5ZveF+aY3xg+61w7UP+l3SAOXWPLg7Woxzm8EGyqneMAmAepLr4s6RibU357mfcYpZRGHyMXI9c75P7QDoIHwxr0y2XzPFvo4QN0WRgNfAAAAFQC4MSpQCv5uqF61TMamdgJuNHqtIQAAAIAGONuwff9jZYRLC/cf3iVqbnjfeZpFaYgk4l7t3Kkbuz16xHKPRd/MpeFR5S/D/1O+jlk7dM76gjak5/PvdvX/Lejrg+hhaHU9crf3/bbDzPR+s5oaCEL4KS9mUS/Plhz7ILtj4+terClNK5RVcQAkyZmcRg6sHyIU5/LgTk3KowAAAIEAnDGlXNzZNC38+YUPj/QMzID/2dq0cvj+H181Ep4s8+qE+9zmG92RifQlZgxxgVdBAzUfipsKzjOKcBYjnf4+0BOcaoi+SEJ1pqWlsy7nXr931yXzw3YborthxBWx/dx7idCelYVZeMQkAphmnyzA76itVLlcyCm5ekBrUCGNGGg= root@hadoop01
ssh-dss AAAAB3NzaC1kc3MAAACBAPKeUzTBrdQ/BPh4BMXMHNw+7vAkwLDuK8zxGy6+WglB+QgPkh3OKBf1oxXSziouBtVIiNgXSJOiACsA4uqZMenpxWYbA+7+S3GPLed4BLRnOnGBQd1u5vgEChWgC1VQxqk+6/dNFjLJsKHCngoUH2uNON8BNsyUB2tt3cy/+NHpAAAAFQChXUqK9hXquhTfyW5wfDevWyw1oQAAAIA2FnXvvJAJCe0GPxKWn6uWT0L5dvpBUwbBXFP0JCVAgjHibRHICbfFrGvVb1+o/p5YH+1Zx0UDTVTgW+JO/YBRW2UDeEc32/L4CBDoSpZzDKERdR0nYT/XFIUJqDZX8U17LlHx26dmMQvsHftpNKubU/XI1aTsCoAonqdM4WFi7QAAAIEA2aFyp6IsQxSP+ivZ+tpK7IGG0/G0jtbVMPqBcQq9lMq2yfFsRCFjyzZCRSzIkWvwyihfU92sqvzcvUyRFzUYYRsznRfVYxQ+g+SMrWWP1sy67Xp+jvInApM/nDy790q2Hom1vjSFMzUpssv60SI1UFFAka46yxK346LMwaN8nlE= root@hadoop02
ssh-dss AAAAB3NzaC1kc3MAAACBAI/nI3AwYWgyBmYwYSF9NktpBBSyX7AkE9daDmF01vwgz3yuGgogfdPubKF1s1arPxoQtIBEoHEUpWwpKXwOsaxCjSZ9Z8nXd9CW1jkUW3++Y4c4DeCJ2kducC9smx7SMgo/9oDCFMt7lrRPJWU9vs0axP+Wa/yffESpkHnROx/fAAAAFQCTEEoxC/dSenJqa/8Jo56wyJ76/wAAAIAzyA+nGq/11qMhUrq9DaJ4zFgbhQqgHVcQcxbX/JVy0znd3V7tgVEOj3tNcNN028Kcr6WHw1Z8MUX+85zlHGIYvSmUTRZUEUczWVlx3d4sBqiSAUDvbcg5iTEhRIsSZf4WS6Hwxv4QwS2TufzRorjD40qx7Z/HZGi67hEfs/4dSAAAAIBcUIjv2KizduwbbFOEvsYxYfeVJxSGM4sRNhpeOAveKGUkRQDyqafJzqC9VIQfFoDN6tBXvY6bDa6x7dhbLZBkIrR8jT1F0YHxUIx22c+qfoMzWthxRDBHqPk4+q7Rogd6efNy90iO7MfOWADlCvoUhvhuaXY9guZMrtXQD6VM9Q== root@hadoop03
五、启动Hadoop
因为hadoop01是namenode,hadoop02和hadoop03都是datanode,所以只需要对hadoop01进行初始化操作,也就是对hdfs进行格式化。
(1)进入到hadoop01这台机器的/home/hadoop/hadoop-3.2.1/bin目录,也就是执行命令:
cd /home/hadoop/hadoop-3.2.1/bin
执行初始化脚本,也就是执行命令:
./hadoop namenode -format
等几秒没报错就是执行成功,格式化成功后,可以在看到在/root/hadoop/dfs/name/目录多了一个current目录,而且该目录内有一系列文件。

(2)在namenode上执行启动命令
在/home/hadoop/hadoop-3.2.1/sbin目录下修改:
vi start-dfs.sh
vi stop-dfs.sh
1.在start-dfs.sh 、stop-dfs.sh两个文件开头位置添加如下配置:
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=root
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
注意:一定要是开头位置。
vi start-yarn.sh
vi stop-yarn.sh
2.在start-yarn.sh 、stop-yarn.sh两个文件开头位置添加如下配置:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=root
YARN_NODEMANAGER_USER=root
因为hadoop01是namenode,hadoop02和hadoop03都是datanode,所以只需要再hadoop01上执行启动命令即可。
进入到hadoop01这台机器的/home/hadoop/hadoop-3.2.1/sbin目录
执行初始化脚本,也就是执行命令:
./start-all.sh
[root@hadoop01 sbin]# ./start-all.sh WARNING: HADOOP_SECURE_DN_USER has been replaced by HDFS_DATANODE_SECURE_USER. Using value of HADOOP_SECURE_DN_USER. Starting namenodes on [hadoop01] 上一次登录:日 1月 5 22:24:12 CST 2020从 192.168.31.16pts/0 上 hadoop01: Warning: Permanently added \'hadoop01,192.168.31.111\' (ECDSA) to the list of known hosts. Starting datanodes 上一次登录:日 1月 5 22:56:10 CST 2020pts/0 上 hadoop03: WARNING: /home/hadoop/hadoop-3.2.1/logs does not exist. Creating. hadoop02: WARNING: /home/hadoop/hadoop-3.2.1/logs does not exist. Creating. Starting secondary namenodes [hadoop01] 上一次登录:日 1月 5 22:56:14 CST 2020pts/0 上 Starting resourcemanager 上一次登录:日 1月 5 22:57:07 CST 2020pts/0 上 Starting nodemanagers 上一次登录:日 1月 5 22:57:54 CST 2020pts/0 上
启动成功,庆祝一下。
hadoop01是我们的namanode,该机器的IP是192.168.31.111,在本地电脑访问如下地址:
http://192.168.31.111:9870/
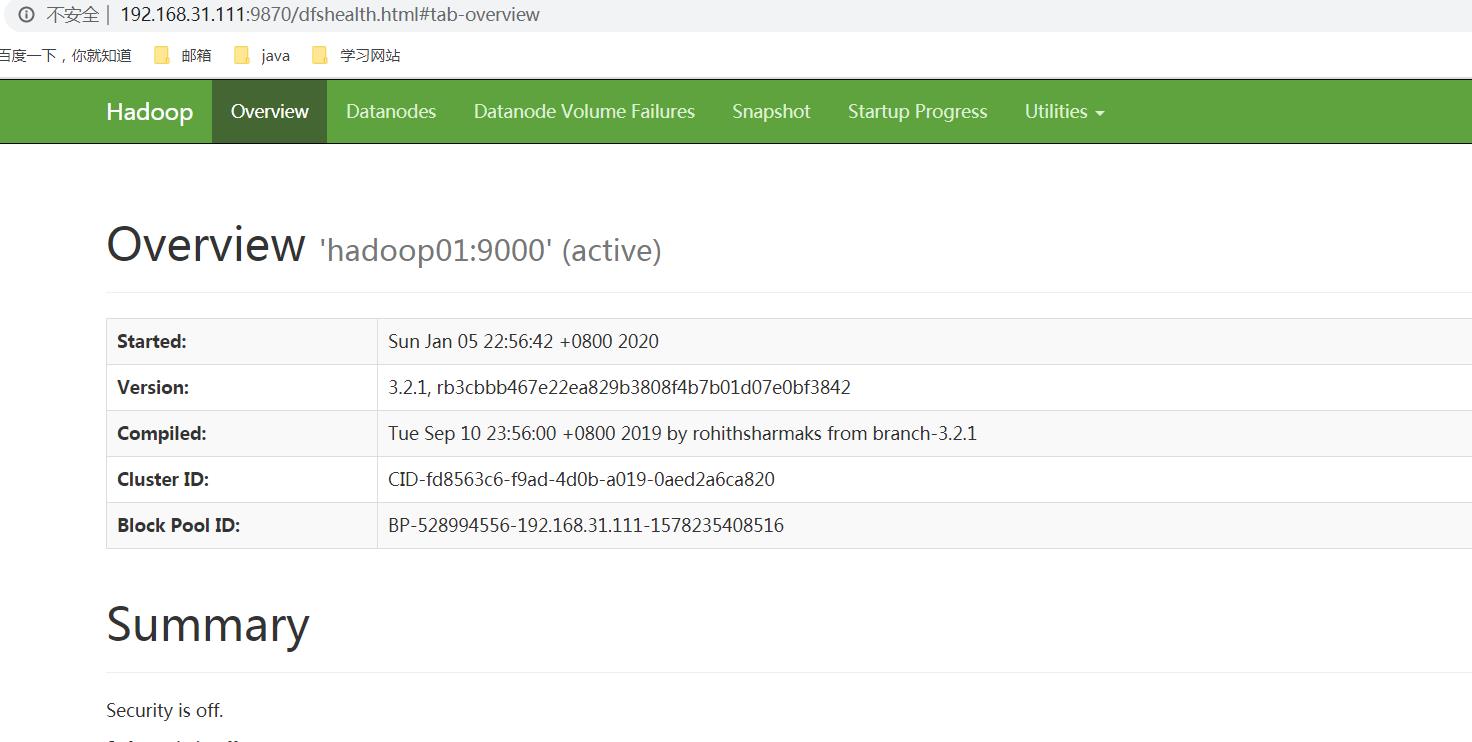
关闭hadoop
./stop-dfs.sh
感谢!
参照:https://blog.csdn.net/u013457387/article/details/87856770
以上是关于centos7安装hadoop3.2.1集群的主要内容,如果未能解决你的问题,请参考以下文章