Python-sklearn数据预处理(单/多个数据集数据标准化稳健标准化缺失值填补)
Posted 一抹light
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python-sklearn数据预处理(单/多个数据集数据标准化稳健标准化缺失值填补)相关的知识,希望对你有一定的参考价值。
Python-sklearn数据预处理(单/多个数据集数据标准化、稳健标准化、缺失值填补)
前言
hello大家好这里是小L😊,上一篇简单地介绍sklearn相关概念以及其常见的三个内置数据集(iris、boston、digits),对sklearn内置数据集有一定了解🙌
这次笔记内容:简单复习上篇笔记sklearn三板斧(具体可看上一篇笔记),学习sklearn数据预处理部分👉其中包括不同情况下的数据标准化以及遇到异常值或缺失值情况该如何对数据进行处理👈数据集用sklearn内置数据及进行举例🌷。
小L希望可以在这里与大家一起进步!💪
一、 三板斧
1. 概念
三板斧分为三个步骤:实例化–>fit 拟合–>transform转化 or Predict预测,我的理解是选择/构建模型->训练模型->将新数据集放入训练好的模型中。就好比把大象放入冰箱需要三个步骤:打开冰箱–>把大象放入冰箱–>关闭冰箱门。
2.实操代码
(1)导入boston数据集
- 导入boston数据集
from sklearn.datasets import load_boston
boston=load_boston()
- 转化为数据框
import pandas as pd
boston_df = pd.DataFrame(boston.data,columns=boston.feature_names)
boston_df

(2)三板斧举例
- 数据预处理
from sklearn.preprocessing import StandardScaler#预处理(可去除量缸影响)
std= StandardScaler(with_mean=False)#实例化
std.fit(boston.data)#训练
std.transform(boston.data)#转化或预测predict

在模型了解这块有两个小tip🙋
🚩利用help()可进行模型查询,里面会进行对查询模型的详细解答,可着重查看Parameters参数部分,部分结果如图。例如:help(StandardScaler) #模型查询
🚩在实例化后查看、设置模型参数from sklearn.preprocessing import StandardScaler std =StandardScaler() std.get_params()#查看当前参数
std.set_params(copy=False)#设置参数值
std.get_params()#再次查看参数
设置好参数后进行模型训练std.fit(boston.data)
最后结果std.scale_#boston有13个特征
std.mean_#标准化后的期望
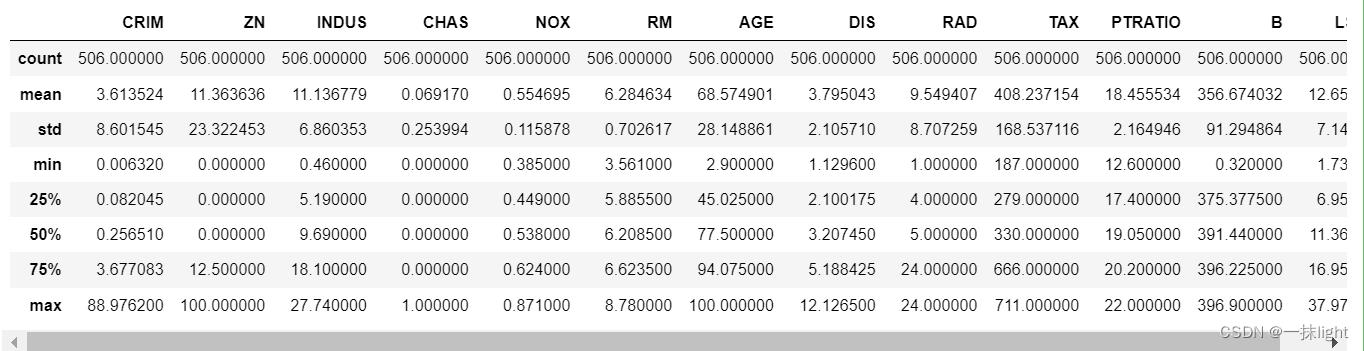
boston_df.describe()

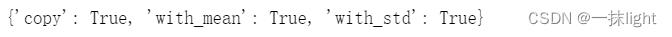
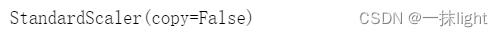
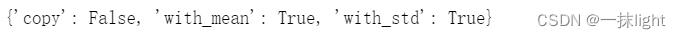



- 岭回归
from sklearn .linear_model import Ridge#岭回归
ridge = Ridge()
ridge.fit(boston.data,boston.target)

ridge.predict(boston.data)
部分运行结果如下:
此外还可以将训练好的模型进行保存、持久化使用,下次可直接拿出来使用。👍
保存岭回归模型!pip install joblib #安装joblib import joblib #模型保存,持久化 joblib.dump(ridge,r'C:\\Users\\lenovo\\ridge20220923.pkl')#将岭回归模型保存
将保存好的模型导入std2 = joblib.load(r"C:\\Users\\lenovo\\ridge20220923.pkl")
导入后可直接使用from sklearn.datasets import load_boston boston = load_boston() std2.predict(boston.data)#保存后可直接使用部分运行结果如下:
二、数值型变量的标准化
1.概念
- 减去均数:去除均数影响 with_mean = True
- 除以标准差:去除离散程度影响 with_std = True
- 标准化仍收受离群值影响
2.实操代码
(1)对单个数据集进行标准化
sklearn.preprocessing.scale(
X:需要进行变换的数据阵,
axis=0 :默认按列,
with_mean = True :减去均数,去除均数影响 ,
with_std = True :除以标准差,去除离散程度影响,
copy=True :默认替换原始数据,False生成副本
)
from sklearn import preprocessing
boston_scale=preprocessing.scale(boston_df)
boston_scaled#没有太大的数或太小的数

- 对数据集中不同列的数据进行标准化
preprocessing.scale(boston.target)
preprocessing.scale(boston_df[['CRIM','ZN']])#对某些列进行标准化

类实例化再做后续工作,函数直接调用
boston_scaled.mean(axis=0)#axis=0表示列

boston_scaled.std(axis=0)
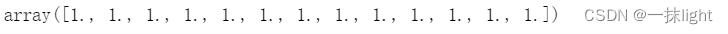
- 对行进行标准化:axis=1
preprocesing.scale(boston,axis=1)
#boston_scaled.mean(axis=1)#axis=0表示列
boston_scaled.mean(axis=0)#axis=0表示列

(2)在多个数据集上使用相同的标准化变换
class sklearn.preprocessing.StandardScaler()
- StandardScaler类方法:
- StandardScaler类属性:


std = preprocessing.StandardScaler()
std.fit(boston_df)
std.mean_,std.scale_ #fit之后求出了原始数据每列均值和标准差

std.transform(boston_df)

std.transform(boston_df[:3])

(3)将特征变量缩放至特定范围

驼峰命名原则(三大步)
- class sklearn.preprocessing.MinMaxScaler(feature_rang=(0,1),copy=True) 将每个特征最大绝对值转换成指定数值大小
- class sklearn.preprocessing.MaxAbsScaler(copy=True) 最大值缩放成1
help(preprocessing.MaxAbsScaler)

scaler = preprocessing.MinMaxScaler((1,10))#将每个特征最大绝对值转换成指定数值大小
scaler.fit_transform(boston_df)

scaler_1 = preprocessing.MaxAbsScaler()#最大值缩放成1
scaler_1.fit_transform(boston_df)

(4)数据的正则化—求单位向量
向量空间模型转化,常使用在分类与聚类模型中
sklearn.preprocessing.normalize(
X,axis=1,copy=True
norm=‘l2’ :距离方法l2欧几里得距离,‘l1’、‘l2’、'max’用用正则化具体范数,
return_norm=False:是否返回所使用的范数
)
import sklearn.preprocessing
x=[[-1,-1,2]]#向量用双层的中括号
x_normalized = preprocessing.normalize(x,norm='l2',return_norm =True)
x_normalized
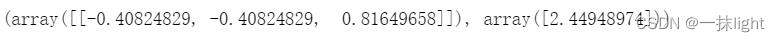
-1/2.44948974
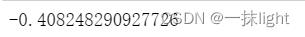
(5)考虑异常值标准化—稳健标准化
将中位数和百分位数(默认使用四分位间距)分别代替均数和标准差来进行标准化
适用于已知有离群值数据
- sklearn.preprocessing.robust_scale(
)- class sklearn.preprocessing.RobustScaler(
)

preprocessing.robust_scale(boston_df)

rscaler = preprocessing.RobustScaler()
rs = rscaler.fit_transform(boston_df)#训练和转化合二为一
rs
rscaler_1 = preprocessing.RobustScaler()
rs_1 = rscaler_1.fit(boston_df)
rs_1_trans = rs_1.transform(boston_df)
rs_1_trans

import numpy as np
np.median(rs,axis=0)#中位数

rs.mean(axis=0)

rs.std(axis=1)#标准差

三、缺失值的填补

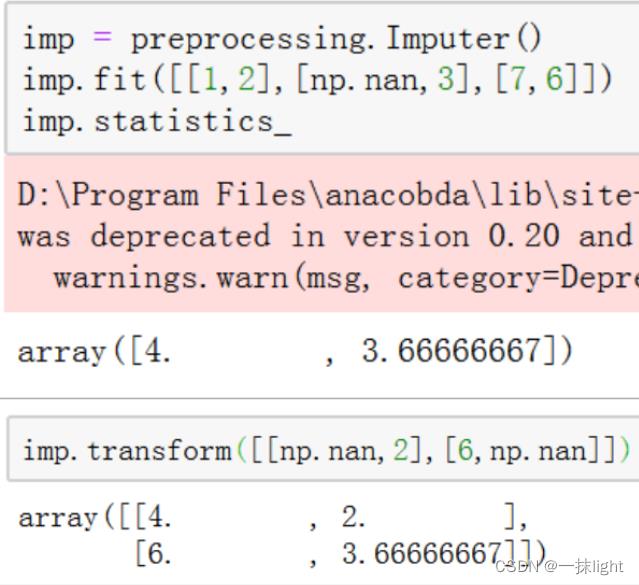
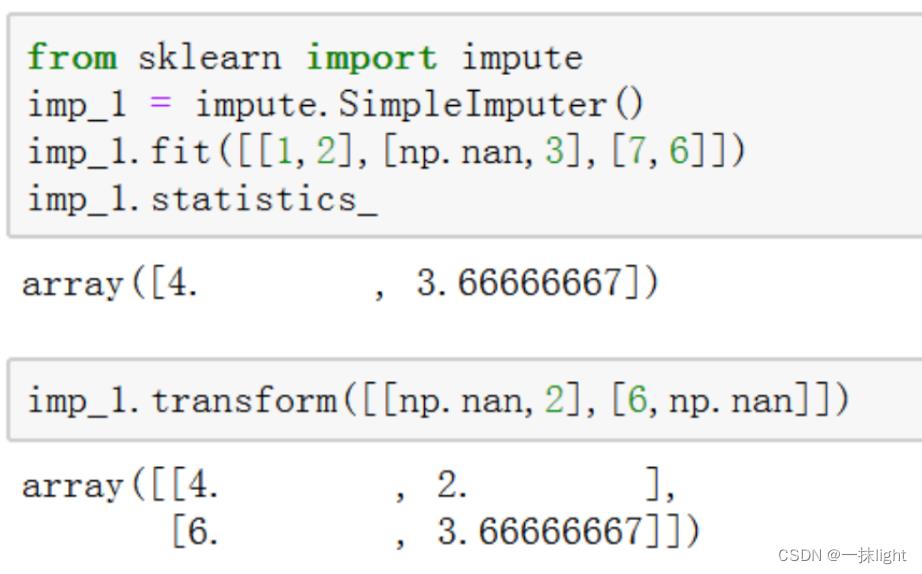
以上是关于Python-sklearn数据预处理(单/多个数据集数据标准化稳健标准化缺失值填补)的主要内容,如果未能解决你的问题,请参考以下文章