大数据-hive理论
Posted bug修复中
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据-hive理论相关的知识,希望对你有一定的参考价值。
本章分享的目录:
1:基础
第一节:简介与原理
2:设置用户及权限赋予
第二节:角色权限
3:安装 ,配置,连接
第三节:部署hive
4:参数动态设置
第四节:hive参数设置
第一节:简介与原理
简介:
数据仓库,对海量数据的离线处理(以HiveQL的形式,生成MR任务);
核心组件:
解释器,编译器,优化器;
举例:
HDFS或HBase ---映射--> HIVE表 -- HiveQL--> (MR)HDFS
存储:
元数据(metadata)------>关系型数据库
因为hdfs中存储的数据文件都是数据不包括数据的头等信息,所以元数据信息存储在关系型数据库。
数据文件------>hdfs
主要过程:
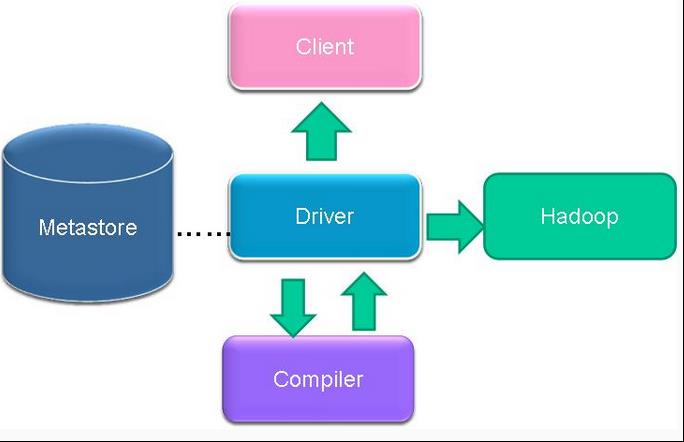
Hive --------HQL-------->MR(过程如下)
client发送请求 -------------->
driver驱动 -----> CLI(启动hive副本) ------>存储matedata ----->生成MR(hadoop执行)---->driver(结果返回)
------>compiler(解释器)
--------------> client接收结果
compiler:解释,编译,优化
Parser(分析程序):HQL ---> 抽象语法树
Semantic Analyzer(语法分析器):抽象语法树 ---> 查询块
Logical plan generator(逻辑计划生产器):查询块 ---> 逻辑查询计划
Logical optimizer(逻辑优化程序):优化(重写)逻辑计划
Physical plan generator(物理计划生产器):逻辑计划 ---> 物理计划(MR)
Physical optimizer(物理优化程序):优化MR
第二节:角色权限
(1):权限管理
1:三种授权模型:
1、Storage Based Authorization in the Metastore Server
基于存储的授权 - 可以对Metastore中的元数据进行保护,但是没有提供更加细粒度的访问控制(例如:列级别、行级别)。
2、SQL Standards Based Authorization in HiveServer2(推荐使用该模式)
基于SQL标准的Hive授权 - 完全兼容SQL的授权模型。
3、Default Hive Authorization (Legacy Mode)
hive默认授权 - 设计目的仅仅只是为了防止用户产生误操作,而不是防止恶意用户访问未经授权的数据
2:SQL Standards Based Authorization in HiveServer2(推荐使用该模式)
(1)完全兼容SQL的授权模型
(2)除支持对于用户的授权认证,还支持角色role的授权认证
role可理解为是一组权限的集合,通过role为用户授权
一个用户可以具有一个或多个角色
默认包含另种角色权限:public、admin
(3)限制(如果开启了权限管理之后):
1、启用当前认证方式之后,dfs, add, delete, compile, and reset等命令被禁用。
2、通过set命令设置hive configuration的方式被限制某些用户使用。
(可通过修改配置文件hive-site.xml中hive.security.authorization.sqlstd.confwhitelist进行配置)
3、添加、删除函数以及宏的操作,仅为具有admin的用户开放。
4、用户自定义函数(开放支持永久的自定义函数),可通过具有admin角色的用户创建,其他用户都可以使用。
5、Transform功能被禁用。
(4)如何开启权限
1、在hive服务端修改配置文件hive-site.xml添加以下配置内容:
<property>
<name>hive.security.authorization.enabled</name>
<value>true</value>
</property>
<property>
<name>hive.server2.enable.doAs</name>
<value>false</value>
</property>
<property>
<name>hive.users.in.admin.role</name>
<value>root</value>
</property>
<property>
<name>hive.security.authorization.manager</name>
<value>org.apache.hadoop.hive.ql.security.authorization.plugin.sqlstd.SQLStdHiveAuthorizerFactory</value>
</property>
<property>
<name>hive.security.authenticator.manager</name>
<value>org.apache.hadoop.hive.ql.security.SessionStateUserAuthenticator</value>
</property>
2、服务端启动hiveserver2;客户端通过beeline进行连接
(2):权限管理
beeline连接之后,Hive权限管理
1、角色的添加、删除、查看、设置:(角色)
CREATE ROLE role_name; -- 创建角色
DROP ROLE role_name; -- 删除角色
SET ROLE (role_name|ALL|NONE); -- 设置角色
SHOW CURRENT ROLES; -- 查看当前具有的角色
SHOW ROLES; -- 查看所有存在的角色
说明:root有两种角色:public,admin,默认的是public需要添加admin:set role admin,这个时候就是admin了。然后就会进行一些操作了。
2、用户的插入、移除、查看(用户):
SELECT privilege – gives read access to an object.
INSERT privilege – gives ability to add data to an object (table).
UPDATE privilege – gives ability to run update queries on an object (table).
DELETE privilege – gives ability to delete data in an object (table).
ALL PRIVILEGES – gives all privileges (gets translated into all the above privileges).
3、权限的授予、移除、查看(给角色、给用户)
3.1 将权限授予某个用户、角色:
语法:
GRANT role_name [, role_name] ...
TO principal_specification [, principal_specification] ...
[ WITH ADMIN OPTION ];
principal_specification
: USER user
| ROLE role
实例:grant admin(权限) to role test(角色) / user test(用户);
3.2 移除某个用户、角色的权限:
语法:
REVOKE [ADMIN OPTION FOR] role_name [, role_name] ...
FROM principal_specification [, principal_specification] ... ;
principal_specification
: USER user
| ROLE role
实例:revoke admin from role test(角色) / user test(用户);
3.3 查看授予某个用户、角色的权限列表
语法:
SHOW ROLE GRANT (USER|ROLE) principal_name;
实例:
查看用户、角色下的角色:
show role grant role test; 查看的是角色的权限
show role grant user test; 查看的是用户的权限
查看权限下的用户、角色:
SHOW PRINCIPALS role_name;
第三节:部署hive
三种搭建模式:
1:元数据存储在内存数据库(不用)
2:网络连接到数据库(常用)

3:远程服务器模式(解耦:只需要访问MetaStoreServer,不需要知道后面连的是那种关系型数据库)

安装过程:
1:安装mysql
Yum instail mysql-server
启动
Service mysqld start
开机启动
Chkconfig mysqld on
Mysql授权
grant all privileges on *.* to ‘root’@\'%’ identified by ‘youpassword’ with grant option
删除其他
Delete from user where host != ‘root’
刷新权限
Flush privileges
登录
Mysql -u -p
导入jar
导入mysql的连接驱动包,jline包到lib下
查看test表的详细信息(hive的)
desc formatted test;
2:远程服务器模式:
服务端(连接数据库):
配置 hive-site.xml
<property> <name>hive.metastore.warehouse.dir</name> 本地表的默认位置 <value>/user/hive/warehouse</value> </property> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://192.168.57.6:3306/hive?createDatabaseIfNotExist=true</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>123456</value> </property>
客户端:
<property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property> <property> <name>hive.metastore.uris</name> <value>thrift://node02:9083</value> </property>
配置hive高可用(推荐方式:HAProxy,可以:zk)
配置:其中一台
<property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://node01:3306/hive?createDatabaseIfNotExist=true</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>123456</value> </property> <property> <name>hive.server2.support.dynamic.service.discovery</name> <value>true</value> </property> <property> <name>hive.server2.zookeeper.namespace</name> //在zk中的文件夹 查看zkCil.sh ls / <value>hiveserver2_zk</value> </property> <property> <name>hive.zookeeper.quorum</name> <value>node1:2181,node2:2181,node3:2181</value> </property> <property> <name>hive.zookeeper.client.port</name> <value>2181</value> </property> <property> <name>hive.server2.thrift.bind.host</name> //所在IP <value>node2</value> </property> <property> <name>hive.server2.thrift.port</name> <value>10001</value> </property>
启动方式:
1、 服务端 hivemetastore:端口:9083
hive --service metastore
客户端:
hive
2、 服务端 hiveserver2(支持多个客户端的连接) 端口:10000
hiveserver2
客户端 beeline方式
beeline
!connect jdbc:hive2://node4:10000/default root 123(用户名密码不需要,但是随便给都行,不给不行)
或者
beeline -u jdbc:hive2://node4:10000/default(这个不需要用户名密码)
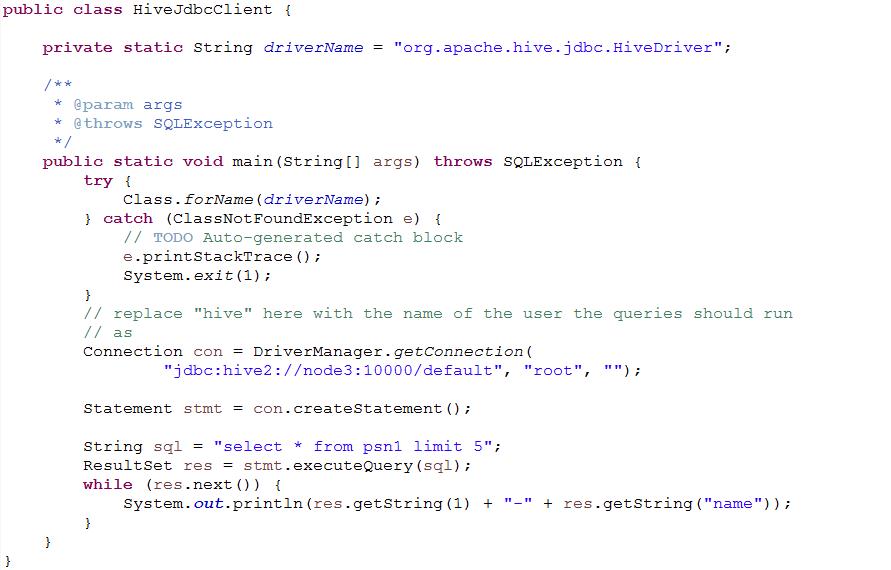
3、 代码JDBC连接
第四节:hive参数设置
1:例子
hiveconf hive.cli.print.header=true(可以看见hive表的头部信息)
2:设置方式
(1)在启动cli时候(只在当前会话有效)
hive --hiveconf hive.cli.print.header=true
(2)在已经启动的cli下(只在当前会话有效)
set hive.cli.print.header=true;
set hive.cli.print.header //查看这个值目前是什么
(3)在家目录下的 .hiverc 文件(永久有效),如果没有则创建该文件,在启动cli时候回加载这个文件中的配置
在文件中set hive.cli.print.header=true
~/.hivehistory 这个文件可以看见hive执行的历史指令
(4)hive-site.xml中配置
以上是关于大数据-hive理论的主要内容,如果未能解决你的问题,请参考以下文章