hadoop 大数据框架
Posted foremost
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop 大数据框架相关的知识,希望对你有一定的参考价值。
1、hadoop 大数据框架

Hadoop 是一个应用Java语言实现的软件框架,廉价的计算机组成的集群运行海量数据的分布式并行计算框架,
支持上千个节点和PB级别的数据。Hadoop是项目的总称
分布式:
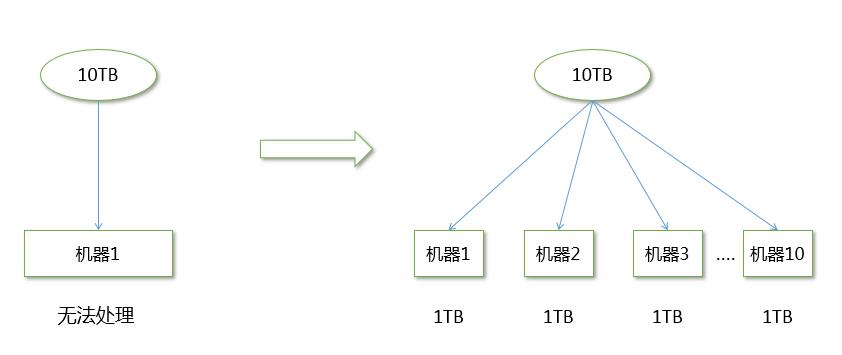
大数据: 指无法在一定时间范围内用常规软件工具进行捕捉,管理和处理的数据集合。
1024MB=1GB
1024GB=1TB
1024TB=1PB
1024PB=1EB
集群:很多台机器
hadoop集群(每台计算机都处理一部分数据)
Hadoop --- 衍生出整个生态体系 ---- 整个体系的基石
大数据框架:
离线部分:
hadoop
hbase : 非关系型数据库
主要学习hive
hive: 类sql语句,数据仓库,用于分析
协作框架:
zookeeper:
sqoop:
flume
oozie
实时部分:
spark
2、hadoop四大模块
Hadoop项目主要包括以下四个模块
◆ Hadoop Common:
为其他Hadoop模块提供基础设施
◆ Hadoop HDFS:
一个高可靠、高吞吐量的分布式文件系统
◆ Hadoop MapReduce:
一个分布式的离线并行计算框架
◆ Hadoop YARN:
一个新的MapReduce框架,任务调度与资源管理
hadoop 四大模块:
Hadoop Common:支持其他Hadoop模块的通用实用程序。
Hadoop分布式文件系统(HDFS):
当数据集的大小超过一台单独物理机的存储能力时,有必要对数据进行分区并存储到若干台计算机上。管理网络中跨计算机存储的文件系统称为分布式文件系统
解决存储问题:存储、
每台机器都提供本地计算和存
两个服务:
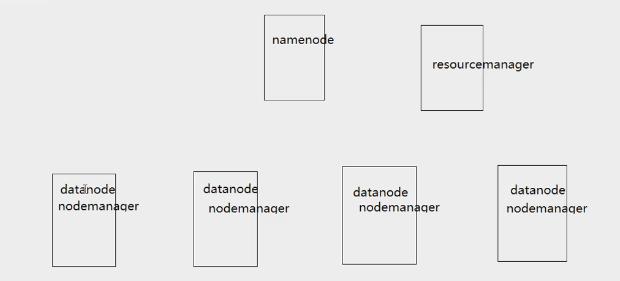
namenode: 文件系统的访问入口 计算文件切分多少块,每个块放在哪个DataNode节点上,监听DataNode节点,让每个块始终保持3个副本
datanode:存储数据,向namenode发送心跳信号
冗余 ---- 备份
1个数据块 block 副本
每一个块默认3个副本:
副本存放策略:
第一个副本放在某一个机架的某一个DataNode节点上
第二个副本放在同一个机架的另一个DataNode节点上
第三个副本放在另一个机架的某一个DataNode节点上
Hadoop 三种模式:
完全分布式:真正的集群
伪分布式:测试和学习 模拟hdfs
单机模式:测试和学习 磁盘
Hadoop分布式文件系统(HDFS)操作
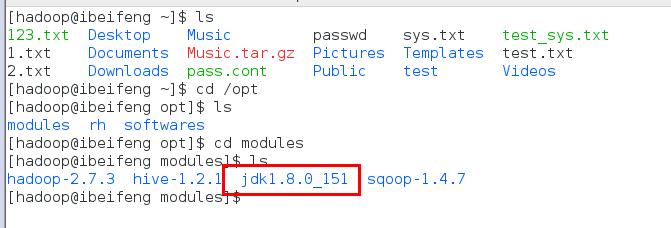
hadoop 安装路径:/opt/modules/hadoop-2.7.3 bin 对hdfs的操作命令 sbin 跟服务有关的命令 etc 配置文件 lib 依赖库 cd /opt/modules/hadoop-2.7.3
启动 sbin/hadoop-daemon.sh start namenode sbin/hadoop-daemon.sh start datanode
一定要在
网络映射:
#vi /etc/hosts
配置好ip

NameNode是主节点,存储文件的元数据如文件名,文件目录结构,文件属性(生成时间,副本数,文件权限),
以及每个文件的块列表和块所在DataNode等。
DataNode 在本地文件系统存储文件块数据,以及块数据的校验和。
http://192.168.80.71:50070 hdfs web 界面
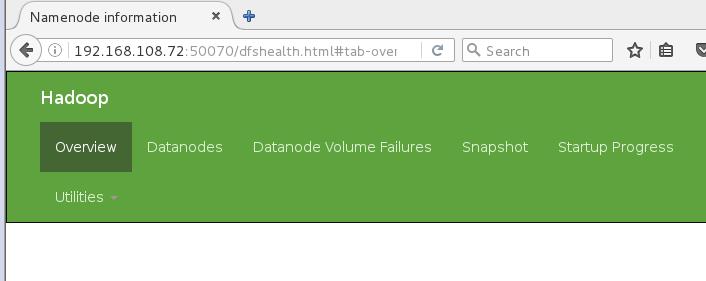
http://192.168.80.71:50070 hdfs web 界面 bin/hdfs dfs bin/hdfs dfs -ls / 查看hdfs根目录下文件 bin/hdfs dfs -mkdir /test29 在hdfs上创建目录 bin/hdfs dfs -put a.txt /test29 上传文件 bin/hdfs dfs -cat /test29/a.txt 查看文件内容 bin/hdfs dfs -rm /test29/a.txt 删除文件 优点: 运行海量数据,容错,扩展性 缺点: 不支持多用户同时写入,不支持修改文件,高延迟
Hadoop MapReduce
◆ 将计算过程分为两个阶段:Map和Reduce
Map阶段并行处理输入数据
Reduce阶段对Map结果进行汇总
◆ Shuffle链接Map和Reduce两个阶段
Map Task将数据写到本地磁盘
Reduce Task从每个Map Task上读取一份数据
◆ 仅适合离线批处理
具有很好的容错性和扩展性
适合简单的批处理任务
◆ 缺点明显
启动开销大,过多使用磁盘导致效率低下等
Hadoop YARN:用于作业调度和群集资源管理的框架。
Hadoop MapReduce:基于YARN的系统,用于并行处理大数据集
yarn:
resourcemanager:负责管理整个集群上的计算资源(cpu,内存,磁盘)
nodemanager:负责管理自己所在节点的计算资源
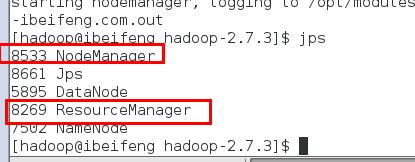
启动:
sbin/yarn-daemon.sh start resourcemanager
sbin/yarn-daemon.sh start nodemanager
用jps查看
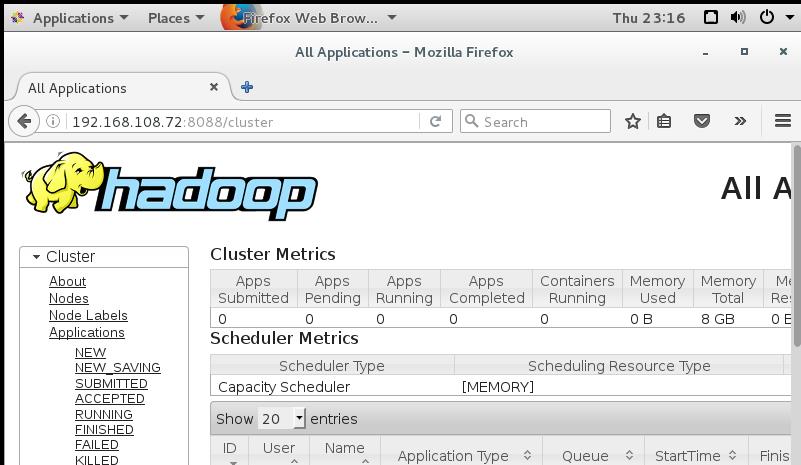
http://192.168.108.72:8088
MapReduce:
一个MapReduce程序可以被称为 application 或者 job
input--> map ----> shuffle-----> reduce -----> output
官方案例:单词统计案例 wordcount
jar包 ----- Java
计算的是hdfs分布式文件系统上的数据:
map的个数是由文件的大小决定的,map---- 128M
128M 1
128M 2
128M 3
50M 4
reduce 默认是1个 汇总 规约 合并
bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /test29/test.txt /output29
必须要有map阶段 可以没有reduce阶段
mapreduce 编程模型 Java
spss python linux spss
Linux系统环境部署
安装虚拟机+操作系统:VMware、CentOS
设置基础环境三要素:IP(NAT、静态)、主机名、映射(包括本地)
网络配置:设置DNS解析,Ping通外网
创建普通用户:useradd 用户名、passwd 用户名
设置Sudo权限:visudo
设置连接远程工具:secureCRT、FileZilla、Notepad++
禁用安全系统和防火墙:selinux、iptables、chkconfig iptables
卸载系统自带Open jdk并配置Oracle jdk:rpm -qa、-e、vi /etc/profile
Hadoop 2.x环境启动服务进程
HDFS模块启动:
$ sbin/hadoop-daemon.sh start namenode
$ sbin/hadoop-daemon.sh start datanode
YARN模块启动:
$ sbin/yarn-daemon.sh start resourcemanager
$ sbin/yarn-daemon.sh start nodemanager
111
以上是关于hadoop 大数据框架的主要内容,如果未能解决你的问题,请参考以下文章