1、认识Hadoop和Hbase
1.1 hadoop简单介绍
Hadoop是一个使用java编写的Apache开放源代码框架,它允许使用简单的编程模型跨大型计算机的大型数据集进行分布式处理。Hadoop框架工作的应用程序可以在跨计算机群集提供分布式存储和计算的环境中工作。Hadoop旨在从单一服务器扩展到数千台机器,每台机器都提供本地计算和存储。
1.2 Hadoop架构
Hadoop框架包括以下四个模块:
- Hadoop Common:这些是其他Hadoop模块所需的Java库和实用程序。这些库提供文件系统和操作系统级抽象,并包含启动Hadoop所需的必要Java文件和脚本。
- Hadoop YARN:这是作业调度和集群资源管理的框架。
- Hadoop分布式文件系统(HDFS):提供对应用程序数据的高吞吐量访问的分布式文件系统。
- Hadoop MapReduce: 这是基于YARN的大型数据集并行处理系统。
我们可以使用下图来描述Hadoop框架中可用的这四个组件。

自2012年以来,术语“Hadoop”通常不仅指向上述基本模块,而且还指向可以安装在Hadoop之上或之外的其他软件包,例如Apache Pig,Apache Hive,Apache HBase,Apache火花等
1.3 Hadoop如何工作?
(1)阶段1
用户/应用程序可以通过指定以下项目向Hadoop(hadoop作业客户端)提交所需的进程:
- 分布式文件系统中输入和输出文件的位置。
- java类以jar文件的形式包含了map和reduce功能的实现。
- 通过设置作业特定的不同参数来进行作业配置。
(2)阶段2
然后,Hadoop作业客户端将作业(jar /可执行文件等)和配置提交给JobTracker,JobTracker负责将软件/配置分发到从站,调度任务和监视它们,向作业客户端提供状态和诊断信息。
(3)阶段3
不同节点上的TaskTrackers根据MapReduce实现执行任务,并将reduce函数的输出存储到文件系统的输出文件中。
1.4 Hadoop的优点
- Hadoop框架允许用户快速编写和测试分布式系统。它是高效的,它自动分配数据并在机器上工作,反过来利用CPU核心的底层并行性。
- Hadoop不依赖硬件提供容错和高可用性(FTHA),而是Hadoop库本身被设计为检测和处理应用层的故障。
- 服务器可以动态添加或从集群中删除,Hadoop继续运行而不会中断。
- Hadoop的另一大优点是,除了是开放源码,它是所有平台兼容的,因为它是基于Java的。
1.5 HBase介绍
Hbase全称为Hadoop Database,即hbase是hadoop的数据库,是一个分布式的存储系统。Hbase利用Hadoop的HDFS作为其文件存储系统,利用Hadoop的MapReduce来处理Hbase中的海量数据。利用zookeeper作为其协调工具。
1.6 HBase体系架构
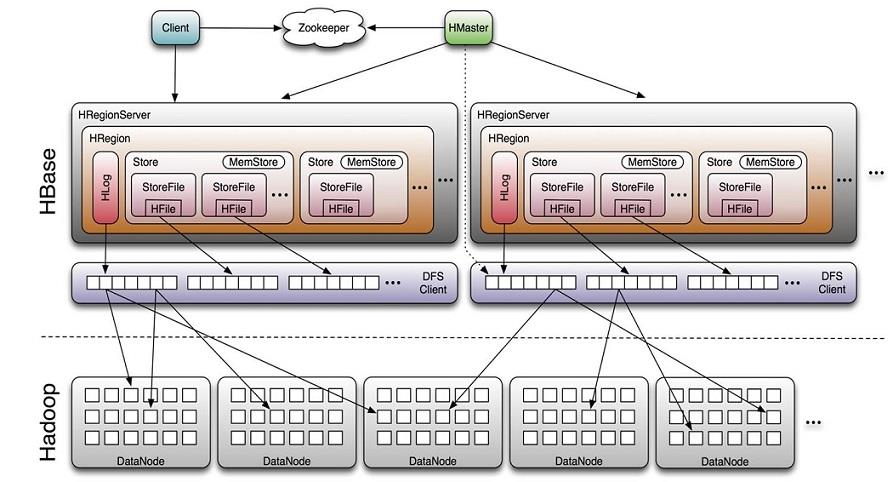
Client
- 包含访问HBase的接口并维护cache来加快对HBase的访问
Zookeeper
- 保证任何时候,集群中只有一个master
- 存贮所有Region的寻址入口。
- 实时监控Region server的上线和下线信息。并实时通知Master
- 存储HBase的schema和table元数据
Master
- 为Region server分配region
- 负责Region server的负载均衡
- 发现失效的Region server并重新分配其上的region
- 管理用户对table的增删改操作
RegionServer
- Region server维护region,处理对这些region的IO请求
- Region server负责切分在运行过程中变得过大的region
HLog(WAL log)
- HLog文件就是一个普通的Hadoop Sequence File,Sequence File 的Key是 HLogKey对象,HLogKey中记录了写入数据的归属信息,除了table和 region名字外,同时还包括sequence number和timestamp,timestamp是” 写入时间”,sequence number的起始值为0,或者是最近一次存入文件系 统中sequence number。
- HLog SequeceFile的Value是HBase的KeyValue对象,即对应HFile中的 KeyValue
Region
- HBase自动把表水平划分成多个区域(region),每个region会保存一个表 里面某段连续的数据;每个表一开始只有一个region,随着数据不断插 入表,region不断增大,当增大到一个阀值的时候,region就会等分会 两个新的region(裂变);
- 当table中的行不断增多,就会有越来越多的region。这样一张完整的表 被保存在多个Regionserver上。
Memstore 与 storefile
- 一个region由多个store组成,一个store对应一个CF(列族)
- store包括位于内存中的memstore和位于磁盘的storefile写操作先写入 memstore,当memstore中的数据达到某个阈值,hregionserver会启动 flashcache进程写入storefile,每次写入形成单独的一个storefile
- 当storefile文件的数量增长到一定阈值后,系统会进行合并(minor、 major compaction),在合并过程中会进行版本合并和删除工作 (majar),形成更大的storefile。
- 当一个region所有storefile的大小和超过一定阈值后,会把当前的region 分割为两个,并由hmaster分配到相应的regionserver服务器,实现负载均衡。
- 客户端检索数据,先在memstore找,找不到再找storefile
- HRegion是HBase中分布式存储和负载均衡的最小单元。最小单元就表 示不同的HRegion可以分布在不同的HRegion server上。
- HRegion由一个或者多个Store组成,每个store保存一个columns family。
- 每个Strore又由一个memStore和0至多个StoreFile组成。
2、安装搭建hadoop
2.1 配置说明
本次集群搭建共三台机器,具体说明下:
| 主机名 | IP | 说明 |
| hadoop01 | 192.168.10.101 | DataNode、NodeManager、ResourceManager、NameNode |
| hadoop02 | 192.168.10.102 | DataNode、NodeManager、SecondaryNameNode |
| hadoop03 | 192.168.10.106 | DataNode、NodeManager |
2.2 安装前准备
2.2.1 机器配置说明
|
1
2
3
4
|
$ cat /etc/redhat-releaseCentOS Linux release 7.3.1611 (Core) $ uname -r3.10.0-514.el7.x86_64 |
注:本集群内所有进程均由clsn用户启动;要在集群所有服务器都进行操作。
2.2.2 关闭selinux、防火墙
|
1
2
3
4
5
6
7
8
|
[along@hadoop01 ~]$ sestatus SELinux status: disabled[root@hadoop01 ~]$ iptables -F[along@hadoop01 ~]$ systemctl status firewalld.service ● firewalld.service - firewalld - dynamic firewall daemon Loaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled; vendor preset: enabled) Active: inactive (dead) Docs: man:firewalld(1) |
2.2.3 准备用户
|
1
2
|
$ id alonguid=1000(along) gid=1000(along) groups=1000(along) |
2.2.4 修改hosts文件,域名解析
|
1
2
3
4
5
6
7
|
$ cat /etc/hosts127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4::1 localhost localhost.localdomain localhost6 localhost6.localdomain6192.168.10.101 hadoop01192.168.10.102 hadoop02192.168.10.103 hadoop03 |
2.2.5 同步时间
|
1
2
|
$ yum -y install ntpdate$ sudo ntpdate cn.pool.ntp.org |
2.2.6 ssh互信配置
(1)生成密钥对,一直回车即可
|
1
|
[along@hadoop01 ~]$ ssh-keygen |
(2)保证每台服务器各自都有对方的公钥
|
1
2
3
4
5
6
7
8
9
10
|
---along用户[along@hadoop01 ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub 127.0.0.1[along@hadoop01 ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop01[along@hadoop01 ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop02[along@hadoop01 ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop03---root用户[along@hadoop01 ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub 127.0.0.1[along@hadoop01 ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop01[along@hadoop01 ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop02[along@hadoop01 ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop03 |
注:要在集群所有服务器都进行操作
(3)验证无秘钥认证登录
|
1
2
3
|
[along@hadoop02 ~]$ ssh along@hadoop01[along@hadoop02 ~]$ ssh along@hadoop02[along@hadoop02 ~]$ ssh along@hadoop03 |
2.3 配置jdk
在三台机器上都需要操作
|
1
2
3
4
5
6
7
8
9
10
11
|
[root@hadoop01 ~]# tar -xvf jdk-8u201-linux-x64.tar.gz -C /usr/local[root@hadoop01 ~]# chown along.along -R /usr/local/jdk1.8.0_201/[root@hadoop01 ~]# ln -s /usr/local/jdk1.8.0_201/ /usr/local/jdk[root@hadoop01 ~]# cat /etc/profile.d/jdk.shexport JAVA_HOME=/usr/local/jdkPATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH[root@hadoop01 ~]# source /etc/profile.d/jdk.sh[along@hadoop01 ~]$ java -versionjava version "1.8.0_201"Java(TM) SE Runtime Environment (build 1.8.0_201-b09)Java HotSpot(TM) 64-Bit Server VM (build 25.201-b09, mixed mode) |
2.4 安装hadoop
|
1
2
3
4
|
[root@hadoop01 ~]# wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.2.0/hadoop-3.2.0.tar.gz[root@hadoop01 ~]# tar -xvf hadoop-3.2.0.tar.gz -C /usr/local/[root@hadoop01 ~]# chown along.along -R /usr/local/hadoop-3.2.0/[root@hadoop01 ~]# ln -s /usr/local/hadoop-3.2.0/ /usr/local/hadoop |
3、配置启动hadoop
3.1 hadoop-env.sh 配置hadoop环境变量
|
1
2
3
4
5
|
[along@hadoop01 ~]$ cd /usr/local/hadoop/etc/hadoop/[along@hadoop01 hadoop]$ vim hadoop-env.shexport JAVA_HOME=/usr/local/jdkexport HADOOP_HOME=/usr/local/hadoopexport HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop |
3.2 core-site.xml 配置HDFS
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
[along@hadoop01 hadoop]$ vim core-site.xml<configuration> <!-- 指定HDFS默认(namenode)的通信地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop01:9000</value> </property> <!-- 指定hadoop运行时产生文件的存储路径 --> <property> <name>hadoop.tmp.dir</name> <value>/data/hadoop/tmp</value> </property></configuration>[root@hadoop01 ~]# mkdir /data/hadoop |
3.3 hdfs-site.xml 配置namenode
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
[along@hadoop01 hadoop]$ vim hdfs-site.xml <configuration> <!-- 设置namenode的http通讯地址 --> <property> <name>dfs.namenode.http-address</name> <value>hadoop01:50070</value> </property> <!-- 设置secondarynamenode的http通讯地址 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop02:50090</value> </property> <!-- 设置namenode存放的路径 --> <property> <name>dfs.namenode.name.dir</name> <value>/data/hadoop/name</value> </property> <!-- 设置hdfs副本数量 --> <property> <name>dfs.replication</name> <value>2</value> </property> <!-- 设置datanode存放的路径 --> <property> <name>dfs.datanode.data.dir</name> <value>/data/hadoop/datanode</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property></configuration>[root@hadoop01 ~]# mkdir /data/hadoop/name -p[root@hadoop01 ~]# mkdir /data/hadoop/datanode -p |
3.4 mapred-site.xml 配置框架
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
[along@hadoop01 hadoop]$ vim mapred-site.xml<configuration> <!-- 通知框架MR使用YARN --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.application.classpath</name> <value> /usr/local/hadoop/etc/hadoop, /usr/local/hadoop/share/hadoop/common/*, /usr/local/hadoop/share/hadoop/common/lib/*, /usr/local/hadoop/share/hadoop/hdfs/*, /usr/local/hadoop/share/hadoop/hdfs/lib/*, /usr/local/hadoop/share/hadoop/mapreduce/*, /usr/local/hadoop/share/hadoop/mapreduce/lib/*, /usr/local/hadoop/share/hadoop/yarn/*, /usr/local/hadoop/share/hadoop/yarn/lib/* </value> </property></configuration> |
3.5 yarn-site.xml 配置resourcemanager
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
[along@hadoop01 hadoop]$ vim yarn-site.xml<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop01</value> </property> <property> <description>The http address of the RM web application.</description> <name>yarn.resourcemanager.webapp.address</name> <value>${yarn.resourcemanager.hostname}:8088</value> </property> <property> <description>The address of the applications manager interface in the RM.</description> <name>yarn.resourcemanager.address</name> <value>${yarn.resourcemanager.hostname}:8032</value> </property> <property> <description>The address of the scheduler interface.</description> <name>yarn.resourcemanager.scheduler.address</name> <value>${yarn.resourcemanager.hostname}:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>${yarn.resourcemanager.hostname}:8031</value> </property> <property> <description>The address of the RM admin interface.</description> <name>yarn.resourcemanager.admin.address</name> <value>${yarn.resourcemanager.hostname}:8033</value> </property></configuration> |
3.6 配置masters & slaves
|
1
2
|
[along@hadoop01 hadoop]$ echo \'hadoop02\' >> /usr/local/hadoop/etc/hadoop/masters[along@hadoop01 hadoop]$ echo \'hadoop03 hadoop01\' >> /usr/local/hadoop/etc/hadoop/slaves |
3.7 启动前准备
3.7.1 准备启动脚本
启动脚本文件全部位于 /usr/local/hadoop/sbin 文件夹下:
(1)修改 start-dfs.sh stop-dfs.sh 文件添加:
|
1
2
3
4
5
6
|
[along@hadoop01 ~]$ vim /usr/local/hadoop/sbin/start-dfs.sh [along@hadoop01 ~]$ vim /usr/local/hadoop/sbin/stop-dfs.shHDFS_DATANODE_USER=alongHADOOP_SECURE_DN_USER=hdfsHDFS_NAMENODE_USER=alongHDFS_SECONDARYNAMENODE_USER=along |
(2)修改start-yarn.sh 和 stop-yarn.sh文件添加:
|
1
2
3
4
5
|
[along@hadoop01 ~]$ vim /usr/local/hadoop/sbin/start-yarn.sh [along@hadoop01 ~]$ vim /usr/local/hadoop/sbin/stop-yarn.shYARN_RESOURCEMANAGER_USER=alongHADOOP_SECURE_DN_USER=yarnYARN_NODEMANAGER_USER=along |
3.7.2 授权
|
1
2
|
[root@hadoop01 ~]# chown -R along.along /usr/local/hadoop-3.2.0/[root@hadoop01 ~]# chown -R along.along /data/hadoop/ |
3.7.3 配置hadoop命令环境变量
|
1
2
3
4
|
[root@hadoop01 ~]# vim /etc/profile.d/hadoop.sh [root@hadoop01 ~]# cat /etc/profile.d/hadoop.shexport HADOOP_HOME=/usr/local/hadoopPATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH |