docker 安装 redis
Posted a393060727
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了docker 安装 redis相关的知识,希望对你有一定的参考价值。
搜索镜像
docker search redis
拉取镜像
docker pull redis
docker images | grep redis
增加相应目录
mkdir -p /home/soft/redis/conf
mkdir -p /home/soft/redis/data
下载配置文件
cd /home/soft/redis/conf wget http://download.redis.io/redis-stable/redis.conf vi redis.conf 修改配置文件 bind 127.0.0.1 #注释掉这部分,这是限制redis只能本地访问 protected-mode no #默认yes,开启保护模式,限制为本地访问 daemonize no#默认no,改为yes意为以守护进程方式启动,可后台运行,除非kill进程,改为yes会使配置文件方式启动redis失败 databases 16 #数据库个数(可选), dir ./ #输入本地redis数据库存放文件夹(可选) appendonly yes #redis持久化(可选)默认no requirepass 打开密码注释,设置123456
增加安装脚本
vi redis_docker.sh docker run -d --restart always \\ -p 6379:6379 \\ -v /home/soft/redis/conf:/etc/redis \\ -v /home/soft/redis/data:/data \\ --name myredis redis:latest \\ redis-server /etc/redis/redis.conf --requirepass "admin123456" --appendonly yes
授权启动脚本
chmod 777 redis_docker.sh
创建容器
./redis_docker.sh
验证容器
docker ps | grep redis
使用客户端连接,测试成功
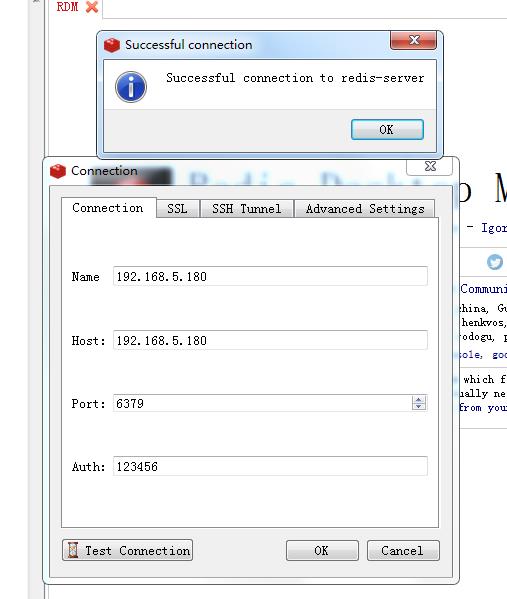
其中修改后的redis.conf配置文件内容如下


# Redis configuration file example. # # Note that in order to read the configuration file, Redis must be # started with the file path as first argument: # # ./redis-server /path/to/redis.conf # Note on units: when memory size is needed, it is possible to specify # it in the usual form of 1k 5GB 4M and so forth: # # 1k => 1000 bytes # 1kb => 1024 bytes # 1m => 1000000 bytes # 1mb => 1024*1024 bytes # 1g => 1000000000 bytes # 1gb => 1024*1024*1024 bytes # # units are case insensitive so 1GB 1Gb 1gB are all the same. ################################## INCLUDES ################################### # Include one or more other config files here. This is useful if you # have a standard template that goes to all Redis servers but also need # to customize a few per-server settings. Include files can include # other files, so use this wisely. # # Notice option "include" won\'t be rewritten by command "CONFIG REWRITE" # from admin or Redis Sentinel. Since Redis always uses the last processed # line as value of a configuration directive, you\'d better put includes # at the beginning of this file to avoid overwriting config change at runtime. # # If instead you are interested in using includes to override configuration # options, it is better to use include as the last line. # # include /path/to/local.conf # include /path/to/other.conf ################################## MODULES ##################################### # Load modules at startup. If the server is not able to load modules # it will abort. It is possible to use multiple loadmodule directives. # # loadmodule /path/to/my_module.so # loadmodule /path/to/other_module.so ################################## NETWORK ##################################### # By default, if no "bind" configuration directive is specified, Redis listens # for connections from all the network interfaces available on the server. # It is possible to listen to just one or multiple selected interfaces using # the "bind" configuration directive, followed by one or more IP addresses. # # Examples: # # bind 192.168.1.100 10.0.0.1 # bind 127.0.0.1 ::1 # # ~~~ WARNING ~~~ If the computer running Redis is directly exposed to the # internet, binding to all the interfaces is dangerous and will expose the # instance to everybody on the internet. So by default we uncomment the # following bind directive, that will force Redis to listen only into # the IPv4 loopback interface address (this means Redis will be able to # accept connections only from clients running into the same computer it # is running). # # IF YOU ARE SURE YOU WANT YOUR INSTANCE TO LISTEN TO ALL THE INTERFACES # JUST COMMENT THE FOLLOWING LINE. # ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ # bind 127.0.0.1 # Protected mode is a layer of security protection, in order to avoid that # Redis instances left open on the internet are accessed and exploited. # # When protected mode is on and if: # # 1) The server is not binding explicitly to a set of addresses using the # "bind" directive. # 2) No password is configured. # # The server only accepts connections from clients connecting from the # IPv4 and IPv6 loopback addresses 127.0.0.1 and ::1, and from Unix domain # sockets. # # By default protected mode is enabled. You should disable it only if # you are sure you want clients from other hosts to connect to Redis # even if no authentication is configured, nor a specific set of interfaces # are explicitly listed using the "bind" directive. protected-mode yes # Accept connections on the specified port, default is 6379 (IANA #815344). # If port 0 is specified Redis will not listen on a TCP socket. port 6379 # TCP listen() backlog. # # In high requests-per-second environments you need an high backlog in order # to avoid slow clients connections issues. Note that the Linux kernel # will silently truncate it to the value of /proc/sys/net/core/somaxconn so # make sure to raise both the value of somaxconn and tcp_max_syn_backlog # in order to get the desired effect. tcp-backlog 511 # Unix socket. # # Specify the path for the Unix socket that will be used to listen for # incoming connections. There is no default, so Redis will not listen # on a unix socket when not specified. # # unixsocket /tmp/redis.sock # unixsocketperm 700 # Close the connection after a client is idle for N seconds (0 to disable) timeout 0 # TCP keepalive. # # If non-zero, use SO_KEEPALIVE to send TCP ACKs to clients in absence # of communication. This is useful for two reasons: # # 1) Detect dead peers. # 2) Take the connection alive from the point of view of network # equipment in the middle. # # On Linux, the specified value (in seconds) is the period used to send ACKs. # Note that to close the connection the double of the time is needed. # On other kernels the period depends on the kernel configuration. # # A reasonable value for this option is 300 seconds, which is the new # Redis default starting with Redis 3.2.1. tcp-keepalive 300 ################################# TLS/SSL ##################################### # By default, TLS/SSL is disabled. To enable it, the "tls-port" configuration # directive can be used to define TLS-listening ports. To enable TLS on the # default port, use: # # port 0 # tls-port 6379 # Configure a X.509 certificate and private key to use for authenticating the # server to connected clients, masters or cluster peers. These files should be # PEM formatted. # # tls-cert-file redis.crt # tls-key-file redis.key # Configure a DH parameters file to enable Diffie-Hellman (DH) key exchange: # # tls-dh-params-file redis.dh # Configure a CA certificate(s) bundle or directory to authenticate TLS/SSL # clients and peers. Redis requires an explicit configuration of at least one # of these, and will not implicitly use the system wide configuration. # # tls-ca-cert-file ca.crt # tls-ca-cert-dir /etc/ssl/certs # By default, clients (including replica servers) on a TLS port are required # to authenticate using valid client side certificates. # # It is possible to disable authentication using this directive. # # tls-auth-clients no # By default, a Redis replica does not attempt to establish a TLS connection # with its master. # # Use the following directive to enable TLS on replication links. # # tls-replication yes # By default, the Redis Cluster bus uses a plain TCP connection. To enable # TLS for the bus protocol, use the following directive: # # tls-cluster yes # Explicitly specify TLS versions to support. Allowed values are case insensitive # and include "TLSv1", "TLSv1.1", "TLSv1.2", "TLSv1.3" (OpenSSL >= 1.1.1) or # any combination. To enable only TLSv1.2 and TLSv1.3, use: # # tls-protocols "TLSv1.2 TLSv1.3" # Configure allowed ciphers. See the ciphers(1ssl) manpage for more information # about the syntax of this string. # # Note: this configuration applies only to <= TLSv1.2. # # tls-ciphers DEFAULT:!MEDIUM # Configure allowed TLSv1.3 ciphersuites. See the ciphers(1ssl) manpage for more # information about the syntax of this string, and specifically for TLSv1.3 # ciphersuites. # # tls-ciphersuites TLS_CHACHA20_POLY1305_SHA256 # When choosing a cipher, use the server\'s preference instead of the client # preference. By default, the server follows the client\'s preference. # # tls-prefer-server-ciphers yes # By default, TLS session caching is enabled to allow faster and less expensive # reconnections by clients that support it. Use the following directive to disable # caching. # # tls-session-caching no # Change the default number of TLS sessions cached. A zero value sets the cache # to unlimited size. The default size is 20480. # # tls-session-cache-size 5000 # Change the default timeout of cached TLS sessions. The default timeout is 300 # seconds. # # tls-session-cache-timeout 60 ################################# GENERAL ##################################### # By default Redis does not run as a daemon. Use \'yes\' if you need it. # Note that Redis will write a pid file in /var/run/redis.pid when daemonized. daemonize no # If you run Redis from upstart or systemd, Redis can interact with your # supervision tree. Options: # supervised no - no supervision interaction # supervised upstart - signal upstart by putting Redis into SIGSTOP mode # supervised systemd - signal systemd by writing READY=1 to $NOTIFY_SOCKET # supervised auto - detect upstart or systemd method based on # UPSTART_JOB or NOTIFY_SOCKET environment variables # Note: these supervision methods only signal "process is ready." # They do not enable continuous liveness pings back to your supervisor. supervised no # If a pid file is specified, Redis writes it where specified at startup # and removes it at exit. # # When the server runs non daemonized, no pid file is created if none is # specified in the configuration. When the server is daemonized, the pid file # is used even if not specified, defaulting to "/var/run/redis.pid". # # Creating a pid file is best effort: if Redis is not able to create it # nothing bad happens, the server will start and run normally. pidfile /var/run/redis_6379.pid # Specify the server verbosity level. # This can be one of: # debug (a lot of information, useful for development/testing) # verbose (many rarely useful info, but not a mess like the debug level) # notice (moderately verbose, what you want in production probably) # warning (only very important / critical messages are logged) loglevel notice # Specify the log file name. Also the empty string can be used to force # Redis to log on the standard output. Note that if you use standard # output for logging but daemonize, logs will be sent to /dev/null logfile "" # To enable logging to the system logger, just set \'syslog-enabled\' to yes, # and optionally update the other syslog parameters to suit your needs. # syslog-enabled no # Specify the syslog identity. # syslog-ident redis # Specify the syslog facility. Must be USER or between LOCAL0-LOCAL7. # syslog-facility local0 # Set the number of databases. The default database is DB 0, you can select # a different one on a per-connection basis using SELECT <dbid> where # dbid is a number between 0 and \'databases\'-1 databases 16 # By default Redis shows an ASCII art logo only when started to log to the # standard output and if the standard output is a TTY. Basically this means # that normally a logo is displayed only in interactive sessions. # # However it is possible to force the pre-4.0 behavior and always show a # ASCII art logo in startup logs by setting the following option to yes. always-show-logo yes ################################ SNAPSHOTTING ################################ # # Save the DB on disk: # # save <seconds> <changes> # # Will save the DB if both the given number of seconds and the given # number of write operations against the DB occurred. # # In the example below the behaviour will be to save: # after 900 sec (15 min) if at least 1 key changed # after 300 sec (5 min) if at least 10 keys changed # after 60 sec if at least 10000 keys changed # # Note: you can disable saving completely by commenting out all "save" lines. # # It is also possible to remove all the previously configured save # points by adding a save directive with a single empty string argument # like in the following example: # # save "" save 900 1 save 300 10 save 60 10000 # By default Redis will stop accepting writes if RDB snapshots are enabled # (at least one save point) and the latest background save failed. # This will make the user aware (in a hard way) that data is not persisting # on disk properly, otherwise chances are that no one will notice and some # disaster will happen. # # If the background saving process will start working again Redis will # automatically allow writes again. # # However if you have setup your proper monitoring of the Redis server # and persistence, you may want to disable this feature so that Redis will # continue to work as usual even if there are problems with disk, # permissions, and so forth. stop-writes-on-bgsave-error yes # Compress string objects using LZF when dump .rdb databases? # For default that\'s set to \'yes\' as it\'s almost always a win. # If you want to save some CPU in the saving child set it to \'no\' but # the dataset will likely be bigger if you have compressible values or keys. rdbcompression yes # Since version 5 of RDB a CRC64 checksum is placed at the end of the file. # This makes the format more resistant to corruption but there is a performance # hit to pay (around 10%) when saving and loading RDB files, so you can disable it # for maximum performances. # # RDB files created with checksum disabled have a checksum of zero that will # tell the loading code to skip the check. rdbchecksum yes # The filename where to dump the DB dbfilename dump.rdb # Remove RDB files used by replication in instances without persistence # enabled. By default this option is disabled, however there are environments # where for regulations or other security concerns, RDB files persisted on # disk by masters in order to feed replicas, or stored on disk by replicas # in order to load them for the initial synchronization, should be deleted # ASAP. Note that this option ONLY WORKS in instances that have both AOF # and RDB persistence disabled, otherwise is completely ignored. # # An alternative (and sometimes better) way to obtain the same effect is # to use diskless replication on both master and replicas instances. However # in the case of replicas, diskless is not always an option. rdb-del-sync-files no # The working directory. # # The DB will be written inside this directory, with the filename specified # above using the \'dbfilename\' configuration directive. # # The Append Only File will also be created inside this directory. # # Note that you must specify a directory here, not a file name. dir ./ ################################# REPLICATION ################################# # Master-Replica replication. Use replicaof to make a Redis instance a copy of # another Redis server. A few things to understand ASAP about Redis replication. # # +------------------+ +---------------+ # | Master | ---> | Replica | # | (receive writes) | | (exact copy) | # +------------------+ +---------------+ # # 1) Redis replication is asynchronous, but you can configure a master to # stop accepting writes if it appears to be not connected with at least # a given number of replicas. # 2) Redis replicas are able to perform a partial resynchronization with the # master if the replication link is lost for a relatively small amount of # time. You may want to configure the replication backlog size (see the next # sections of this file) with a sensible value depending on your needs. # 3) Replication is automatic and does not need user intervention. After a # network partition replicas automatically try to reconnect to masters # and resynchronize with them. # # replicaof <masterip> <masterport> # If the master is password protected (using the "requirepass" configuration # directive below) it is possible to tell the replica to authenticate before # starting the replication synchronization process, otherwise the master will # refuse the replica request. # # masterauth <master-password> # # However this is not enough if you are using Redis ACLs (for Redis version # 6 or greater), and the default user is not capable of running the PSYNC # command and/or other commands needed for replication. In this case it\'s # better to configure a special user to use with replication, and specify the # masteruser configuration as such: # # masteruser <username> # # When masteruser is specified, the replica will authenticate against its # master using the new AUTH form: AUTH <username> <password>. # When a replica loses its connection with the master, or when the replication # is still in progress, the replica can act in two different ways: # # 1) if replica-serve-stale-data is set to \'yes\' (the default) the replica will # still reply to client requests, possibly with out of date data, or the # data set may just be empty if this is the first synchronization. # # 2) if replica-serve-stale-data is set to \'no\' the replica will reply with # an error "SYNC with master in progress" to all the kind of commands # but to INFO, replicaOF, AUTH, PING, SHUTDOWN, REPLCONF, ROLE, CONFIG, # SUBSCRIBE, UNSUBSCRIBE, PSUBSCRIBE, PUNSUBSCRIBE, PUBLISH, PUBSUB, # COMMAND, POST, HOST: and LATENCY. # replica-serve-stale-data yes # You can configure a replica instance to accept writes or not. Writing against # a replica instance may be useful to store some ephemeral data (because data # written on a replica will be easily deleted after resync with the master) but # may also cause problems if clients are writing to it because of a # misconfiguration. # # Since Redis 2.6 by default replicas are read-only. # # Note: read only replicas are not designed to be exposed to untrusted clients # on the internet. It\'s just a protection layer against misuse of the instance. # Still a read only replica exports by default all the administrative commands # such as CONFIG, DEBUG, and so forth. To a limited extent you can improve # security of read only replicas using \'rename-command\' to shadow all the # administrative / dangerous commands. replica-read-only yes # Replication SYNC strategy: disk or socket. # # New replicas and reconnecting replicas that are not able to continue the # replication process just receiving differences, need to do what is called a # "full synchronization". An RDB file is transmitted from the master to the # replicas. # # The transmission can happen in two different ways: # # 1) Disk-backed: The Redis master creates a new process that writes the RDB # file on disk. Later the file is transferred by the parent # process to the replicas incrementally. # 2) Diskless: The Redis master creates a new process that directly writes the # RDB file to replica sockets, without touching the disk at all. # # With disk-backed replication, while the RDB file is generated, more replicas # can be queued and served with the RDB file as soon as the current child # producing the RDB file finishes its work. With diskless replication instead # once the transfer starts, new replicas arriving will be queued and a new # transfer will start when the current one terminates. # # When diskless replication is used, the master waits a configurable amount of # time (in seconds) before starting the transfer in the hope that multiple # replicas will arrive and the transfer can be parallelized. # # With slow disks and fast (large bandwidth) networks, diskless replication # works better. repl-diskless-sync no # When diskless replication is enabled, it is possible to configure the delay # the server waits in order to spawn the child that transfers the RDB via socket # to the replicas. # # This is important since once the transfer starts, it is not possible to serve # new replicas arriving, that will be queued for the next RDB transfer, so the # server waits a delay in order to let more replicas arrive. # # The delay is specified in seconds, and by default is 5 seconds. To disable # it entirely just set it to 0 seconds and the transfer will start ASAP. repl-diskless-sync-delay 5 # ----------------------------------------------------------------------------- # WARNING: RDB diskless load is experimental. Since in this setup the replica # does not immediately store an RDB on disk, it may cause data loss during # failovers. RDB diskless load + Redis modules not handling I/O reads may also # cause Redis to abort in case of I/O errors during the initial synchronization # stage with the master. Use only if your do what you are doing. # ----------------------------------------------------------------------------- # # Replica can load the RDB it reads from the replication link directly from the # socket, or store the RDB to a file and read that file after it was completely # recived from the master. # # In many cases the disk is slower than the network, and storing and loading # the RDB file may increase replication time (and even increase the master\'s # Copy on Write memory and salve buffers). # However, parsing the RDB file directly from the socket may mean that we have # to flush the contents of the current database before the full rdb was # received. For this reason we have the following options: # # "disabled" - Don\'t use diskless load (store the rdb file to the disk first) # "on-empty-db" - Use diskless load only when it is completely safe. # "swapdb" - Keep a copy of the current db contents in RAM while parsing # the data directly from the socket. note that this requires # sufficient memory, if you don\'t have it, you risk an OOM kill. repl-diskless-load disabled # Replicas send PINGs to server in a predefined interval. It\'s possible to # change this interval with the repl_ping_replica_period option. The default # value is 10 seconds. # # repl-ping-replica-period 10 # The following option sets the replication timeout for: # # 1) Bulk transfer I/O during SYNC, from the point of view of replica. # 2) Master timeout from the point of view of replicas (data, pings). # 3) Replica timeout from the point of view of masters (REPLCONF ACK pings). # # It is important to make sure that this value is greater than the value # specified for repl-ping-replica-period otherwise a timeout will be detected # every time there is low traffic between the master and the replica. # # repl-timeout 60 # Disable TCP_NODELAY on the replica socket after SYNC? # # If you select "yes" Redis will use a smaller number of TCP packets and # less bandwidth to send data to replicas. But this can add a delay for # the data to appear on the replica side, up to 40 milliseconds with # Linux kernels using a default configuration. # # If you select "no" the delay for data to appear on the replica side will # be reduced but more bandwidth will be used for replication. # # By default we optimize for low latency, but in very high traffic conditions # or when the master and replicas are many hops away, turning this to "yes" may # be a good idea. repl-disable-tcp-nodelay no # Set the replication backlog size. The backlog is a buffer that accumulates # replica data when replicas are disconnected for some time, so that when a # replica wants to reconnect again, often a full resync is not needed, but a # partial resync is enough, just passing the portion of data the replica # missed while以上是关于docker 安装 redis的主要内容,如果未能解决你的问题,请参考以下文章