正则表达式介绍
前两章中的过滤例子允许用匹配、比较和通配操作符寻找数据。对
于基本的过滤(或者甚至是某些不那么基本的过滤),这样就足够了。但
随着过滤条件的复杂性的增加, WHERE 子句本身的复杂性也有必要增加。
这也就是正则表达式变得有用的地方。正则表达式是用来匹配文本
的特殊的串(字符集合)。如果你想从一个文本文件中提取电话号码,可
以使用正则表达式。如果你需要查找名字中间有数字的所有文件,可以
使用一个正则表达式。如果你想在一个文本块中找到所有重复的单词,
可以使用一个正则表达式。如果你想替换一个页面中的所有URL为这些
URL的实际html链接,也可以使用一个正则表达式(对于最后这个例子,
或者是两个正则表达式)。
所有种类的程序设计语言、文本编辑器、操作系统等都支持正则表
达式。有见识的程序员和网络管理员已经关注作为他们技术工具重要内
容的正则表达式很长时间了。
正则表达式用正则表达式语言来建立,正则表达式语言是用来完成
刚讨论的所有工作以及更多工作的一种特殊语言。与任意语言一样,正
则表达式具有你必须学习的特殊的语法和指令
使用mysql正则表达式
那么,正则表达式与MySQL有何关系?已经说过,正则表达式的作
用是匹配文本,将一个模式(正则表达式)与一个文本串进行比较。MySQL
用 WHERE 子句对正则表达式提供了初步的支持,允许你指定正则表达式,
过滤 SELECT 检索出的数据
仅为正则表达式语言的一个子集 如果你熟悉正则表达式,需
要注意:MySQL仅支持多数正则表达式实现的一个很小的子
集。本章介绍MySQL支持的大多数内容。
基本字符匹配
我们从一个非常简单的例子开始。下面的语句检索列 prod_name 包含
文本 1000 的所有行

除关键字 LIKE 被 REGEXP 替代外,这条语句看上去非常像使用
LIKE 的语句(第8章)。它告诉MySQL: REGEXP 后所跟的东西作
为正则表达式(与文字正文 1000 匹配的一个正则表达式)处理
为什么要费力地使用正则表达式?在刚才的例子中,正则表达式确
实没有带来太多好处(可能还会降低性能),不过,请考虑下面的例子

这里使用了正则表达式 .000 。 . 是正则表达式语言中一个特殊
的字符。它表示匹配任意一个字符,因此, 1000 和 2000 都匹配
且返回。
当然,这个特殊的例子也可以用 LIKE 和通配符来完成
LIKE 匹配整个列。如果被匹配的文本在列值
中出现, LIKE 将不会找到它,相应的行也不被返回(除非使用
通配符)。而 REGEXP 在列值内进行匹配,如果被匹配的文本在
列值中出现, REGEXP 将会找到它,相应的行将被返回。这是一
个非常重要的差别。的作用)?答案是肯定的,使用 ^ 和 $ 定位符(anchor)即可,
本章后面介绍。
匹配不区分大小写 MySQL中的正则表达式匹配(自版本
3.23.4后)不区分大小写(即,大写和小写都匹配)。为区分大
小写,可使用 BINARY 关键字,如 WHERE prod_name REGEXP
BINARY \'JetPack .000\'
匹配几个字符之一
匹配任何单一字符。但是,如果你只想匹配特定的字符,怎么办?
可通过指定一组用 [ 和 ] 括起来的字符来完成,如下所示:

这里,使用了正则表达式 [123] Ton 。 [123] 定义一组字符,它
的意思是匹配 1 或 2 或 3 ,因此, 1 ton 和 2 ton 都匹配且返回(没
有 3 ton )。
正如所见, [] 是另一种形式的 OR 语句。事实上,正则表达式 [123]Ton
为 [1|2|3]Ton 的缩写,也可以使用后者。但是,需要用 [] 来定义 OR 语句
查找什么。为更好地理解这一点,请看下面的例子:


这并不是期望的输出。两个要求的行被检索出来,但还检索出
了另外3行。之所以这样是由于MySQL假定你的意思是 \'1\' 或
\'2\' 或 \'3 ton\' 。除非把字符 | 括在一个集合中,否则它将应用于整个串。
字符集合也可以被否定,即,它们将匹配除指定字符外的任何东西。
为否定一个字符集,在集合的开始处放置一个 ^ 即可。因此,尽管 [123]
匹配字符 1 、 2 或 3 ,但 [^123] 却匹配除这些字符外的任何东西
匹配范围
集合可用来定义要匹配的一个或多个字符。例如,下面的集合将匹
配数字0到9:


这里使用正则表达式 [1-5] Ton 。 [1-5] 定义了一个范围,这个
表达式意思是匹配 1 到 5 ,因此返回3个匹配行。由于 5 ton 匹配,
所以返回 .5 ton 。
匹配特殊字符
正则表达式语言由具有特定含义的特殊字符构成。我们已经看到 . 、 [] 、
| 和 - 等,还有其他一些字符。请问,如果你需要匹配这些字符,应该怎么
办呢?例如,如果要找出包含 . 字符的值,怎样搜索?请看下面的例子
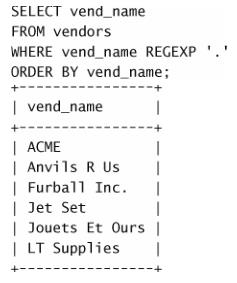
这并不是期望的输出, . 匹配任意字符,因此每个行都被检索出
来。为了匹配特殊字符,必须用 \\ 为前导。 \\- 表示查找 - , \\. 表示查找 .

这种处理
就是所谓的转义(escaping),正则表达式内具有特殊意义的所
有字符都必须以这种方式转义。这包括 . 、 | 、 [] 以及迄今为止使用过的
其他特殊字符。
\\ 也用来引用元字符(具有特殊含义的字符),如表9-1所列。

匹配 \\ 为了匹配反斜杠( \\ )字符本身,需要使用 \\\\ 。
\\ 或 \\? 多数正则表达式实现使用单个反斜杠转义特殊字符,
以便能使用这些字符本身。但MySQL要求两个反斜杠(MySQL
自己解释一个,正则表达式库解释另一个)。
匹配字符类
存在找出你自己经常使用的数字、所有字母字符或所有数字字母字
符等的匹配。为更方便工作,可以使用预定义的字符集,称为字符类
(character class)。表9-2列出字符类以及它们的含义

匹配多个实例
目前为止使用的所有正则表达式都试图匹配单次出现。如果存在一
个匹配,该行被检索出来,如果不存在,检索不出任何行。但有时需要
对匹配的数目进行更强的控制。例如,你可能需要寻找所有的数,不管
数中包含多少数字,或者你可能想寻找一个单词并且还能够适应一个尾
随的 s (如果存在),等等
这可以用表9-3列出的正则表达式重复元字符来完成

定位符
目前为止的所有例子都是匹配一个串中任意位置的文本。为了匹配特定位置的文本,需要使用表9-4列出的定位符

例如,如果你想找出以一个数(包括以小数点开始的数)开始的所
有产品,怎么办?简单搜索 [0-9\\.] (或 [[:digit:]\\.] )不行,因为
它将在文本内任意位置查找匹配。解决办法是使用 ^ 定位符,如下所示
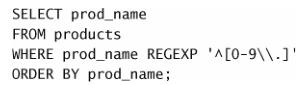
^ 匹配串的开始。因此, [1] 只在 . 或任意数字为串中第
一个字符时才匹配它们。
^ 的双重用途 ^ 有两种用法。在集合中(用 [ 和 ] 定义),用它
来否定该集合,否则,用来指串的开始处
使 REGEXP 起类似 LIKE 的作用 本章前面说过, LIKE 和 REGEXP
的不同在于, LIKE 匹配整个串而 REGEXP 匹配子串。利用定位
符,通过用 ^ 开始每个表达式,用 $ 结束每个表达式,可以使
REGEXP 的作用与 LIKE 一样

本章介绍了正则表达式的基础知识,学习了如何在MySQL的 SELECT
语句中通过 REGEXP 关键字使用它们
0-9\\. ↩︎