MySQL8.0新特性
Posted hch的随笔 成功的秘诀在于恒心—迪斯雷利
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL8.0新特性相关的知识,希望对你有一定的参考价值。
Server层,选项持久化
mysql> show variables like \'%max_connections%\'; +------------------------+-------+ | Variable_name | Value | +------------------------+-------+ | max_connections | 512 | | mysqlx_max_connections | 100 | +------------------------+-------+ 2 rows in set (0.00 sec) mysql> set persist max_connections=8000; Query OK, 0 rows affected (0.00 sec) mysql> show variables like \'%max_connections%\'; +------------------------+-------+ | Variable_name | Value | +------------------------+-------+ | max_connections | 8000 | | mysqlx_max_connections | 100 | +------------------------+-------+ 2 rows in set (0.00 sec) [root@mydb1 ~]# cat /app/mysqldata/3306/data/mysqld-auto.cnf { "Version" : 1 , "mysql_server" : { "max_connections" : { "Value" : "8000" , "Metadata" : { "Timestamp" : 1570677819639469 , "User" : "dba_user" , "Host" : "localhost" } } } } [root@mydb1 ~]# cat /app/mysqldata/3306/my.cnf | grep max_connections max_connections = 512 查看配置文件,仍然是之前的配置max_connections = 512 mysql> restart; mysql> show variables like \'%max_connections%\'; +------------------------+-------+ | Variable_name | Value | +------------------------+-------+ | max_connections | 8000 | | mysqlx_max_connections | 100 | +------------------------+-------+ 2 rows in set (0.01 sec)
set persist更改运行时变量值,将变量设置写入mysqld-auto.cnf数据目录中指定的选项文件 。数据库启动时,会首先读取其它配置文件my.cnf,最后才读取mysqld-auto.cnf文件。
注意,其只是清空mysqld-auto.cnf和performance_schema.persisted_variables中的内容,对于已经修改了的变量的值,不会产生任何影响。
但是对于read only 的参数,修改参数后需要重启才能生效
修改read only的变量需要额外的特权:
SYSTEM_VARIABLES_ADMIN
PERSIST_RO_VARIABLES_ADMIN
mysql> show variables like \'innodb_log_file_size\'; +----------------------+------------+ | Variable_name | Value | +----------------------+------------+ | innodb_log_file_size | 1147483648 | +----------------------+------------+ 1 row in set (0.00 sec) mysql> set persist innodb_log_file_size=2147483648; ERROR 1238 (HY000): Variable \'innodb_log_file_size\' is a read only variable mysql> set persist_only innodb_log_file_size=2147483648; Query OK, 0 rows affected (0.00 sec) mysql> restart; Query OK, 0 rows affected (0.00 sec) mysql> show variables like \'innodb_log_file_size\'; +----------------------+------------+ | Variable_name | Value | +----------------------+------------+ | innodb_log_file_size | 2147483648 | +----------------------+------------+ 1 row in set (0.00 sec) [root@mydb1 ~]# cat /app/mysqldata/3306/data/mysqld-auto.cnf { "Version" : 1 , "mysql_server" : { "max_connections" : { "Value" : "8000" , "Metadata" : { "Timestamp" : 1570677819639469 , "User" : "dba_user" , "Host" : "localhost" } } , "mysql_server_static_options" : { "innodb_log_file_size" : { "Value" : "2147483648" , "Metadata" : { "Timestamp" : 1570679652100887 , "User" : "dba_user" , "Host" : "localhost" } } } } } mysql> select * from performance_schema.variables_info where variable_source like \'PERSISTED\'\\G *************************** 1. row *************************** VARIABLE_NAME: innodb_log_file_size VARIABLE_SOURCE: PERSISTED VARIABLE_PATH: /app/mysqldata/3306/data/mysqld-auto.cnf MIN_VALUE: 4194304 MAX_VALUE: 18446744073709551615 SET_TIME: 2019-10-10 11:54:12.100887 SET_USER: dba_user SET_HOST: localhost *************************** 2. row *************************** VARIABLE_NAME: max_connections VARIABLE_SOURCE: PERSISTED VARIABLE_PATH: /app/mysqldata/3306/data/mysqld-auto.cnf MIN_VALUE: 1 MAX_VALUE: 100000 SET_TIME: 2019-10-10 11:23:39.639469 SET_USER: dba_user SET_HOST: localhost 2 rows in set (0.01 sec)
数据字典
(1)新版本之前的数据字典
数据字典是数据库重要的组成部分之一,那么什么是数据字典?数据字典包含哪些内容呢?数据字典是对数据库中的数据、库对象、表对象等的元信息的集合。在MySQL中,数据字典信息内容就包括表结构、数据库名或表名、字段的数据类型、视图、索引、表字段信息、存储过程、触发器等内容。MySQL INFORMATION_SCHEMA库提供了对数据局元数据、统计信息、以及有关MySQL server的访问信息(例如:数据库名或表名,字段的数据类型和访问权限等)。该库中保存的信息也可以称为MySQL的数据字典。
在MySQL8.0之前,MySQL的数据字典信息,并没有全部存放在系统数据库表中,部分数据库数据字典信息存放于文件中,其余的数据字典信息存放于数据字典库中(INFORMATION_SCHEMA,mysql,sys)。例如表结构信息存放在.frm文件中,数据库表字段信息存放于INFORMATION_SCHEMA下的COLUMNS表中。早期,5.6版本之前,MyISAM是MySQL的默认存储引擎,而作为MyISAM存储引擎,它是没有数据字典的。只有表结构信息记录在.frm文件中。MySQL5.6版本之后,将InnoDB存储引擎作为默认的存储引擎。在InnoDB存储引擎中,添加了一些数据字典文件用于存放数据字典元信息,例如:.opt文件,记录了每个库的一些基本信息,包括库的字符集等信息,.TRN,.TRG文件用于存放触发器的信息内容。
(2)新版本数据字典的改进
最新的MySQL 8.0 发布之后,对数据库数据字典方面做了较大的改进。
首先是,将所有原先存放于数据字典文件中的信息,全部存放到数据库系统表中,即将之前版本的.frm,.opt,.par,.TRN,.TRG,.isl文件都移除了,不再通过文件的方式存储数据字典信息。
其次是对INFORMATION_SCHEM,mysql,sys系统库中的存储引擎做了改进,原先使用MyISAM存储引擎的数据字典表都改为使用InnoDB存储引擎存放。从不支持事务的MyISAM存储引擎转变到支持事务的InnoDB存储引擎,为原子DDL的实现,提供了可能性。
新数据字典带来的影响
(1)INFORMATION_SCHEMA性能提升
8.0中对数据字典进行改进之后,很大程度上提高了对INFORMATIONS_SCHEMA的查询性能,通过可以通过查表快速的获得想要查询的数据,原因是:
数据库在查询INFORMATION_SCHEMA的表时,不再一定需要创建一张临时表,可以直接查询数据字典表。在之前版本中,数据字典信息不一定是存放于表中,所以在获取数据字典信息时候,不仅仅是查表操作。例如读取数据库表结构信息,底层其实是读取.frm文件来获得,是一个文件打开读取的操作。而在新版本中,数据字典信息都可以通过直接查表的方式获取,替代那些获取信息慢的方式。
对存储引擎的改进之后,在查询INFORMATIONS_SCHEMA表时,如果表上有索引,优化器会合理的利用索引。
对于INFORMATION_SCHEMA下的STATISTICS表和TABLES表中的信息,8.0中通过缓存的方式,以提高查询的性能。可以通过设置information_schema_stats_expiry参数设置缓存数据的过期时间,默认是86400秒。查询这两张表的数据的时候,首先是到缓存中进行查询,缓存中没有缓存数据,或者缓存数据过期了,查询会从存储引擎中获取最新的数据。如果需要获取最新的数据,可以通过设置information_schema_stats_expiry参数为0或者ANALYZE TABLE操作。
(2)原子DDL
MySQL8.0开始支持原子DDL操作,一个原子DDL操作,具体的操作内容包括:数据字典更新,存储引擎层的操作,在binlog中记录DDL操作。并且这些操作都是原子性的,表示中间过程出现错误的时候,是可以完整回退的。这在之前版本的DDL操作中是不支持的。之前数据库版本中一直没有支持原子DDL的特性,是有原因的,因为在早期的数据库版本中,数据库元信息存放于元信息文件中、非事务性表中以及特定存储引擎的数据字典中。这些都无法保证DDL操作内容在一个事务当中,无法保证原子性。具体的原子DDL,后续会有专门的文章。
(3)innodb_read_only对所有存储引擎生效
在8.0之前版本中,innodb_read_only参数可以阻止对InnoDB存储引擎表的create和drop等更新操作。但是在MySQL8.0中,开启innodb_read_only参数阻止了所有存储引擎的这些操作。create或者drop表的操作都需要更新数据字典表,8.0中这个数据字典表都改为了InnoDB存储引擎,所以对于数据字典表的更新会失败,从而导致各存储引擎create和drop表失败。同样的像ANALYZE TABLE和ALTER TABLE tbl_name ENGINE=engine_name这种操作也会失败,因为这些操作都要去更新数据字典表。
(4)mysqldump mysqlpump导出的内容影响
MySQL8.0之后,在使用mysqldump和mysqlpump导出数据时候,与之前有了一些不同,主要是以下几点:
之前版本的mysqldump和mysqlpump可以导出mysql系统库中的所有表的内容,8.0之后,只能导出mysql系统库中没有数据的数据字典表。
之前版本当使用 --all-databases 参数导出数据的时候,不加 --routines和 --events选项也可以导出触发器、存储过程等信息,因为这些信息都存放于proc和event表中,导出所有表即可导出这些信息。但是在8.0中,proc表和event表都不再使用,并且定义触发器、存储过程的数据字典表不会被导出,所以在8.0中使用mysqldump、mysqlpump导出数据的时候,如果需要导出触发器、存储过程等内容,一定需要加上 --routines和 --events选项。
之前版本中 --routines选项导出的时候,备份账户需要有proc表的SELECT权限,在8.0中需要对所有表的SELECT权限
之前版本中,导出触发器、存储过程可以同时导出触发器、存储过程的创建和修改的时间戳,8.0中不再支持。
(5)新数据字典的局限性
MySQL8.0数据字典的改进有很多方便的特性,例如带来了原子DDL,提升了INFORMATION_SCHEMA的查询性能等,但是它并不是完美的,新版数据字典还是存在一些局限性:
通过手动mkdir的方式在数据目录下创建库目录,这种方式是不会被数据库所识别到。DDL操作会花费更长的时间,因为之前的DDL操作是直接对.frm文件进行更改操作,只要写一个文件,现在是需要更新数据字典表,代表着需要将数据写到存储引擎、read log、undo log中
auto-inc持久化
自增主键没有持久化是个比较早的bug,历史悠久且臭名昭著。
首先,直观的重现下。
mysql> create table t1(id int auto_increment primary key); Query OK, 0 rows affected (0.01 sec) mysql> insert into t1 values(null),(null),(null); Query OK, 3 rows affected (0.01 sec) Records: 3 Duplicates: 0 Warnings: 0 mysql> select * from t1; +----+ | id | +----+ | 1 | | 2 | | 3 | +----+ rows in set (0.00 sec) mysql> delete from t1 where id=3; Query OK, 1 row affected (0.36 sec) mysql> insert into t1 values(null); Query OK, 1 row affected (0.35 sec) mysql> select * from t1; +----+ | id | +----+ | 1 | | 2 | | 4 | +----+ rows in set (0.01 sec)
虽然id为3的记录删除了,但再次插入null值时,并没有重用被删除的3,而是分配了4。
删除id为4的记录,重启数据库,重新插入一个null值。
mysql> delete from t1 where id=4; # service mysqld restart mysql> insert into t1 values(null); Query OK, 1 row affected (0.00 sec) mysql> select * from t1; +----+ | id | +----+ | 1 | | 2 | | 3 | +----+ rows in set (0.00 sec)
可以看到,新插入的null值分配的是3,按照重启前的操作逻辑,此处应该分配5啊。
这就是自增主键没有持久化的bug。究其原因,在于自增主键的分配,是由InnoDB数据字典内部一个计数器来决定的,而该计数器只在内存中维护,并不会持久化到磁盘中。当数据库重启时,该计数器会通过下面这种方式初始化。
SELECT MAX(ai_col) FROM table_name FOR UPDATE;
MySQL 8.0的解决思路
将自增主键的计数器持久化到redo log中。每次计数器发生改变,都会将其写入到redo log中。如果数据库发生重启,InnoDB会根据redo log中的计数器信息来初始化其内存值。为了尽量减小对系统性能的影响,计数器写入到redo log中,并不会马上刷新。
窗口函数、通用表达式
对于窗口函数,比如row_number(),rank(),dense_rank(),NTILE(),PERCENT_RANK()等等,在MSSQL和Oracle以及PostgreSQL,使用的语法和表达的逻辑,基本上完全一致。 在MySQL 8.0之后就放心的用吧。
测试case,简单模拟一个订单表,字段分别是订单号,用户编号,金额,创建时间
create table order_info ( order_id int primary key, user_no varchar(10), amount int, create_date datetime ); insert into order_info values (1,\'u0001\',100,\'2018-1-1\'); insert into order_info values (2,\'u0001\',300,\'2018-1-2\'); insert into order_info values (3,\'u0001\',300,\'2018-1-2\'); insert into order_info values (4,\'u0001\',800,\'2018-1-10\'); insert into order_info values (5,\'u0001\',900,\'2018-1-20\'); insert into order_info values (6,\'u0002\',500,\'2018-1-5\'); insert into order_info values (7,\'u0002\',600,\'2018-1-6\'); insert into order_info values (8,\'u0002\',300,\'2018-1-10\'); insert into order_info values (9,\'u0002\',800,\'2018-1-16\'); insert into order_info values (10,\'u0002\',800,\'2018-1-22\');
采用新的窗口函数的方法,就是使用row_number() over (partition by user_no order by create_date desc) as row_num 给原始记录编一个号,然后取第一个编号的数据,自然就是“用户的最新的一条订单”,实现逻辑上清晰了很多,代码也简洁,可读了很多。
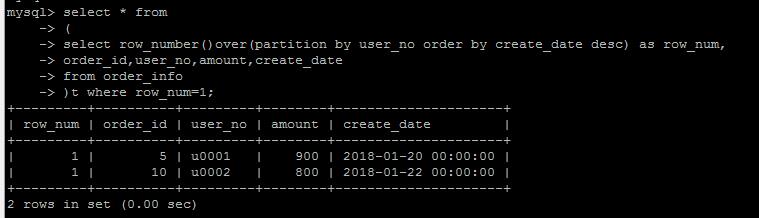
需要注意的是,MySQL中的使用窗口函数的时候,是不允许使用*的,必须显式指定每一个字段。
row_number()
(分组)排序编号,正如上面的例子, row_number()over(partition by user_no order by create_date desc) as row_num,按照用户分组,按照create_date排序,对已有数据生成一个编号。
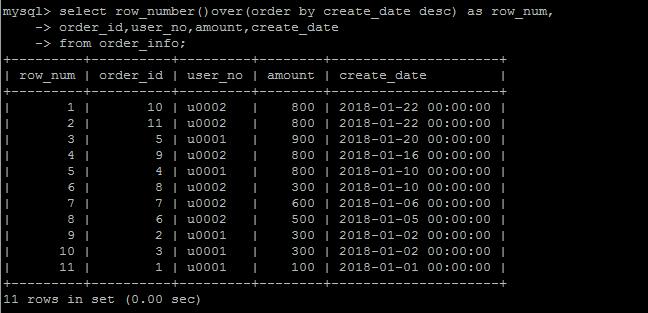
当然也可以不分组,对整体进行排序。任何一个窗口函数,都可以分组统计或者不分组统计(也即可以不要partition by ***都可以,看你的需求了)
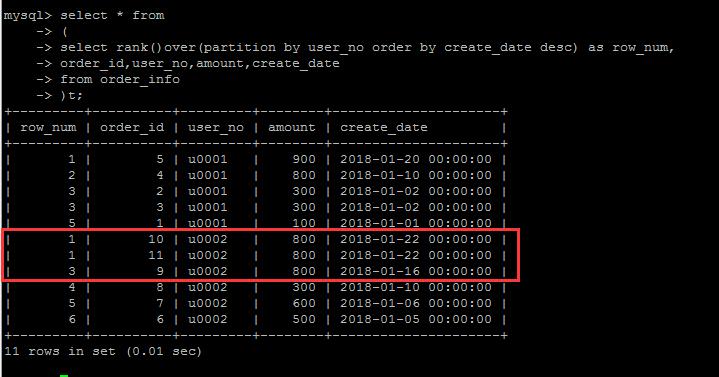
rank()
类似于 row_number(),也是排序功能,但是rank()有什么不一样?新的事物的出现必然是为了解决潜在的问题。
如果再往测试表中写入一条数据:insert into order_info values (11,\'u0002\',800,\'2018-1-22\');
对于测试表中的U002用户来说,有两条create_date完全一样的数据(假设有这样的数据),那么在row_number()编号的时候,这两条数据却被编了两个不同的号
理论上讲,这两条的数据的排名是并列最新的。因此rank()就是为了解决这个问题的,也即:排序条件一样的情况下,其编号也一样。
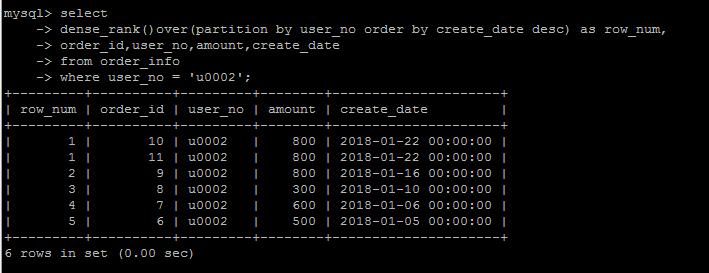
dense_rank()
dense_rank()的出现是为了解决rank()编号存在的问题的,
rank()编号的时候存在跳号的问题,如果有两个并列第1,那么下一个名次的编号就是3,结果就是没有编号为2的数据。
如果不想跳号,可以使用dense_rank()替代。
avg,sum等聚合函数在窗口函数中的的增强
可以在聚合函数中使用窗口功能,比如sum(amount)over(partition by user_no order by create_date) as sum_amont,达到一个累积计算sum的功能
这种需求在没有窗口函数的情况下,用纯sql写起来,也够蛋疼的了,就不举例了。
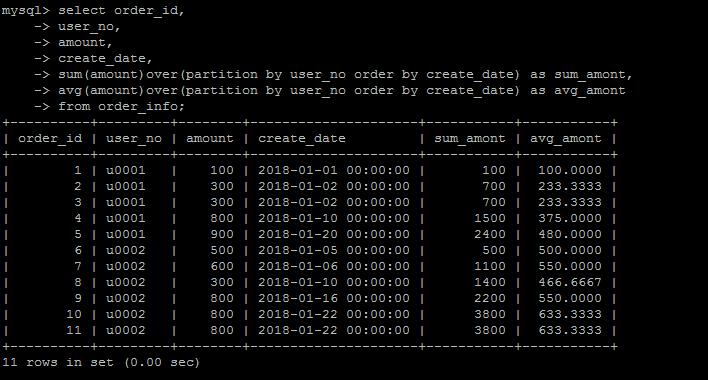
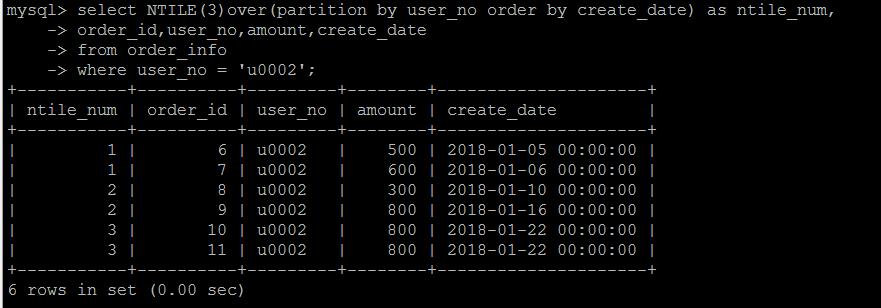
NTILE(N) 将数据按照某些排序分成N组
举个简单的例子,按照分数线的倒序排列,将学生成绩分成上中下3组,可以得到哪个程序数据上中下三个组中哪一部分,就可以使用NTILE(3) 来实现。这种需求倒是用的不是非常多。
如下还是使用上面的表,按照时间将user_no = \'u0002\'的订单按照时间的纬度,划分为3组,看每一行数据数据哪一组。
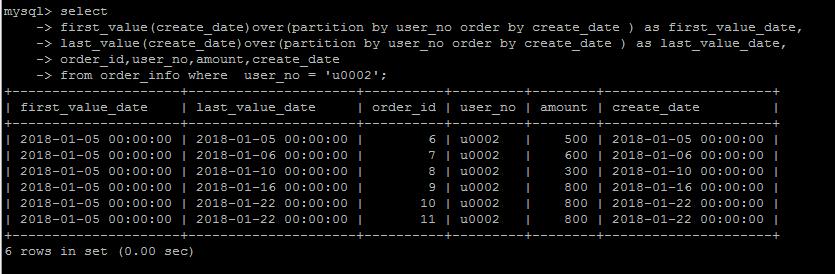
first_value(column_name) and last_value(column_name)
first_value和last_value基本上见名知意了,就是取某一组数据,按照某种方式排序的,最早的和最新的某一个字段的值。
看结果体会一下。
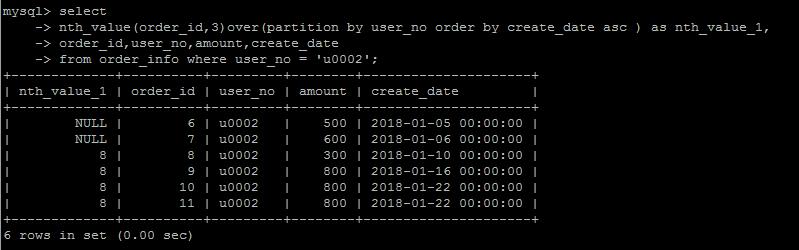
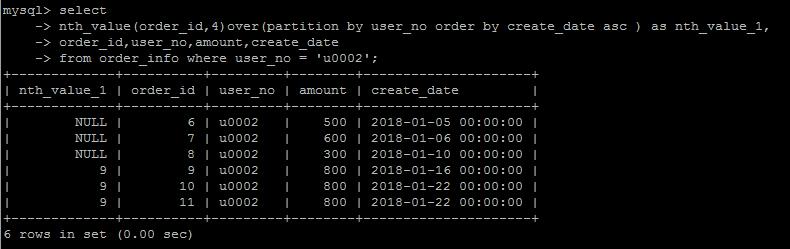
nth_value(column_name,n)
从排序的第n行还是返回nth_value字段中的值,这个函数用的不多,要表达的这种逻辑,说实话,很难用语言表达出来,看个例子体会一下就行。
n = 3
n = 4
cume_dist
在某种排序条件下,小于等于当前行值的行数/总行数,得到的是数据在某一个纬度的分布百分比情况。
比如如下示例
第1行数据的日期(create_date)是2018-01-05 00:00:00,小于等于2018-01-05 00:00:00的数据是1行,计算方式是:1/6 = 0.166666666
第2行数据的日期(create_date)是2018-01-06 00:00:00,小于等于2018-01-06 00:00:00的数据是2行,计算方式是:2/6 = 0.333333333
依次类推
第4行数据的日期(create_date)是2018-01-16 00:00:00,小于等于2018-01-16 00:00:00的数据是4行,计算方式是:4/6 = 0.6666666666
第一行数据的0.6666666666 意味着,小于第四行日期(create_date)的数据占了符合条件数据的66.66666666666%

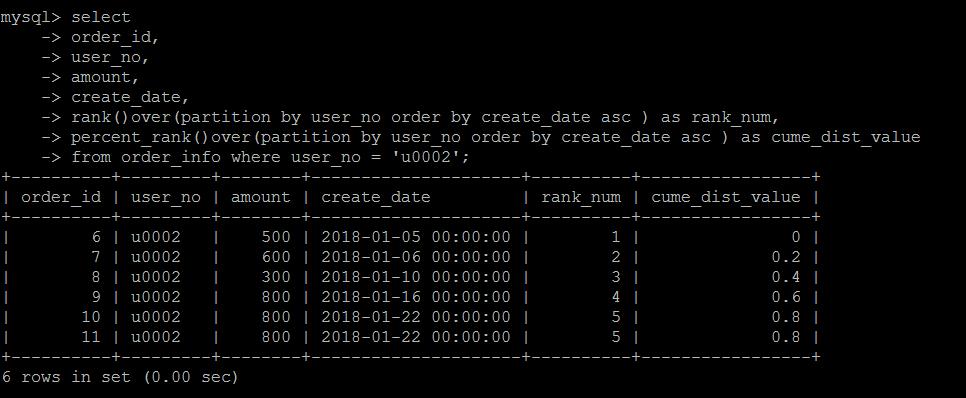
percent_rank()
同样是数据分布的计算方式,只不过算法变成了:当前RANK值-1/总行数-1 。
具体算法不细说,这个实际中用的也不多。
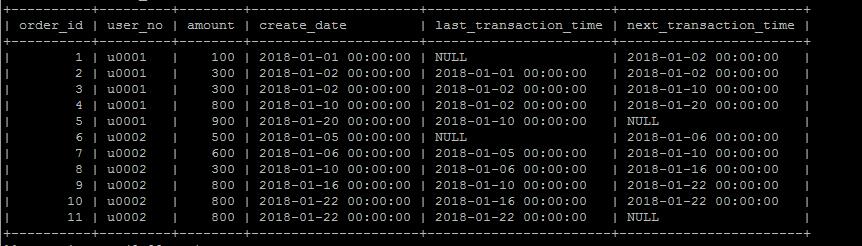
lag以及lead
lag(column,n)获取当前数据行按照某种排序规则的上n行数据的某个字段,lead(column,n)获取当前数据行按照某种排序规则的下n行数据的某个字段,确实很拗口。
举个实际例子,按照时间排序,获取当前订单的上一笔订单发生时间和下一笔订单发生时间,(可以计算订单的时间上的间隔度或者说买买买的频繁程度)
select order_id, user_no, amount, create_date, lag(create_date,1) over (partition by user_no order by create_date asc) \'last_transaction_time\', lead(create_date,1) over (partition by user_no order by create_date asc) \'next_transaction_time\' from order_info ;
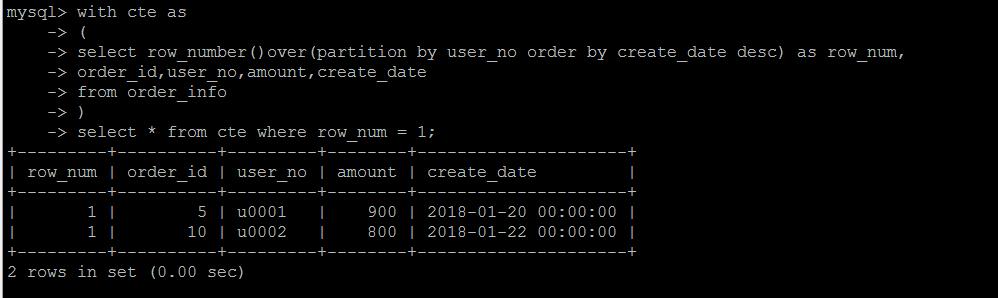
CTE 通用表表达式
CTE有两种用法,非递归的CTE和递归的CTE。
非递归的CTE可以用来增加代码的可读性,增加逻辑的结构化表达。
平时我们比较痛恨一句sql几十行甚至上上百行,根本不知道其要表达什么,难以理解,对于这种SQL,可以使用CTE分段解决,
比如逻辑块A做成一个CTE,逻辑块B做成一个CTE,然后在逻辑块A和逻辑块B的基础上继续进行查询,这样与直接一句代码实现整个查询,逻辑上就变得相对清晰直观。
举个简单的例子,当然这里也不足以说明问题,比如还是第一个需求,查询每个用户的最新一条订单
第一步是对用户的订单按照时间排序编号,做成一个CTE,第二步对上面的CTE查询,取行号等于1的数据。
另外一种是递归的CTE,递归的话,应用的场景也比较多,比如查询大部门下的子部门,每一个子部门下面的子部门等等,就需要使用递归的方式。
这里不做细节演示,仅演示一种递归的用法,用递归的方式生成连续日期。
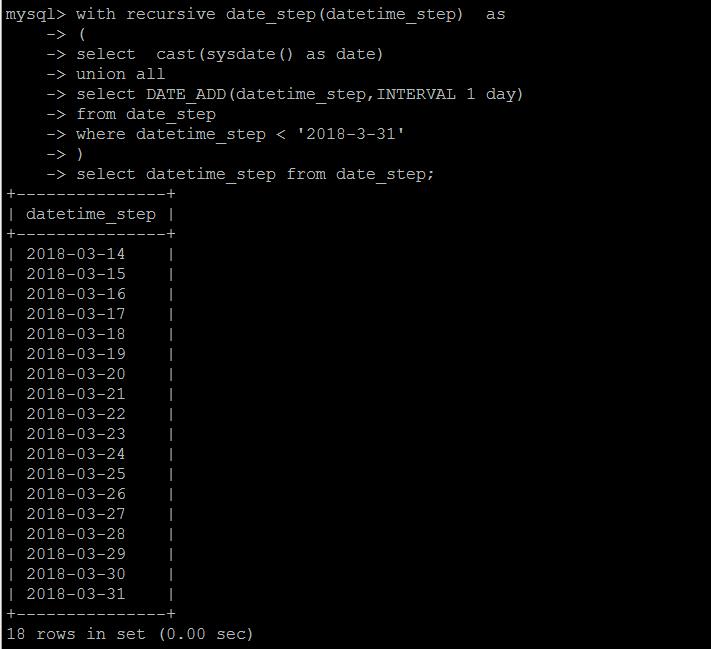
当然递归不会无限下去,不同的数据库有不同的递归限制,MySQL 8.0中默认限制的最大递归次数是1000。
超过最大低估次数会报错:Recursive query aborted after 1001 iterations. Try increasing @@cte_max_recursion_depth to a larger value.
由参数@@cte_max_recursion_depth决定。
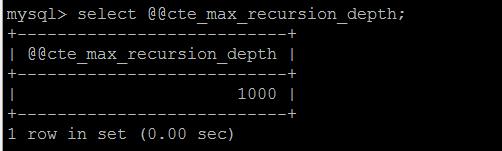
关于CTE的限制,跟其他数据库并无太大差异,比如CTE内部的查询结果都要有字段名称,不允许连续对一个CTE多次查询等等,相信熟悉CTE的老司机都很清楚。
窗口函数和CTE的增加,简化了SQL代码的编写和逻辑的实现,并不是说没有这些新的特性,这些功能都无法实现,只是新特性的增加,可以用更优雅和可读性的方式来写SQL。
不过这都是在MySQL 8.0中实现的新功能,在8.0之前,还是老老实实按照较为复杂的方式实现吧。
Primary key restrict
参数sql_require_primary_key控制
普通表和临时表都会被限制
删除当前主键报错(除非同时新建主键),即便已有NOT NULL UK也报错
导入无主键表报错
并行复制writeset机制
5.7的并行复制效率,取决于事务在主库上的并发度。如果主库上并发度不高,或者有大事务,则从库延迟依然比较严重
8.0的writeset模式完美解决了这个难题:即便在主库是串行提交,但只要事务间不冲突,在从库依然可以并行回放
MySQL 8.0 中引入参数 binlog_transaction_depandency_tracking 用于控制如何决定事务的依赖关系。该值有三个选项:默认的 COMMIT_ORDERE表示继续使用5.7中的基于组提交的方式决定事务的依赖关系;WRITESET 表示使用写集合来决定事务的依赖关系,基于主键的并发策略,可以并发的执行同一个session内的事务;还有一个选项 WRITESET_SESSION 表示使用 WriteSet 来决定事务的依赖关系,基于主键的并发策略,但是同一个Session内的事务不会有相同的 last_committed 值,不可以并发执行同一个session内的事务。
WriteSet 是通过检测两个事务是否更新了相同的记录来判断事务能否并行回放的,因此需要在运行时保存已经提交的事务信息以记录历史事务更新了哪些行。记录历史事务的参数为 binlog_transaction_dependency_history_size. 该值越大可以记录更多的已经提交的事务信息,不过需要注意的是,这个值并非指事务大小,而是指追踪的事务更新信息的数量。
从 MySQL Hight Availability 的测试中可以看到,开启了基于 WriteSet 的事务依赖后,对Slave上RelayLog回放速度提升显著。Slave上的 RelayLog 回放速度将不再依赖于 Master 上提交时的并行程度,使得Slave上可以发挥其最大的吞吐能力, 这个特性在Slave上复制停止一段时间后恢复复制时尤其有效。
这个特性使得 Slave 上可能拥有比 Master 上更大的吞吐量,同时可能在保证事务依赖关系的情况下,在 Slave 上产生 Master 上没有产生过的提交场景,事务的提交顺序可能会在 Slave 上发生改变。 虽然在5.7 的并行复制中就可能发生这种情况,不过在8.0中由于 Slave 上更高的并发能力,会使该场景更加常见。 通常情况下这不是什么大问题,不过如果在 Slave 上做基于 Binlog 的增量备份,可能就需要保证在 Slave 上与Master 上一致的提交顺序,这种情况下可以开启 slave_preserve_commit_order 这是一个 5.7 就引入的参数,可以保证 Slave 上并行回放的线程按 RelayLog 中写入的顺序 Commit。
8.0.14后新特性
双密码机制
从MySQL8.0.14开始,允许用户账户拥有双密码,指定为主密码和辅助密码
mysql>create user root@\'%\' identified by \'123456\'; mysql>grant all privileges on *.* to root@\'%\'; 创建新密码 mysql>alter user root@\'%\' identified by \'root\' RETAIN CURRENT PASSWORD; 丢弃旧密码: mysql>alter user root@\'%\' DISCARD OLD PASSWORD;
Binary log 加密机制,属于安全机制方面
redo & undo 日志加密
增加以下两个参数,用于控制redo、undo日志的加密。
innodb_undo_log_encrypt
innodb_undo_log_encrypt
log_slow_extra
mysql> SET GLOBAL log_slow_extra=1;
log_slow_extra 慢日志参数,提供了更详细的内容
admin_port
使用的端口默认为33062, 由admin_port来设置
mysql> show variables like \'admin_%\'; +---------------+---------------+ | Variable_name | Value | +---------------+---------------+ | admin_address | 192.168.1.101 | | admin_port | 33062 | +---------------+---------------+ 2 rows in set (0.00 sec)
默认字符集由latin1变为utf8mb4
在8.0版本之前,默认字符集为latin1,utf8指向的是utf8mb3,8.0版本默认字符集为utf8mb4,utf8默认指向的也是utf8mb4
group by 不再隐式排序
mysql 8.0 对于group by 字段不再隐式排序,如需要排序,必须显式加上order by 子句
# 表结构 mysql> show create table tb1\\G *************************** 1. row *************************** Table: tb1 Create Table: CREATE TABLE `tb1` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(50) DEFAULT NULL, `group_own` int(11) DEFAULT \'0\', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci ROW_FORMAT=DYNAMIC 1 row in set (0.00 sec) # 表数据 mysql> select * from tb1; +----+------+-----------+ | id | name | group_own | +----+------+-----------+ | 1 | 1 | 0 | | 2 | 2 | 0 | | 3 | 3 | 0 | | 4 | 4 | 0 | | 5 | 5 | 5 | | 8 | 8 | 1 | | 10 | 10 | 5 | +----+------+-----------+ 7 rows in set (0.00 sec) # MySQL 5.7 mysql> select count(id), group_own from tb1 group by group_own; +-----------+-----------+ | count(id) | group_own | +-----------+-----------+ | 4 | 0 | | 1 | 1 | | 2 | 5 | +-----------+-----------+ 3 rows in set (0.00 sec) # MySQL 8.0.11 mysql> select count(id), group_own from tb1 group by group_own; +-----------+-----------+ | count(id) | group_own | +-----------+-----------+ | 4 | 0 | | 2 | 5 | | 1 | 1 | +-----------+-----------+ 3 rows in set (0.00 sec) # MySQL 8.0.11显式地加上order by进行排序 mysql> select count(id), group_own from tb1 group by group_own order by group_own; +-----------+-----------+ | count(id) | group_own | +-----------+-----------+ | 4 | 0 | | 1 | 1 | | 2 | 5 | +-----------+-----------+ 3 rows in set (0.00 sec)
JSON特性增强
MySQL 8 大幅改进了对 JSON 的支持,添加了基于路径查询参数从 JSON 字段中抽取数据的 JSON_EXTRACT() 函数,以及用于将数据分别组合到 JSON 数组和对象中的 JSON_ARRAYAGG() 和 JSON_OBJECTAGG() 聚合函数。
在主从复制中,新增参数 binlog_row_value_options,控制JSON数据的传输方式,允许对于Json类型部分修改,在binlog中只记录修改的部分,减少json大数据在只有少量修改的情况下,对资源的占用。
8.0几个特殊参数
log_error_verbosity=3 innodb_print_ddl_logs=1 binlog_expire_logs_seconds=86400 innodb-undo-tablespaces=10 innodb-undo-directory=undolog
转自
MySQL8.0新特性实验1 - AllenHU320 - 博客园
https://www.cnblogs.com/allenhu320/p/11551010.html
以上是关于MySQL8.0新特性的主要内容,如果未能解决你的问题,请参考以下文章