HADOOP HA部署
Posted hyh123
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HADOOP HA部署相关的知识,希望对你有一定的参考价值。
本次部署haddoop集群三台hostname:HBASE01 HBASE02 HBASE03
192.168.240.129 HBASE01 192.168.240.130 HBASE02 192.168.240.131 HBASE03
将HBASE01 HBASE02作为namenode节点,HBASE01、HBASE02、HBASE03作为datanode节点
一、 namenode ha配置
1.hdfs-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/data/hadoop/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/data/hadoop/hdfs/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.block.size</name>
<value>134217728</value>
</property>
<property>
<name>dfs.datanode.max.xcievers</name>
<value>4096</value>
</property>
<property>
<name>dfs.support.append</name>
<value>true</value>
</property>
<property>
<name>dfs.hosts</name>
<value>/usr/local/hadoop/etc/hadoop/dfs.hosts</value>
</property>
<property>
<name>dfs.hosts.exclude</name>
<value>/usr/local/hadoop/etc/hadoop/dfs.hosts.exclude</value>
</property>
<!-- HA hadoop2 -->
<!-- hdfs nn的逻辑名称 -->
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<!-- 给定服务逻辑名称ns1的节点列表,如果有第二个则加nn2,逗号分隔-->
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<!-- #ns1中nn1节点对外服务的RPC地址-->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>HBASE01:9000</value>
</property>
<!-- ns1中nn1节点对外服务的http地址-->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>HBASE01:50070</value>
</property>
<!-- #ns1中nn2节点对外服务的RPC地址-->
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>HBASE02:9000</value>
</property>
<!-- ns1中nn2节点对外服务的http地址-->
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>HBASE02:50070</value>
</property>
<!-- 如果有多台,做namenode备份
<property>
<name>dfs.namenode.rpc-address.ns1.nn3</name>
<value>域名2:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1.nn3</name>
<value>域名2:50070</value>
</property>
-->
<!--
设置一组journalNode的URL日志,active ns将editlog写入这些JournalNode
HBASE01:8485;HBASE02:8485/ns1-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://HBASE01:8485;HBASE02:8485/ns1</value>
</property>
<!-- 声明journalnode服务器存储目录-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/data/hadoop/hdfs/journal</value>
</property>
<!-- 访问代理类:client,mycluster,active配置失败自动切换实现方式-->
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh无秘钥登录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
2.core-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<!-- ha hadoop2
-->
#zk服务节点多个域名用,分隔,域名1:2181,域名2:2181...
<property>
<name>ha.zookeeper.quorum</name>
<value>HBASE01:2181,HBASE02:2181,HBASE03:2181</value>
</property>
#逻辑服务名,需与hdfs-site.xml中的dfs.nameservices一致
<property>
<name>fs.defaultFS</name>
<value>hdfs://HBASE01:9000</value>
</property>
<property>
<name>hadoop.security.group.mapping</name>
<value>org.apache.hadoop.security.ShellBasedUnixGroupsMapping</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
3.slaves
配置datanode位置:
HBASE01 HBASE02 HBASE03
二、 namenode ha启动
1.启动三台服务器的zookeeper
#./zkServer.sh start
2.启动HBASE01和HBASE02的jounalnode服务
# sbin/hadoop-daemon.sh start journalnode

3.分别启动HBASE01和HBASE02的namenode服务
①先格式化HBASE01的namenode
# bin/hdfs namenode -format
② 启动HBASE01的namenode
#sbin/hadoop-daemon.sh start namenode
③ HBASE02同步HBASE01的namenode
#bin/hdfs namenode –bootstrapStandby
④ 启动HBASE02的namenode
# sbin/hadoop-daemon.sh start namenode
4.namenode都启动完成后,这时两台的namenode都是 standby模式,需要切换其中一台为active模式
①将HBASE01的namenode切换成active,需强制切换
# bin/hdfs haadmin -transitionToActive --forcemanual nn1
②查看namenode模式
# bin/hdfs haadmin -getServiceState nn1 # bin/hdfs haadmin -getServiceState nn2
5.zookeeper配置故障自动切换namenode
# bin/hdfs zkfc –formatZK
查看zookeeper中节点,多了hadoop-ha

6.启动集群
# sbin/start-dfs.sh
①HBASE01
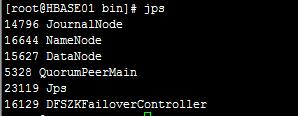
②HBASE02
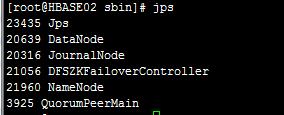
③HBASE03
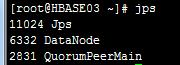
三、 故障测试

1.kill掉HBASE01的namenode
# kill 16644
2.查看namenode状态
# bin/hdfs haadmin -getServiceState nn1 # bin/hdfs haadmin -getServiceState nn2

这时nn1连接不上,nn2为active状态
3.重新启动HBASE01的namenode
# bin/hdfs namenode –bootstrapStandby # sbin/hadoop-daemon.sh start namenode
可以先进行下namenode的同步,再启动,也可以直接启动
4、查看HBASE01,HBASE02 namenode状态

5、kill掉HBASE02的namenode,同样 HBASE01的namenode也能转换成active状态
HADOOP NAMENODE HA 部署完成 !
以上是关于HADOOP HA部署的主要内容,如果未能解决你的问题,请参考以下文章