MongoDB 使用B树
Posted 林锅技术园
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MongoDB 使用B树相关的知识,希望对你有一定的参考价值。
概述
MongoDB 是一个通用的、面向文档的分布式数据库[^1],这是官方对 MongoDB 介绍。区别于传统的关系型数据库 mysql、Oracle 和 SQL Server,MongoDB 最重要的一个特点就是『面向文档』,由于数据存储方式的不同,对外提供的接口不再是被大家熟知的 SQL,所以被划分成了 NoSQL,NoSQL 是相对 SQL 而言的,很多我们耳熟能详的存储系统都被划分成了 NoSQL,例如:Redis、DynamoDB[^2] 和 Elasticsearch 等。
NoSQL 经常被理解成没有 SQL(Non-SQL)或者非关系型(Non-Relational)[^3],不过也有人将其理解成不只是 SQL(Not Only SQL)[^4],深挖这个词的含义和起源可能没有太多意义,这种二次解读很多时候都是为营销服务的,我们只需要知道 MongoDB 对数据的存储方式与传统的关系型数据库完全不同。
MongoDB 的架构与 MySQL 非常类似,它们底层都使用了可插拔的存储引擎以满足用户的不同需求,用户可以根据数据特征选择不同的存储引擎,最新版本的 MongoDB 使用了 WiredTiger 作为默认的存储引擎[^5]。
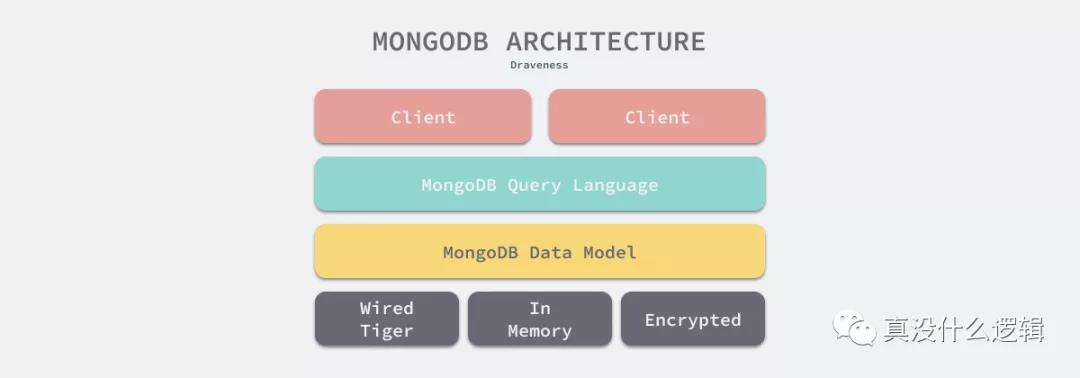
作为 MongoDB 默认的存储引擎,WiredTiger 使用 B 树作为索引底层的数据结构,但是除了 B 树之外,它还支持 LSM 树作为可选的底层存储结构,LSM 树的全称是 Log-structured merge-tree,你可以在 MongoDB 中使用如下所示的命令创建一个基于 LSM 树的集合(Collection)[^6]:
db.createCollection( "posts", { storageEngine: { wiredTiger: {configString: "type=lsm"}}} )
我们在这篇文章中不仅会介绍 MongoDB 的默认存储引擎 WiredTiger 为什么选择使用 B 树而不是 B+ 树,还会对 B 树和 LSM 树之间的性能和应用场景进行比较,帮助各位读者更全面地理解今天的问题。
设计
既然要比较两个不同数据结构与 B 树的差别,那么在这里我们将分两个小节分别介绍 B+ 树和 LSM 树为什么没有成为 WiredTiger 默认的数据结构:
- 作为非关系型的数据库,MongoDB 对于遍历数据的需求没有关系型数据库那么强,它追求的是读写单个记录的性能;
- 大多数 OLTP 的数据库面对的都是读多写少的场景,B 树与 LSM 树在该场景下有更大的优势;
上述的两个场景都是 MongoDB 需要面对和解决的,所以我们会在这两个常见场景下对不同的数据结构进行比较。
非关系型
我们在上面其实已经多次提到了 MongoDB 是非关系型的文档数据库,它完全抛弃了关系型数据库那一套体系之后,在设计和实现上就非常自由,它不再需要遵循 SQL 和关系型数据库的体系,可以更自由对特定场景进行优化,而在 MongoDB 假设的场景中遍历数据并不是常见的需求。
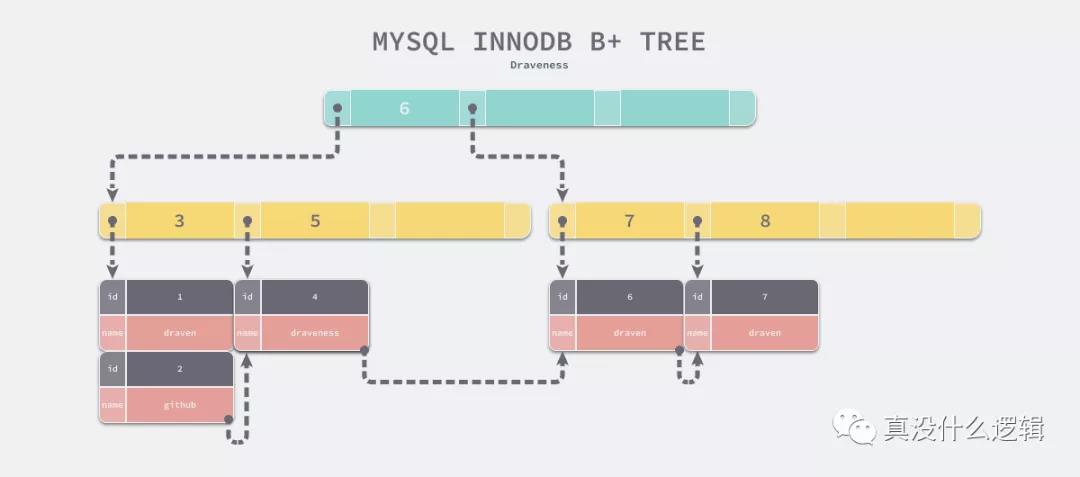
MySQL 中使用 B+ 树是因为 B+ 树只有叶节点会存储数据,将树中的每一个叶节点通过指针连接起来就能实现顺序遍历,而遍历数据在关系型数据库中非常常见,所以这么选择是完全没有问题的[^7]。
MongoDB 和 MySQL 在多个不同数据结构之间选择的最终目的就是减少查询需要的随机 IO 次数,MySQL 认为遍历数据的查询是常见的,所以它选择 B+ 树作为底层数据结构,而舍弃了通过非叶节点存储数据这一特性,但是 MongoDB 面对的问题就不太一样了:
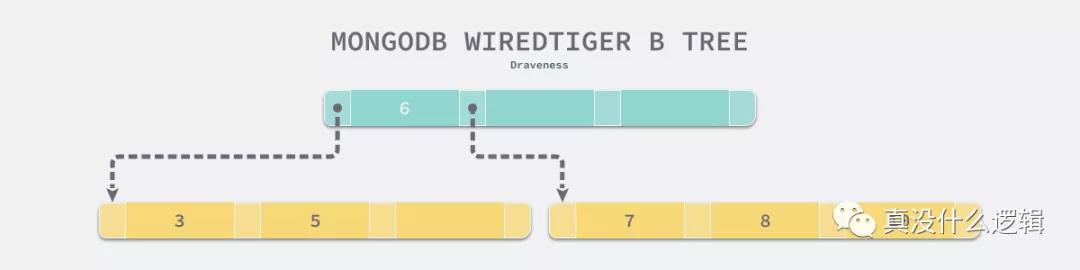
虽然遍历数据的查询是相对常见的,但是 MongoDB 认为查询单个数据记录远比遍历数据更加常见,由于 B 树的非叶结点也可以存储数据,所以查询一条数据所需要的平均随机 IO 次数会比 B+ 树少,使用 B 树的 MongoDB 在类似场景中的查询速度就会比 MySQL 快。这里并不是说 MongoDB 并不能对数据进行遍历,我们在 MongoDB 中也可以使用范围来查询一批满足对应条件的记录,只是需要的时间会比 MySQL 长一些。
SELECT * FROM comments WHERE created_at > \'2019-01-01\'
很多人看到遍历数据的查询想到的可能都是如上所示的范围查询,然而在关系型数据库中更常见的其实是如下所示的 SQL —— 查询外键或者某字段等于某一个值的全部记录:
SELECT * FROM comments WHERE post_id = 1
上述查询其实并不是范围查询,它没有使用 >、< 等表达式,但是它却会在 comments 表中查询一系列的记录,如果 comments 表上有索引 post_id,那么这个查询可能就会在索引中遍历相应索引,找到满足条件的 comment,这种查询也会受益于 MySQL B+ 树相互连接的叶节点,因为它能减少磁盘的随机 IO 次数。
MongoDB 作为非关系型的数据库,它从集合的设计上就使用了完全不同的方法,如果我们仍然使用传统的关系型数据库的表设计思路来思考 MongoDB 中集合的设计,写出类似如上所示的查询会带来相对比较差的性能:
db.comments.find( { post_id: 1 } )
因为 B 树的所有节点都能存储数据,各个连续的节点之间没有很好的办法通过指针相连,所以上述查询在 B 树中性能会比 B+ 树差很多,但是这并不是一个 MongoDB 中推荐的设计方法,更合适的做法其实是使用嵌入文档,将 post 和属于它的所有 comments 都存储到一起:
"_id": "...", "title": "为什么 MongoDB 使用 B 树", "author": "draven", "comments": [ { "_id": "...", "content": "你这写的不行" }, { "_id": "...", "content": "一楼说的对" } ] }
使用上述方式对数据进行存储时就不会遇到 db.comments.find( { post_id: 1 } ) 这样的查询了,我们只需要将 post 取出来就会获得相关的全部评论,这种区别于传统关系型数据库的设计方式是需要所有使用 MongoDB 的开发者重新思考的,这也是很多人使用 MongoDB 后却发现性能不如 MySQL 的最大原因 —— 使用的姿势不对。
有些读者到这里可能会有疑问了,既然 MongoDB 认为查询单个数据记录远比遍历数据的查询更加常见,那为什么不使用哈希作为底层的数据结构呢?

如果我们使用哈希,那么对于所有单条记录查询的复杂度都会是 O(1),但是遍历数据的复杂度就是 O(n);如果使用 B+ 树,那么单条记录查询的复杂度是 O(log n),遍历数据的复杂度就是 O(log n) + X,这两种不同的数据结构一种提供了最好的单记录查询性能,一种提供了最好的遍历数据的性能,但是这都不能满足 MongoDB 面对的场景 —— 单记录查询非常常见,但是对于遍历数据也需要有相对较好的性能支持,哈希这种性能表现较为极端的数据结构往往只能在简单、极端的场景下使用。
读多写少
LSM 树是一个基于磁盘的数据结构,它设计的主要目的是为长期需要高频率写入操作的文件提供低成本的索引机制[^8]。无论是 B 树还是 B+ 树,向这些数据结构组成的索引文件中写入记录都需要执行的磁盘随机写,LSM 树的优化逻辑就是牺牲部分的读性能,将随机写转换成顺序写以优化数据的写入。
我们在这篇文章不会详细介绍为什么 LSM 树有着较好的写入性能,我们只是来分析为什么 WiredTiger 使用 B 树作为默认的数据结构。WiredTiger 对 LSM 树和 B 树的性能进行了读写吞吐量的基准测试[^9],通过基准测试得到了如下图所示的结果,从图中的结果我们能发现:
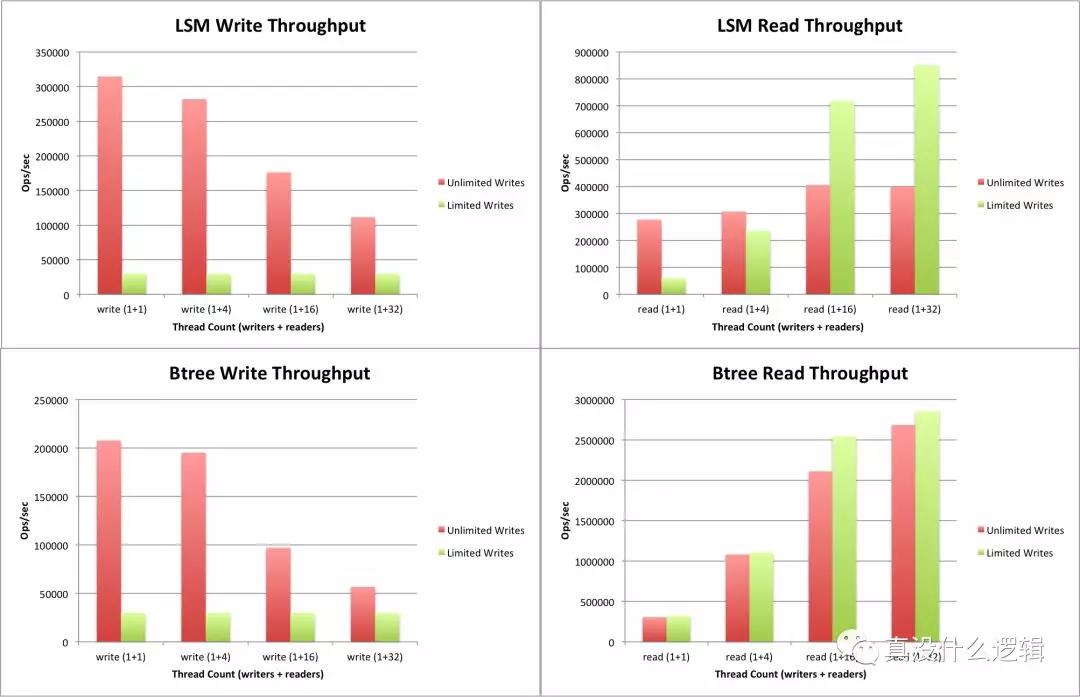
- 在不限制写入的情况下;
- LSM 树的写入性能是 B 树的 1.5 ~ 2 倍;
- LSM 树的读取性能是 B 树的 1/6 ~ 1/3;
- 在限制写入的情况下;
- LSM 树的写入性能与 B 树的性能基本持平;
- LSM 树的读取性能是 B 树的 1/4 ~ 1/2;
在限制写入的情况下,每秒会写入 30,000 条数据,从这里的分析结果来看,无论那种情况下 B 树的读取性能是远好于 LSM 树的。对于大多数的 OLTP 系统来说,系统的查询会是写的很多倍,所以 LSM 树在写入方面的优异表现也没有办法让它成为 MongoDB 默认的数据格式。
总结
应用场景永远都是系统设计时首先需要考虑的问题,作为 NoSQL 的 MongoDB,其目标场景就与更早的数据库就有着比较大的差异,我们来简单总结一下 MongoDB 最终选择使用 B 树的两个原因:
- MySQL 使用 B+ 树是因为数据的遍历在关系型数据库中非常常见,它经常需要处理各个表之间的关系并通过范围查询一些数据;但是 MongoDB 作为面向文档的数据库,与数据之间的关系相比,它更看重以文档为中心的组织方式,所以选择了查询单个文档性能较好的 B 树,这个选择对遍历数据的查询也可以保证可以接受的时延;
- LSM 树是一种专门用来优化写入的数据结构,它将随机写变成了顺序写显著地提高了写入性能,但是却牺牲了读的效率,这与大多数场景需要的特点是不匹配的,所以 MongoDB 最终还是选择读取性能更好的 B 树作为默认的数据结构;
到最后,我们还是来看一些比较开放的相关问题,有兴趣的读者可以仔细思考一下下面的问题:
- BigTable、LevelDB 和 HBase 的应用场景都是什么?它们的读写比例有多少?为什么使用 LSM 树作为底层的数据结构?
- 在设计表结构时,MongoDB 与传统的关系型数据库有哪些区别?
[^1]: MongoDB 官方网站 The database for modern applications https://www.mongodb.com/
[^2]: 分布式键值存储 Dynamo 的实现原理 https://draveness.me/dynamo
[^3]: NoSQL 维基百科 https://en.wikipedia.org/wiki/NoSQL
[^4]: NoSQL (Not Only SQL database) https://searchdatamanagement.techtarget.com/definition/NoSQL-Not-Only-SQL
[^5]: 『浅入浅出』MongoDB 和 WiredTiger https://draveness.me/mongodb-wiredtiger
[^6]: MongoDB 中的集合(Collection)与 MySQL 中的表(Table)是差不多的概念
[^7]: 为什么 MySQL 使用 B+ 树 · Why\'s THE Design? https://draveness.me/whys-the-design-mysql-b-plus-tree
[^8]: The Log-Structured Merge-Tree (LSM-Tree), Patrick O\'Neil, Edward Cheng, Dieter Gawlick, Elizabeth O\'Neil https://www.cs.umb.edu/~poneil/lsmtree.pdf
[^9]: Btree vs LSM https://github.com/wiredtiger/wiredtiger/wiki/Btree-vs-LSM
以上是关于MongoDB 使用B树的主要内容,如果未能解决你的问题,请参考以下文章