cmdb简介和入门
Posted chanyuli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了cmdb简介和入门相关的知识,希望对你有一定的参考价值。
CMDB项目必要性
在这之前了解一下传统运维工程师的工作
传统运维
- 日常工作繁琐
- 应用环境不统一
- 部署效率低下
- 无用报警信息过多
自动化运维就是为了解决传统运维的一些痛点
自动化运维
运维自动化最重要的就是标准化一切
自动化运维核心项目之CMDB
为什么要先做CMDB?
场景一
代码发布系统
项目从需求提出 —–》 项目上线的流程?
需求分析(产品经理) —> 开会分工(产品经理+开发+运维+测试) —> 代码的测试
(白盒、黑盒测试) —> 上线 (4台负载均衡 + 运维)
传统上线的方式
把代码打包发送给运维,运维解包放到服务器相对应的目录下
问题是,如果机?数量增到100台服务?,剩下的96台服务?,是不是都的要重复一下上面的代码部署步骤?
解决的办法: 如果能有一个web系统,能够自动的发布代码,那需要的最基本的东西就是:服务?的各种元信息(ip/主机名/cpu/硬盘大小/网卡信息)
- 场景二
服务器监控系统
监控的内容:项目的正常运行, 硬盘的大小(>80%), CPU的信息, 日志的分析报警(http的状态码 (200,304,400,404,500等)) 等内容
前提是做这个监控系统之前,我们是需要获取这些服务?的元信息的(ip/主机名/cpu/硬盘大小/网卡信息)
- 场景三
上市,需要审批资产,当时对服务?这块审批非常的麻烦,因为,之前他们将服务?的各种信息ip/主机名/cpu/硬盘大小/网卡信息)记录在了Excel里面 。汽车之家 —》1000台 (windowsServer—》linux)
CMDB系统
配置管理系统,作用是:自动采集服务?的各种元信息(ip/主机名/cpu/硬盘大小/网卡
信息),包括自动记录服务?的变更信息 。
项目架构图
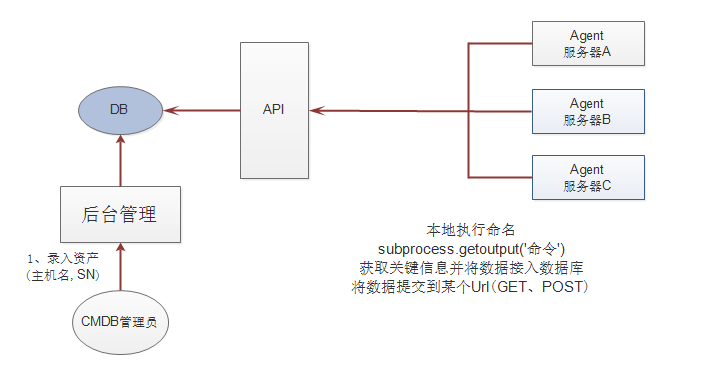
- 方案一 agent方案
服务?的信息怎么获取?(服务?的ip地址,主机名,硬盘大小怎么获取?)
答: 通过linux的各种命令来进行获取 (ifconfig获取ip地址)
如何通过python代码获取linux服务?的信息?(如何使用python代码执行linux命令?)
答:subprocess模块下的 getoutput 方法
如何将客户端执行产生的结果传送到对端的API上?
答:通过http协议的Post方法传输 采用requests模块下面的post方法
api获取数据,使用request.body获取,而不是用post获取,原因是啥?
答: request.post和get这两方法中的数据,是从body中获取的
如果你http的头信息:content-type: application/json 格式的话, request.post或
者get都获取不到信息,只能使用body获取。
如果 content-type:application/form-url-encode格式的话, request.post中就会有
数据
缺点: 每一台服务?都是需要部署相同的项目和脚本,部署起来比较的麻烦
- 方案二 ssh类方案
中控机上安装paramiko模块,通过ssh协议登录每一台服务?进行采集信息相对于第一套方案来说,
优点: 不需要每一台都部署
缺点: 速度慢 ,每台都要连接,耗时高
服务器数量较少的情况下可以用这种方法。
import paramiko
# 创建SSH对象
ssh = paramiko.SSHClient()
# 允许连接不在know_hosts文件中的主机
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
# 连接服务器
ssh.connect(hostname='c1.salt.com', port=22, username='root', password='123')
# 执行命令
stdin, stdout, stderr = ssh.exec_command('df')
# 获取命令结果
result = stdout.read()
# 关闭连接
ssh.close()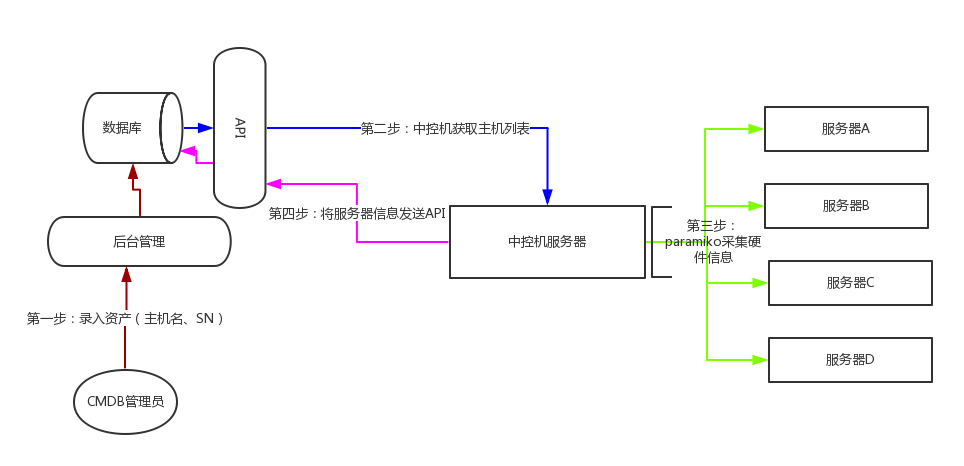
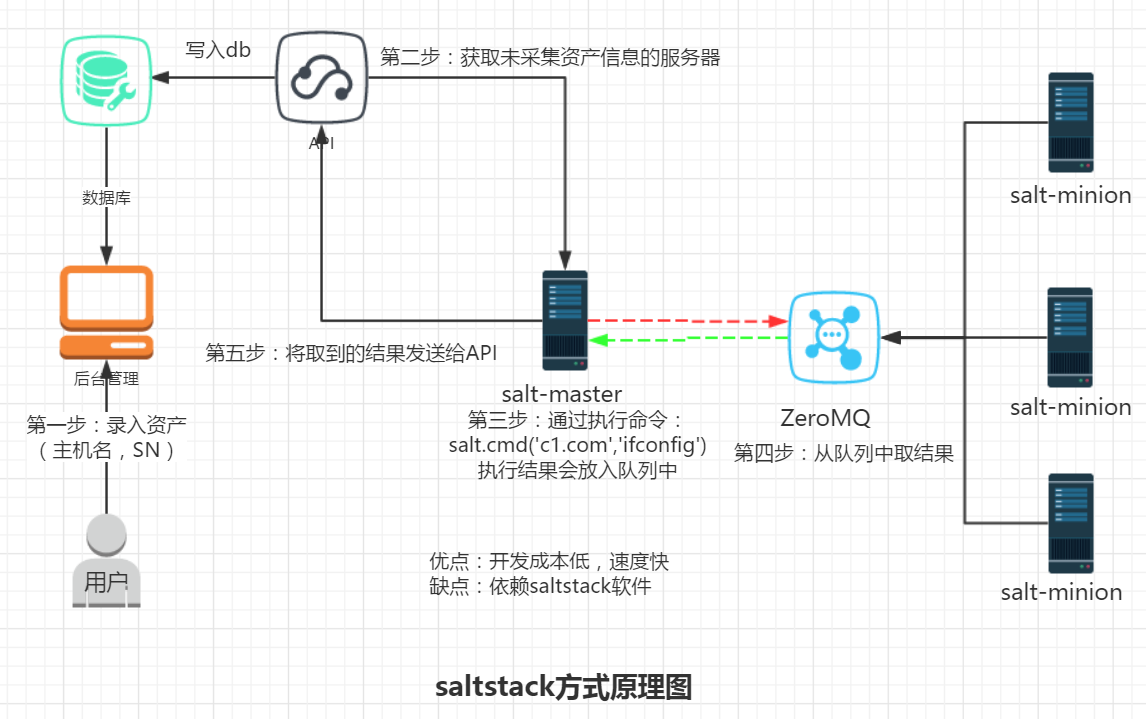
- 方案三 saltstack方案
中控机上安装salt-master,通过队列将命令传输给salt-minion执行,然后salt-minion将 执行完成之后的结果返回给salt-master
此方案本质上和第二种方案大致是差不多的流程,中控机发送命令给服务器执行。服务器将结果放入另一个队列中,中控机获取将服务信息发送到API进而录入数据库。
这里的两个队列不是同一个,一个用来放命令,一个用来放结果
优点:不需要写太多的代码
缺点:需要安装
- 方案四 puppet 方案
Ruby语言 (日本人)
总结
三套方案,总共都是分成三部分的
1、采集部分
2、API分析数据部分
3、djangoweb展示部分
三套方案,不一样的部分就是采集部分
所以,接下来我们要实现三套方案所有的采集部分
目标:
写一套客户端采集代码,通过一个配置选项来灵活的切换方案
客户端目录结构设计
bin : 整个项目的可执行文件
src: 整个项目的源文件
conf: 整个项目的配置目录
lib: 整个项目的库文件
tests: 测试文件放置的目录
log日志是要记录在一个特定的目录下的,比如说:/var/logs
功能实现:高级配置文件实现
一般,比如django,都是有两个配置文件的,一个是普通配置文件,用来自定义一些配置的,还有一个就是高级配置文件,放的一般都是不怎么改动的配置信息。现在手动实现一下两个配置文件都读取
from . import global_settings #集成高级配置文件
from conf import config #集成用户自定制配置
class Settings():
def __init__(self):
#### 集成高级配置
#dir方法获取这个文件的名称空间里所有东西,循环遍历,大写的就是我们要的配置
for k in dir(global_settings):
if k.isupper():
v = getattr(global_settings, k)
setattr(self, k, v)
#### 集成用户自定制配置
for k in dir(config):
if k.isupper():
v = getattr(config, k)
setattr(self, k, v)
settings = Settings()需要注意的是,高级配置一定要放在上面,因为如果他放在用户自定制配置下面,那么可能无论用户自定制了什么配置,读取的都是高级配置,会被覆盖,所以要厚读取用户自定制配置,遇到相同的配置信息,就覆盖高级配置。
以上是关于cmdb简介和入门的主要内容,如果未能解决你的问题,请参考以下文章